了解DaSiamRPN追踪算法的运行过程
在2018年的CVPR上SiameseRPN模型被提出,它宣称在单目标跟踪问题上做到了state-of-the-art,能同时兼顾精度(accuracy)和速度(efficiency)。在这之后,很快又在ECCV上发表了DaSiamRPN模型,它在SiameseRPN基础进一步提升了追踪的性能。SiameseRPN不是一簇而就的,它的设计思想来源于SiameseFc,并引入物体检测领域的区域推荐网络(RPN),通过网络回归避免了多尺度测试,同时得到更加精准的目标框和目标的位置。实际使用中发现DaSiamRPN相比传统的KCF效果直观感受确实精度有较大提升,在普通pc无GPU环境上大概是10.6fps。这里主要结合SimeseRPN的论文和DaSiamRPN的代码帮助了解SimeseRPN的模型结构以及DaSiamRPN的运行过程。
SiameseRPN模型
Siamese-RPN本质上是组合网络模型,它包括用于特征提取的Siamese网络和生成候选区域的RPN网络。
Siamese特征提取网络:它目前在追踪领域使用比较多,包括模板分支(template branch)和检测分支(detection branch),它们都是经过裁剪的AlexNet卷积网络,用于提取图像的特征。两个分支网络参数和权重值完全相同,只是输入不同,模板分支输入模板帧中的目标部分(target patch),检测分支输入当前需要追踪的帧的区域(target patch)。
RPN(region proposal subnetwork)候选区域生成网络:它包括的分类(classification)和回归(regression)两个分支。这里有个重要的锚点(anchor),就是通过RPN对每个锚点上的k个不同宽度和高度的矩形分类和回归,得到感兴趣区域。每个anhcor box要分前景和背景,所以cls=2k;而每个anchor box都有[x, y, w, h]对应4个偏移量,所以reg=4k。
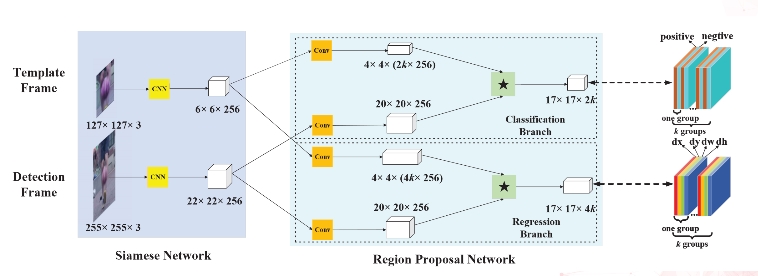
因此设模板分支输入为$z$维度为(127,127,3),首先通过Siamese网络特征提取得到$ψ(z)$维度为(6,6,256),然后再经历卷积分别的到$[ψ(z)]{cls}$和$[ψ(z)]{res}$。检测分支输入为$x$,$ψ(x)$为Siamese特征提取网路的输出,以$[ψ(z)]{cls}$和$[ψ(z)]{res}$为核卷积得到最终的SiameseRPN的输出,$*$表示卷积运算。
$$A_{w×h×2k}^{cls} = [ψ(x)]{cls} * [ψ(z)]{cls}$$
$$A_{w×h×4k}^{res} = [ψ(x)]{res} * [ψ(z)]{res}$$
DaSiamRPN视频追踪的过程
DaSiamRPN做视频目标追踪,DaSiamRPN相比SiameseRPN做了进一步的优化,例如训练时引入采样策略控制不平衡的样本分布,设计了一种distractor-aware模块执行增量学习等。结合官方的https://github.com/foolwood/DaSiamRPN 中的例子,很容易将demo运行起来。需要注意的是github上的代码需要gpu运行环境,如果要在无gpu机器上运行DaSiamRPN的demo需要将有关cuda代码去掉。例如将将net.eval().cuda()换成net.eval()。DaSiamRPN的运行包含两个步骤:
- 初始化。输入模板帧,得到$[ψ(z)]{cls}$和$[ψ(z)]{res}$两个用于卷积的核。
- 追踪。将待追踪帧输入到模型,得到每个候选区域的score和偏移delta。从候选区域中选出分数最高的候选区域proposal。
初始化
- 输出模板图片im,模板图片中目标位置target_pos,目标大小target_size,使用get_subwindow_tracking函数裁剪目标区域临近部分(target patch),并将裁剪得到图片resize到宽和高为127的图片。
- 将模板目标区域裁剪好的视频输入网络模型的模板分支(template branch),得到$[ψ(z)]{cls}$和$[ψ(z)]{res}$
- 使用generate_anchor函数产生anchers,其大小为$(271-127)/8+1=19,19*19*5=1805$,anchor的维度为(4,1805),这表示会有1805个候选区域,偏移量$d_x,d_y,d_w,d_h$
追踪
- 输入追踪的图片im,基于上一帧的target_pos和目标的大小位置target_size,在图片中裁剪部分区域并将该区域resize到271*271得到x_crop。
- 将x_crop输入网络的检测分支(detection branch)得到对所有anchor进行分类和回归得到delta和score。
- 根据delta获取细化后的候选区域(refinement coordinates)
1
2
3
4
5# generate the refined top K proposals
delta[0, :] = delta[0, :] * p.anchor[:, 2] + p.anchor[:, 0] #x
delta[1, :] = delta[1, :] * p.anchor[:, 3] + p.anchor[:, 1] #y
delta[2, :] = np.exp(delta[2, :]) * p.anchor[:, 2] #w
delta[3, :] = np.exp(delta[3, :]) * p.anchor[:, 3] #h - 结合scale penalty、ration penalty、cosine window调整每个候选区域score中每个候选区域的分数,选出分数最大的候选区域best_pscore_id.
1
2
3
4
5
6
7
8# size penalty
s_c = change(sz(delta[2, :], delta[3, :]) / sz_wh(target_sz)) # scale penalty
r_c = change((target_sz[0] / target_sz[1]) / (delta[2, :] / delta[3, :])) # ratio penalty
penalty = np.exp(-(r_c * s_c - 1.) * p.penalty_k)
pscore = penalty * score
# window float
pscore = pscore * (1 - p.window_influence) + window * p.window_influence
best_pscore_id = np.argmax(pscore) - 计算出当前帧目标的位置target_pos和target_size。
1
2
3
4
5
6
7
8
9
10
11
12target = delta[:, best_pscore_id] / scale_z
target_sz = target_sz / scale_z
lr = penalty[best_pscore_id] * score[best_pscore_id] * p.lr
res_x = target_pos[0] + target[0]
res_y = target_pos[1] + target[1]
res_w = target_sz[0] * (1 - lr) + target[2] * lr
res_h = target_sz[1] * (1 - lr) + target[3] * lr
target_pos = np.array([res_x, res_y])
target_sz = np.array([res_w, res_h])
参考: