互联网业务系统 - 电商系统后台
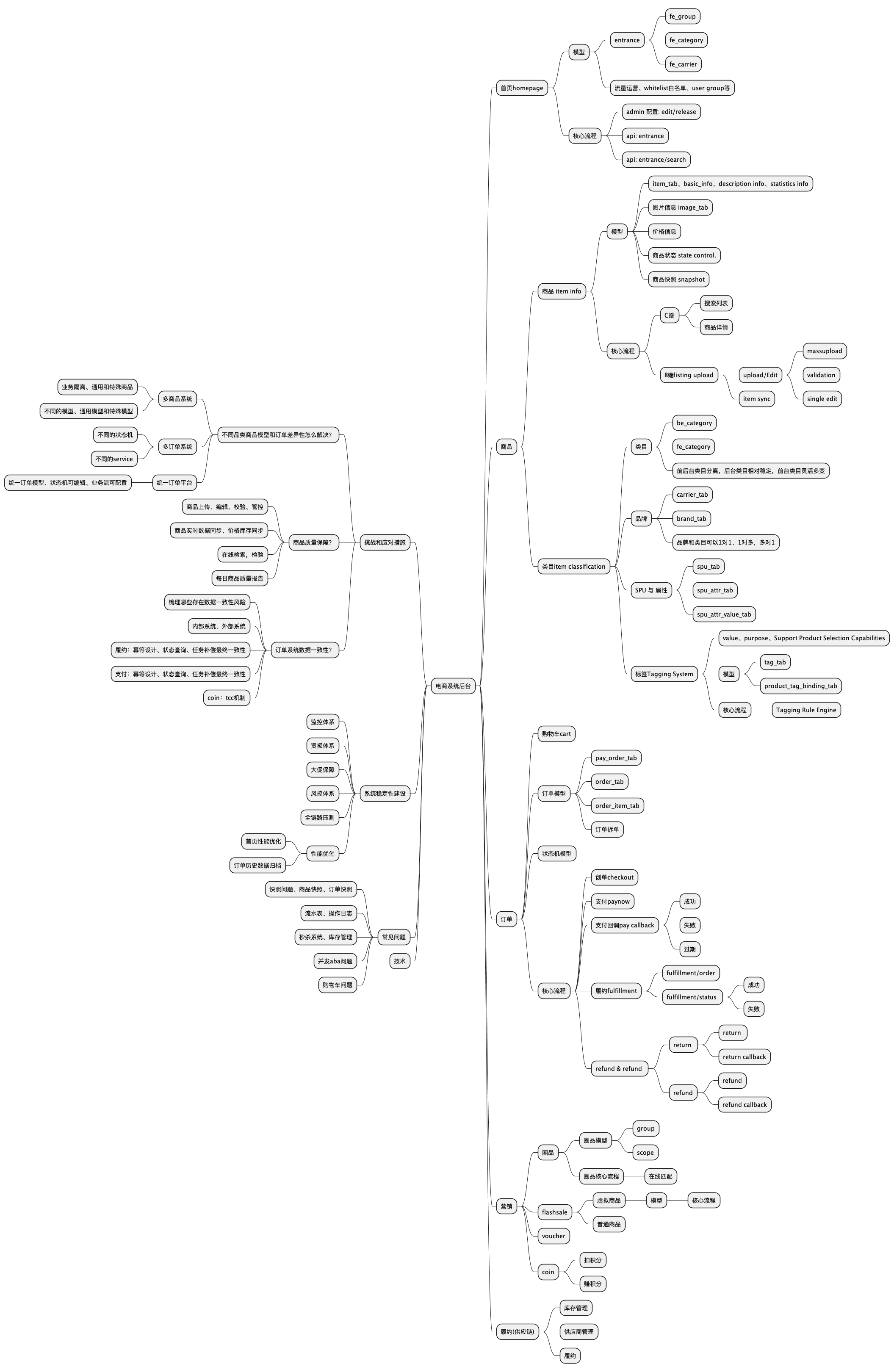
商品模型
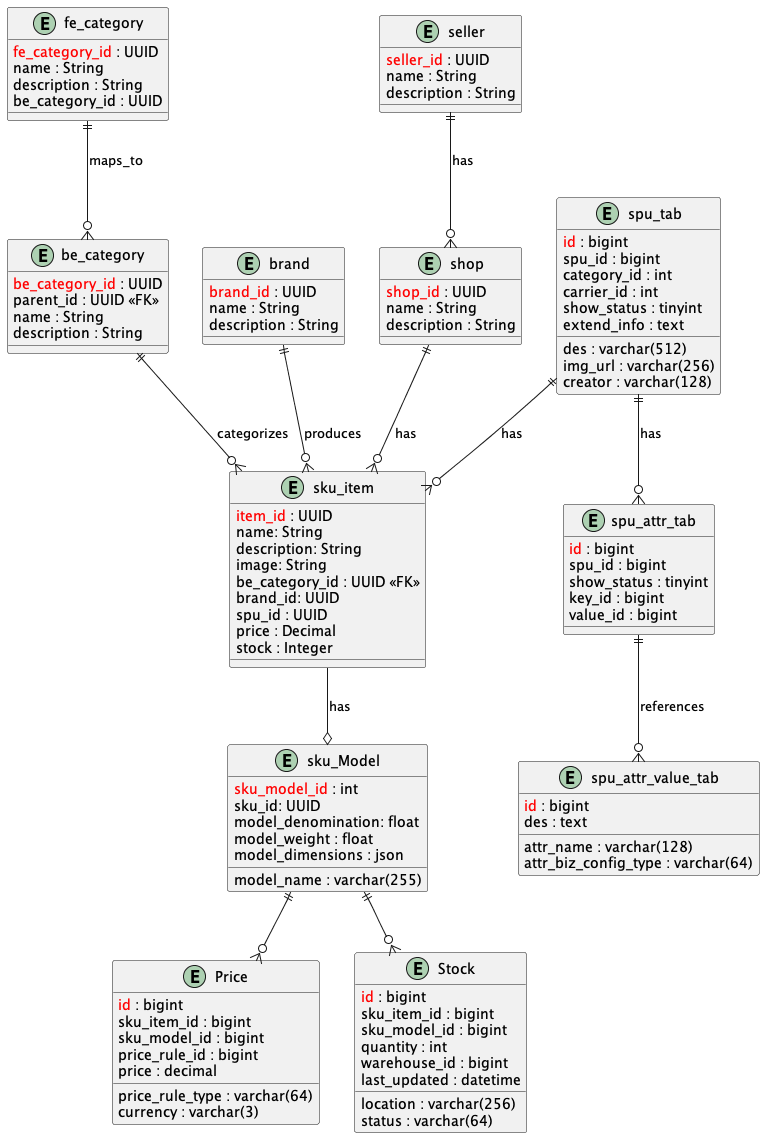
- 为什么需要fe_category 和 be_category,提供前台运营的灵活性
- sku_item,sku_model。一个item是一系列sku的集合
item
item-SKU
订单模型
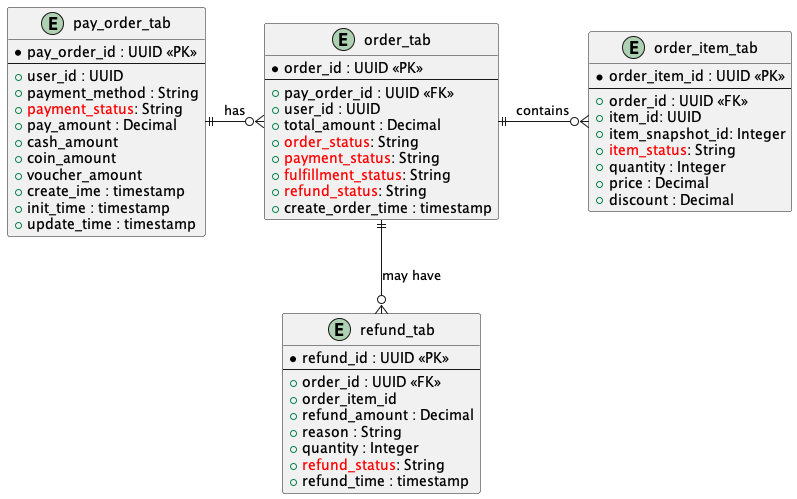
支付订单表(pay_order_tab):主要用于记录用户的支付信息。主键为 pay_order_id,标识唯一的支付订单。
- user_id:用户ID,标识支付的用户。
- payment_method:支付方式,如信用卡、支付宝等。
- payment_status:支付状态,如已支付、未支付等。
- pay_amount、cash_amount、coin_amount、voucher_amount:支付金额、现金支付金额、代币支付金额、优惠券使用金额。
- 时间戳字段包括创建时间、初始化时间和更新时间
订单表(order_tab):记录用户的购买订单信息。主键为 order_id。
- pay_order_id:支付订单ID,作为外键关联支付订单。
