互联网系统设计 - Redis与缓存
前言
- redis有哪些使用场景?
- redis五种数据结构选择以及其底层实现原理?string、hashmap、list、set、zset
- redis 常用命令以及时间复杂度?
- 如何处理可能遇到的key大面积失效的缓存雪崩,无效key缓存穿透、热key缓存击穿问题?是否需要缓存预热
- 如何考虑缓存和数据库一致性的问题?更新DB之后删除缓存?还是更新缓存?
- redis 数据持久化是怎么做的?RDB和AOF机制?
- redis 分布式架构,codis,rdis cluster?
- redis 超过使用容量时的内存淘汰策略
- redis 过期键的删除策略
- redis 的单线程架构为什么快,有哪些优势和缺点?
- redis & Lua ?
- redis 性能调优?避免大key、热key导致集群倾斜,比秒复杂命令的使用,CPU、内存、宽带的监控
- 实践:秒杀系统的设计和实现
- 实践:分布式锁,setnx,expire,del
- 实践:bloomfilter 和 bitmap
- 实线:使用redis实现微信步数排行榜
redis 使用场景
缓存数据(db,service) 的数据,提高访问效率
- 缓存容量评估
- 缓存过期机制,时间
- 缓存miss,溯源和监控
- 缓存雪崩,大面积key失效DB保护。
- 缓存击穿:热key击穿保护
- 缓存穿透:无效key击穿DB保护
- 缓存更新和一致性问题
- 缓存热key和大key问题
限流和计数。lua脚本
- 计数器 (临界值和frozen)
- token (常用)
- 漏桶(平滑)
- 基于redis的分布式限流:https://pandaychen.github.io/2020/09/21/A-DISTRIBUTE-GOREDIS-RATELIMITER-ANALYSIS/
- https://blog.csdn.net/crazymakercircle/article/details/130035504
延时队列
- 使用 ZSET+ 定时轮询的方式实现延时队列机制,任务集合记为 taskGroupKey
- 生成任务以 当前时间戳 与 延时时间 相加后得到任务真正的触发时间,记为 time1,任务的 uuid 即为 taskid,当前时间戳记为 curTime
- 使用 ZADD taskGroupKey time1 taskid 将任务写入 ZSET
- 主逻辑不断以轮询方式 ZRANGE taskGroupKey curTime MAXTIME withscores 获取 [curTime,MAXTIME) 之间的任务,记为已经到期的延时任务(集)
- 处理延时任务,处理完成后删除即可
- 保存当前时间戳 curTime,作为下一次轮询时的 ZRANGE 指令的范围起点
- https://github.com/bitleak/lmstfy
消息队列
- redis 支持 List 数据结构,有时也会充当消息队列。使用生产者:LPUSH;消费者:RBPOP 或 RPOP 模拟队列
bloomfilter: https://juejin.cn/post/6844903862072000526
$m = -\frac{nln(p)}{(ln2)^2}$
$k=\frac{m}{n}ln(2)$
1
2
3
4n 是预期插入的元素数量(数据规模),例如 20,000,000。
p 是预期的误判率,例如 0.001。
m 是位数组的大小。
k 是哈希函数的数量。
redis 5种数据类型和底层数据结构
- [面试:原来Redis的五种数据类型底层结构是这样的]https://juejin.cn/post/6844904192042074126#heading-8
- 最详细的Redis五种数据结构详解
计算所需的缓存的容量,当容量超过限制时的淘汰策略
1 | - noeviction(默认策略):对于写请求不再提供服务,直接返回错误(DEL请求和部分特殊请求除外) |
redis 过期键的删除策略
过期策略通常有以下三种:
- 定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
- 惰性过期:只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
- 定期过期:每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
(expires字典会保存所有设置了过期时间的key的过期时间数据,其中,key是指向键空间中的某个键的指针,value是该键的毫秒精度的UNIX时间戳表示的过期时间。键空间是指该Redis集群中保存的所有键。)
redis 两种数据持久化的原理以及优缺点
- AOF: AOF持久化(即Append Only File持久化),文本日志,记录增删改
- RDB: 是Redis DataBase缩写快照,紧凑的二进制数据
- [Redis持久化是如何做的?RDB和AOF对比分析] (http://kaito-kidd.com/2020/06/29/redis-persistence-rdb-aof/)
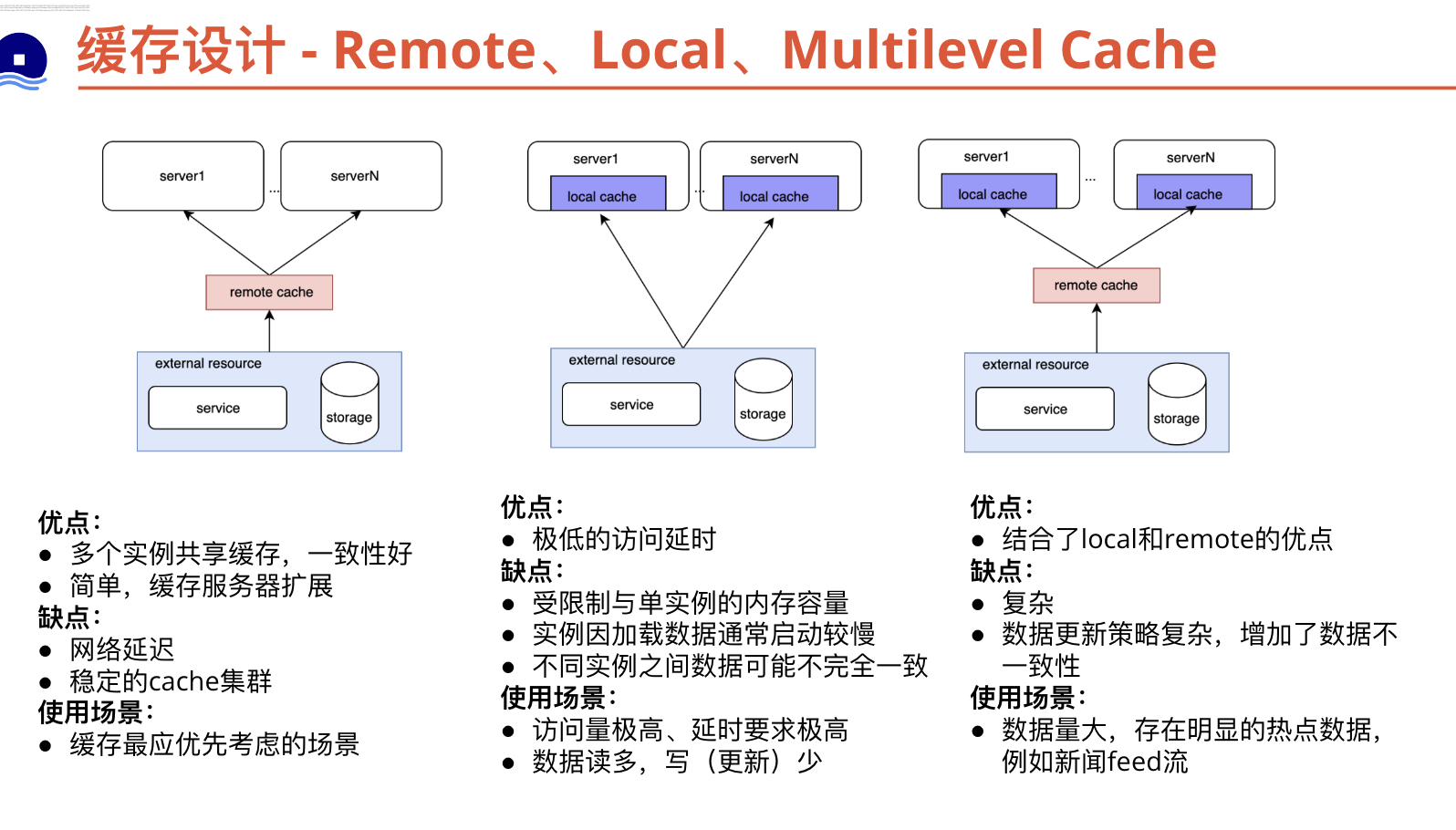
选择local、remote、multilevel cache
双buffer vs LRU/LFU
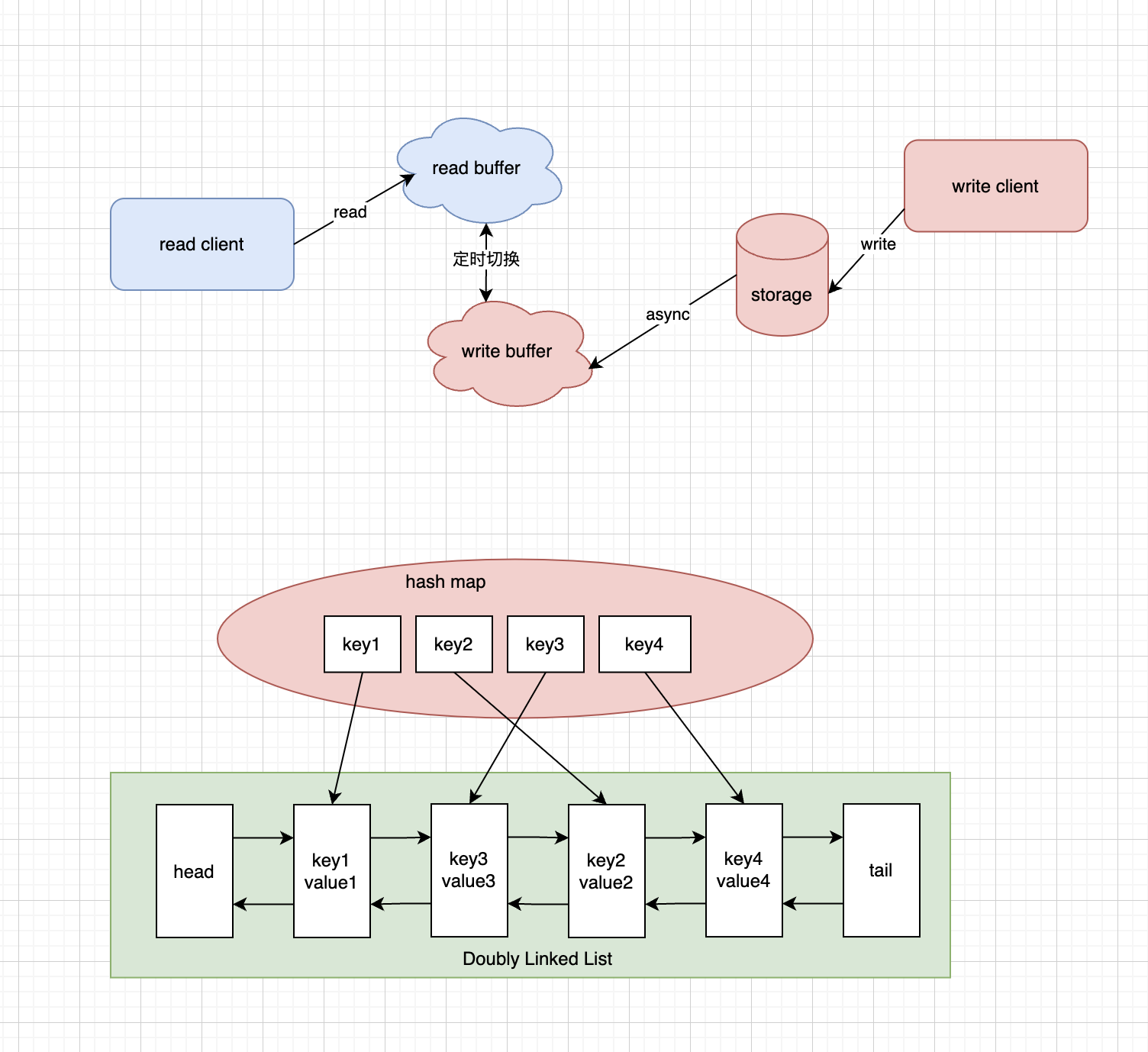
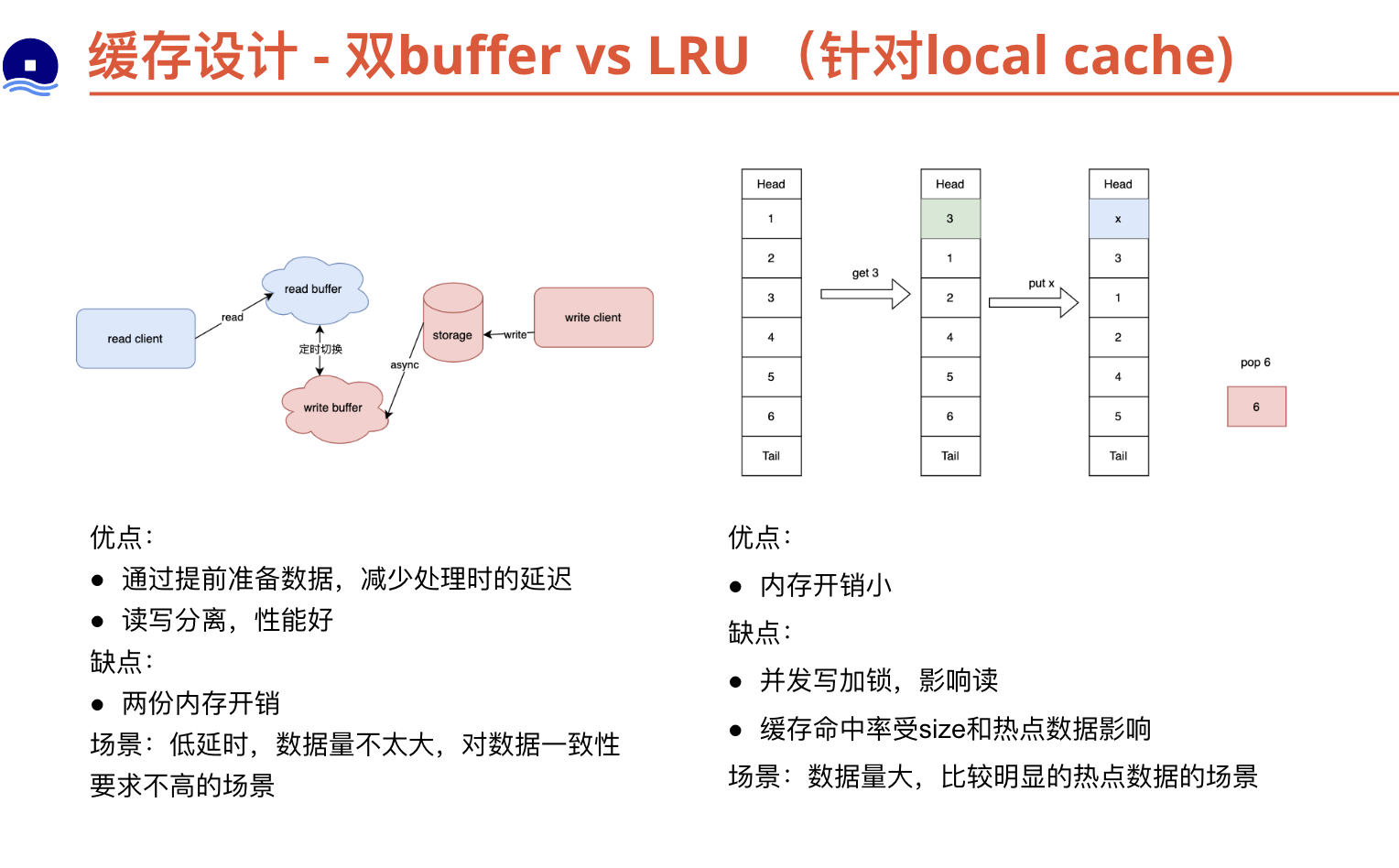
本地缓存的双缓冲机制和本地LRU(Least Recently Used)算法都是常见的缓存优化技术,它们具有不同的优点和缺点。
双缓冲机制:
- 优点:
- 提高并发性能:双缓冲机制使用两个缓冲区,一个用于读取数据,另一个用于写入数据。这样可以避免读写冲突,提高了并发性能。
- 提高数据访问效率:由于读取操作不会直接访问主缓存,而是读取缓冲区的数据,因此可以更快地获取数据。
- 缺点:
- 内存开销增加:双缓冲机制需要维护两个缓冲区,这会增加内存开销。
- 数据延迟:数据更新定时同步,有一定延时。
- 优点:
本地LRU算法:
- 优点:
- 数据访问效率高:LRU算法根据数据的访问顺序进行缓存替换,将最近最少使用的数据淘汰出缓存。这样可以保留最常用的数据,提高数据的访问效率。
- 简单有效:LRU算法的实现相对简单,只需要维护一个访问顺序链表和一个哈希表即可。
- 缺点:
- 缓存命中率下降:如果数据的访问模式不符合LRU算法的假设,即最近访问的数据在未来也是最有可能被访问的,那么LRU算法的效果可能不理想,缓存命中率会下降。
- 对于热点数据不敏感:LRU算法只考虑了最近的访问情况,对于热点数据(频繁访问的数据)可能无法有效地保留在缓存中。
- 优点:
综合来看,双缓冲机制适用于需要提高并发性能、批量更新等场景,但会增加内存开销。本地LRU算法适用于需要提高数据访问效率的场景,但对于访问模式不符合LRU假设的情况下,缓存命中率可能下降。在实际应用中,可以根据具体需求和场景选择适合的缓存优化技术。
怎么考虑缓存和db数据一致性的问题
- 当使用redis缓存db数据时,db数据会发生update,如何考虑redis和db数据的一致性问题呢?
- 通常来说,对于流量较小的业务来说,可以设置较小的expire time,可以将redis和db的不一致的时间控制在一定的范围内部
- 对于缓存和db一致性要求较高的场合,通常采用的是先更新db,再删除或者更新redis,考虑到并发性和两个操作的原子性(删除或者更新可能会失败),可以增加重试机制(双删除),如果考虑主从延时,可以引入mq做延时双删
