tensorflow模型通道剪枝(channel pruning)实战
一、概述
最近在做模型压缩(model compress)相关工作,之前分别尝试了权重量化(weight quantization)【1】和权重稀疏(weight sparsification)【2】,遗憾的是它们都需要推理引擎和硬件的特定优化才能实现推理加速,而tensorflow在x86架构的CPU下并没有没有针对量化和稀疏矩阵的优化,因此效果一般。吸取前两次的经验,这次尝试了结构化压缩通道剪枝(channel pruning),它通过删减模型中冗余通道channel,减少的模型前向计算所需的FLOPs。通道剪枝来自论文ICCV2017论文 Channel Pruning for Accelerating Very Deep Neural Networks。 这里会首先简单介绍channel pruning的原理,然后通过PocketFlow压缩工具对ResNet56进行通道剪枝,结果显示channel pruning在精度不怎么损失的基础上,减小接近50%的FLOPs。由于剪枝后模型中增加了许多的conv2d 1x1卷积,实际提升推理效率大概20%。
二、channel pruning 基本原理
1. 什么是通道剪枝
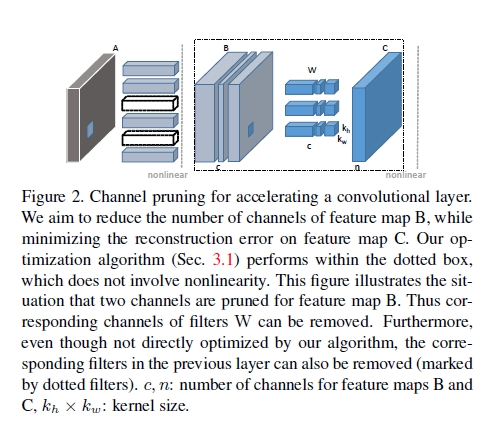
虽然论文末尾谈到channel pruning可以应用到模型训练中,但是文章的核心内容还是对训练好的模型进行channel pruning,也就是文章中说的inference time。通道剪枝正如其名字channel pruning核心思想是移除一些冗余的channel简化模型。下图是从论文中截取的通道剪枝的示意图,它表示的网络模型中某一层的channel pruning。B表示输入feature map,C表示输出的feature map;c表示输入B的通道数量,n表示输出C的通道数量;W表示卷积核,卷积核的数量是n,每个卷积核的维度是ckhkw,kh和kw表示卷积核的size。通道剪枝的目的就是要把B中的某些通道剪掉,但是剪掉后的B和W的卷积结果能尽可能和C接近。当删减B中的某些通道时,同时也裁剪了W中与这些通道的对应的卷积核,因此通过通过剪枝能减小卷积的运算量。
2. 通道剪枝数学描述
通道剪枝的思想是简单的,难点是怎么选择要裁剪的通道,同时要保证输出feature map误差尽可能得小,这也是文章的主要内容。channel pruning总体分为两个步骤,首先是channel selection,它是采用LASSO regression来做的,通过添加L1范数来约束权重,因为L1范数可以使得权重中大部分值为0,所以能使权重更加稀疏,这样就可以把那些稀疏的channel剪掉;第二步是reconstruction,这一步是基于linear least优化,使输出特征图变化尽可能的小。
接下来通过数学表达式描述了通道剪枝。X($N*c* k_h*k_w$)表示输入feature map,W($n * c * k_h * k_w$)表示卷积核,Y($N*n$)表示输出feature map。$\beta_i$表示通道系数,如果等于0,表示该通道可以被删除。我们期望将输入feature map的channel从c压缩为c’($0<=c’<= c$),同时要使得构造误差(reconstruction error)尽可能的小。通过下面的优化表达式,就可以选择哪些通道被删除。文章中详细介绍了怎么用算法解决下面的数据问题,这里就不赘述了。另外文章还考虑分支情况下的通道剪枝,例如ResNet和GoogleNet,感兴趣的可以仔细研读该论文【3】。
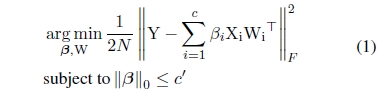
三、PocketFlow
PocketFlow是腾讯AI Lab开源的自动化深度学习模型压缩框架,它集成了腾讯自己研发的和来自其他同行的主流的模型压缩与训练算法,还引入了自研的超参数优化组件,实现了自动托管式模型压缩与加速。PocketFlow能够自动选择模型压缩的超参,极大的方便了算法人员的调参。这里主要使用里面的channel pruning算法(learner)进行通道剪枝。【4】
1.实验准备:
1.cifar10数据集: https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
2.ResNet56预训练模型:https://share.weiyun.com/5610f11d61dfb733db1f2c77a9f34531
3.下载Pocketflow: https://github.com/wxquare/PocketFlow.git
2.准备配置文件path.conf
1 | # data files |
3.在本地运行通道剪枝的learner
1 | $ ./scripts/run_local.sh nets/resnet_at_cifar10_run.py \ |
4. 模型转换
步骤3之后会在models产生ckpt文件,需要通过进行模型转化,最终会生成model_original.pb,model_transformed.pb,同时也会生成移动端对应的tflite文件。
1 | $ python tools/conversion/export_chn_pruned_tflite_model.py \ |
四、剪枝前后模型分析
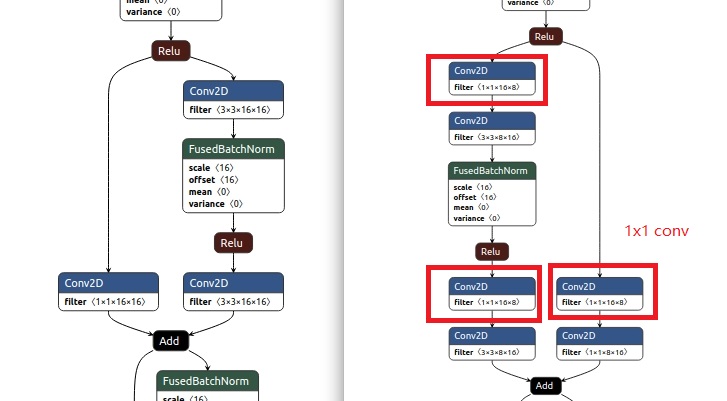
我们可以通过之前介绍的模型基准测试工具benchmark_model分别测试剪枝前后的模型。可以很清楚看到通道剪枝大大减少了模型前向计算的FLOPs的变化,以及各阶段、算子的耗时和内存消耗情况。可以发现模型下降为原来的1/2,卷积耗时下降接近50%。除此之外通过netron工具可以直观的看到模型通道剪枝前后结构发生的变化,通道剪枝之后的模型中明显增加了许多conv1*1的卷积。这里主要利用1x1卷积先降维,然后升维度,达到减少计算量的目的。1x1卷积还有多种用途,可以参考【5】。
1 | $ bazel-bin/tensorflow/tools/benchmark/benchmark_model \ |
参考:
[1]. tensorflow模型权重量化(weight quantization)实战
[2]. tensorflow模型权重稀疏(weight sparsification)实战
[3].Channel Pruning for Accelerating Very Deep Neural Networks
[4].PocketFLow
[5].1x1卷积:https://www.zhihu.com/question/56024942