- http://kaito-kidd.com/2021/09/08/how-to-keep-cache-and-consistency-of-db/
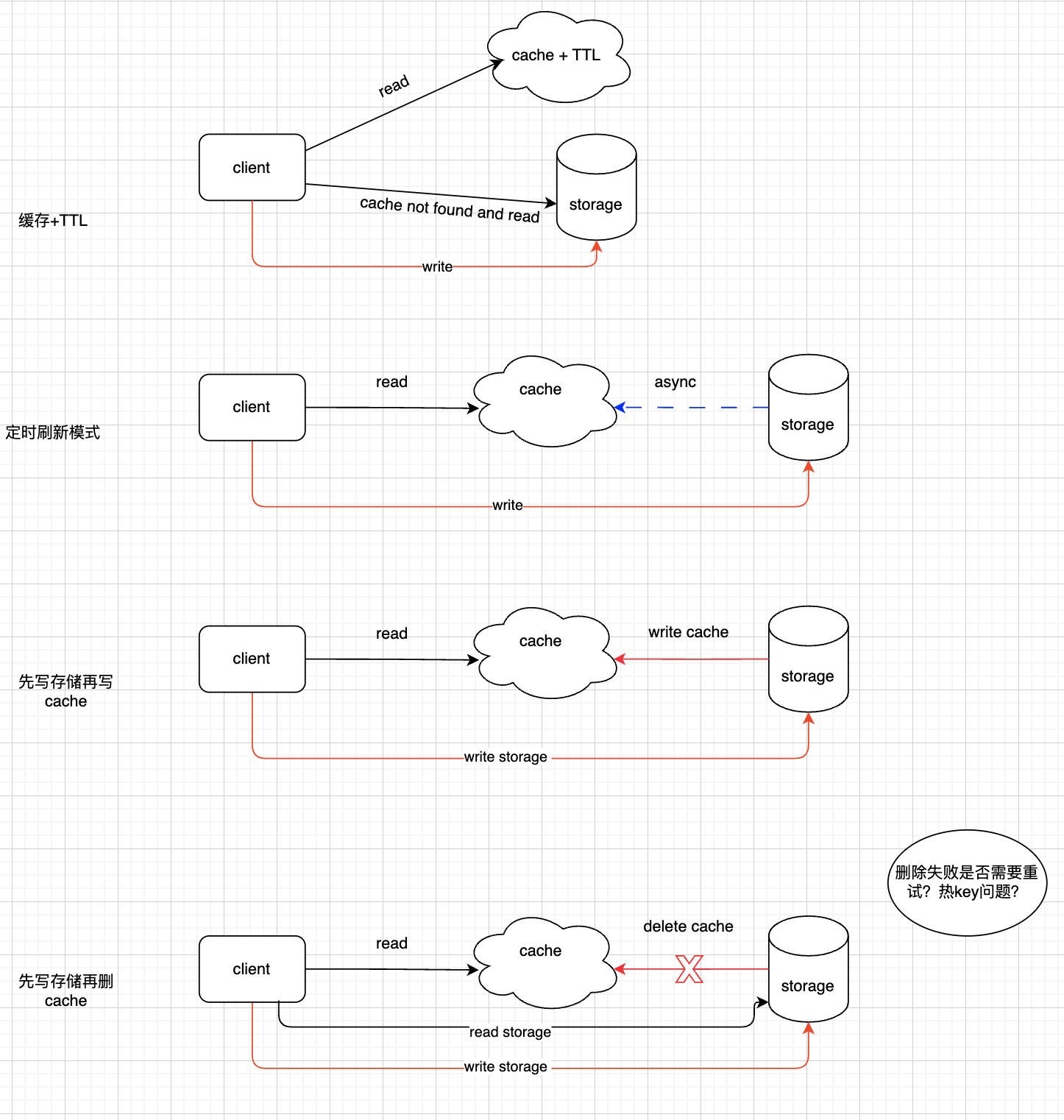
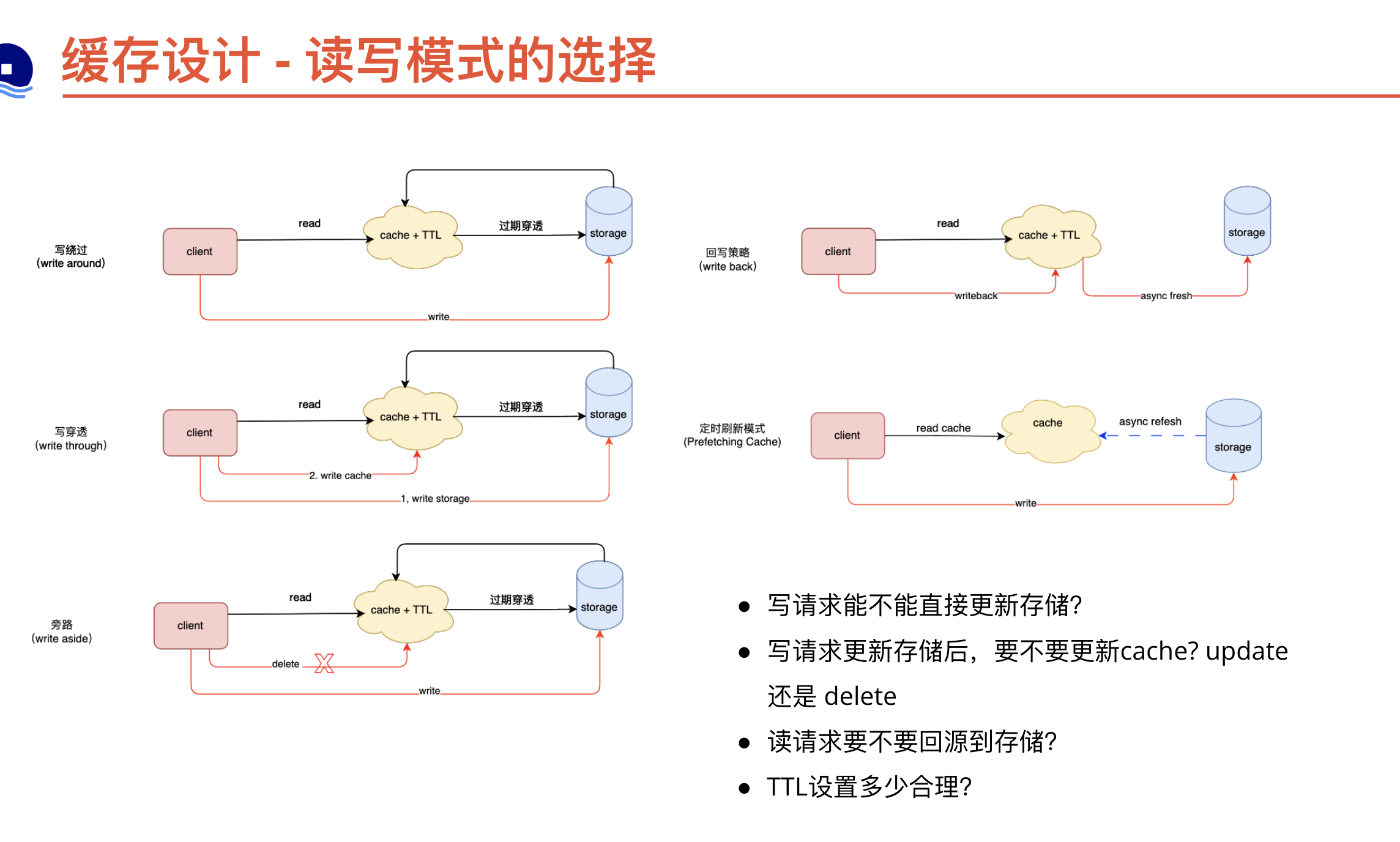
| 缓存更新方式 | 优缺点 |
|---|---|
| 缓存模式+TTL | 业务代码只更新DB,不更新cache,设置较短的TTL(通常分钟级),依靠cache过期无法找到key时回源DB,热key过期可能回导致请求大量请求击穿到DB,需要使用分布式锁或者singleflight等方式避免这种问题 |
| 定时刷新模式 | 定时任务异步获取DB数据刷新到cache,读请求可不回源,需要考虑刷新时间和批量读写 |
| 写DB,写cache | 在并发条件下,DB写操作顺序和cache操作不同保证顺序一致性,需要增加分布式锁等操作 |
| 写DB,删除cache | 删除cache可能失败,需要增加重试,重试也可能失败,比较复杂的加个MQ补偿重试 |
思考:
- 对一致性要求有多强?
- TTL 设置的时长
- 并发冲突可能性
- 热key缓存击穿保护
redis 怎么扩容扩容和收缩
redis 为什么使用单线程模型
缓存异常与对应的解决办法
- 缓存雪崩问题,大面积键失效或删除
- 缓存穿透问题,不存在key的攻击行为
- 热点数据缓存击穿,热门key失效
- 是否需要缓存预热
- 缓存穿透,缓存击穿,缓存雪崩解决方案分析,https://juejin.im/post/6844903651182542856
redis 为什么这么快
- 1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1);
- 2、数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的;
- 3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
- 4、使用多路 I/O 复用模型,非阻塞 IO;
- 5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
Redis实现分布式锁
- Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系Redis中可以使用SETNX命令实现分布式锁。当且仅当 key 不存在,将 key 的值设为 value。 若给定的 key 已经存在,则 SETNX 不做任何动作SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。返回值:设置成功,返回 1 。设置失败,返回 0
redis分布式方案
- 单机版,并发访问有限,存储有限,单点故障。
- 数据持久化
- 主从复制。主库(写)同步到从库(读)的延时会造成数据的不一致;主从模式不具备自动容错,需要大量的人工操作
- 哨兵模式sentinel。在主从的基础上,实现哨兵模式就是为了监控主从的运行状况,对主从的健壮进行监控,就好像哨兵一样,只要有异常就发出警告,对异常状况进行处理。当master出现故障时,哨兵通过raft选举,leader哨兵选择优先级最高的slave作为新的master,其它slaver从新的master同步数据。哨兵解决和主从不能自动故障恢复的问题,但是同时也存在难以扩容以及单机存储、读写能力受限的问题,并且集群之前都是一台redis都是全量的数据,这样所有的redis都冗余一份,就会大大消耗内存空间
- codis: https://github.com/CodisLabs/codis
- redis cluster集群模式:集群模式时一个无中心的架构模式,将数据进行分片,分不到对应的槽中,每个节点存储不同的数据内容,通过路由能够找到对应的节点负责存储的槽,能够实现高效率的查询。并且集群模式增加了横向和纵向的扩展能力,实现节点加入和收缩,集群模式时哨兵的升级版,哨兵的优点集群都有
- redis 分布式架构演进
- Redis集群化方案对比:Codis、Twemproxy、Redis Cluster
redis & Lua
Redis 执行 Lua 脚本会以原子性方式进行,在执行脚本时不会再执行其他脚本或命令。并且,Redis 只要开始执行 Lua 脚本,就会一直执行完该脚本再进行其他操作,所以 Lua 脚本中 不能进行耗时操作 。此外,基于 Redis + Lua 的应用场景非常多,如分布式锁,限流,秒杀等等。
基于项目经验来看,使用 Redis + Lua 方案有如下注意事项:
- 使用 Lua 脚本实现原子性操作的 CAS,避免不同客户端先读 Redis 数据,经过计算后再写数据造成的并发问题
- 前后多次请求的结果有依赖关系时,最好使用 Lua 脚本将多个请求整合为一个;但请求前后无依赖时,使用 pipeline 方式,比 Lua 脚本方便
- 为了保证安全性,在 Lua 脚本中不要定义自己的全局变量,以免污染 Redis 内嵌的 Lua 环境。因为 Lua 脚本中你会使用一些预制的全局变量,比如说 redis.call()
- 注意 Lua 脚本的时间复杂度,Redis 的单线程同样会阻塞在 Lua 脚本的执行中,Lua 脚本不要进行高耗时操作
- Redis 要求单个 Lua 脚本操作的 key 必须在同一个 Redis 节点上,因此 Redis Cluster 方式需要设置 HashTag(实际中不太建议这样操作)
redis 常用命令
- redis-cli -h host -p port -a password
- set key value [NX|XX] [EX seconds|PX milliseconds|EXAT unix]
- get key
- keys pattern,*表示通配符,表示任意字符,会遍历所有键显示所有的键列表,时间复杂度O(n),在生产环境不建议使用
- exists key [key …]
- 秒语法查询key的过期时间:ttl key
sdk
- github.com/go-redis/redis
推荐阅读:
- https://blog.csdn.net/ThinkWon/article/details/103522351
- https://tech.meituan.com/2017/03/17/cache-about.html
- 一不小心肝出了4W字的Redis面试教程
- 你的 Redis 为什么变慢了?
- redis dbindex. https://blog.csdn.net/lsm135/article/details/52945197
- 颠覆认知——Redis会遇到的15个「坑」,你踩过几个?
- Redis最佳实践:7个维度+43条使用规范
- Redis为什么变慢了?
- redis 常用命令以及时间复杂度
- 单线程redis为什么快