- user_id:用户ID,标识购买订单的用户。
- total_amount:订单的总金额。
- order_status:订单状态,如已完成、已取消等。
- payment_status:支付状态,与支付订单相关。
- fulfillment_status:履约状态,表示订单的配送或服务状态。
- refund_status:退款状态,用于标识订单是否有退款
订单商品表(order_item_tab:记录订单中具体商品的信息。主键为 order_item_id。
- order_id:订单ID,作为外键关联订单。
- item_id:商品ID,表示订单中的商品。
- item_snapshot_id:商品快照ID,记录当时购买时的商品信息快照。
- item_status:商品状态,如已发货、退货等。
- quantity:购买数量。
- price:商品单价。
- discount:商品折扣金额
退款表(refund_tab):记录订单或订单项的退款信息。主键为 refund_id。
- order_id:订单ID,作为外键关联订单。
- order_item_id:订单项ID,标识具体商品的退款。
- refund_amount:退款金额。
- reason:退款原因。
- quantity:退款的商品数量。
- refund_status:退款状态。
- refund_time:退款操作时间。
实体间关系:
支付订单与订单:
- 一个支付订单可能关联多个购买订单,形成 一对多 关系。
例如,用户可以通过一次支付购买多个不同的订单。
订单与订单商品:
一个订单可以包含多个订单项,形成 一对多 关系。
订单项代表订单中所购买的每个商品的详细信息。
订单与退款:
- 一个订单可能包含多个退款,形成 一对多 关系。
- 退款可以是针对订单整体,也可以针对订单中的某个商品
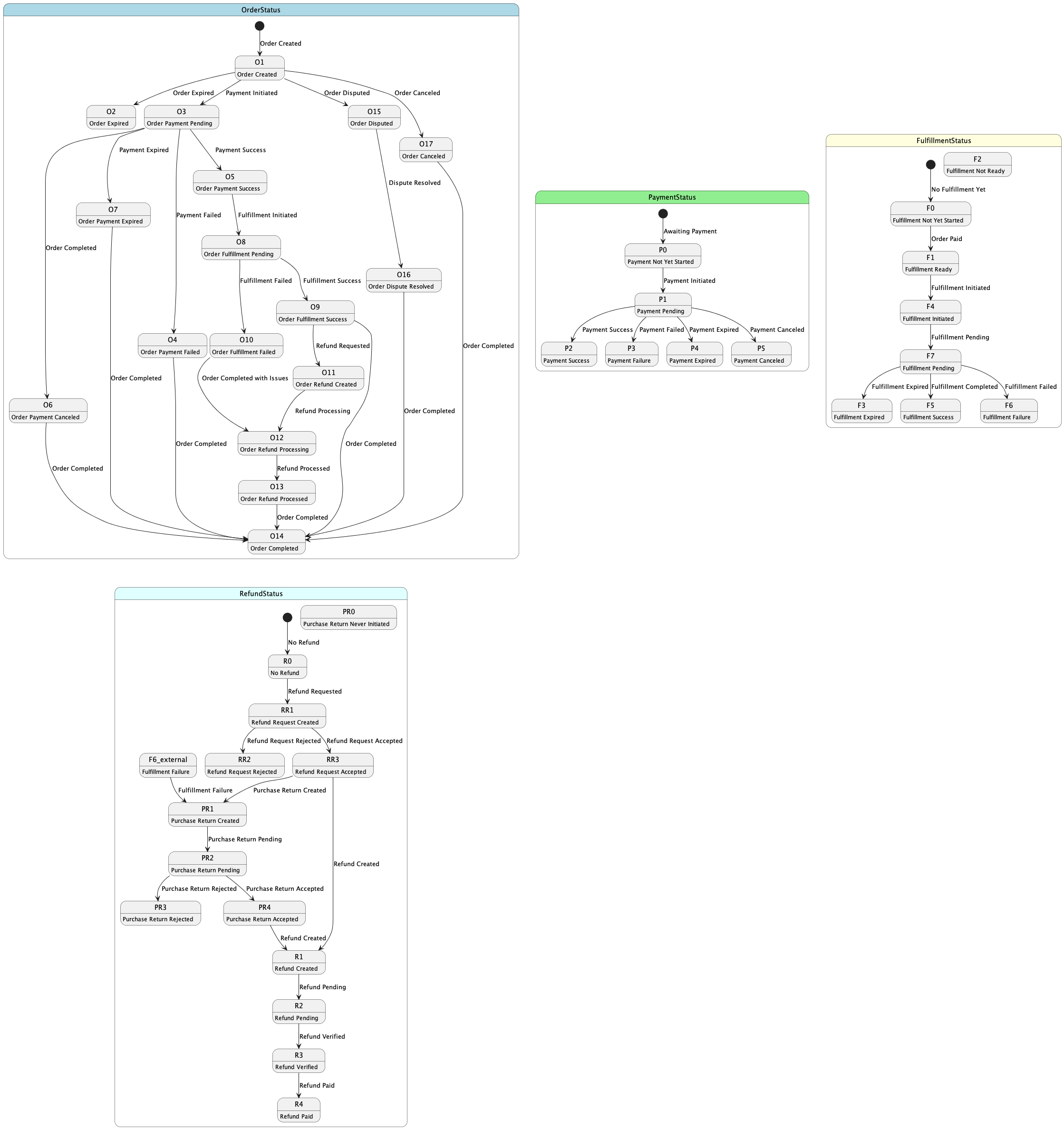
订单状态机
核心业务流
B 端
首页运营和维护
批量商品上传
商品Edit更新,价格、状态等
APP端
首页获取
商品搜索(列表)
商品(商品详情)
创单核心逻辑
- 用户校验
- 商品信息获取和校验
- 价格校验
- 营销活动校验
- antifraud
- 库存校验
- 生成payorderid和orderid
- 库存扣减和返还
- 营销活动扣减和返还
- 构建订单信息,插入DB
- 不同类型的创单逻辑会不同,这里通过接口定义基础的创单逻辑,后续不同类型的定义机遇这个逻辑扩展
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58package orderserver
// OrderRequest 包含创建订单所需的参数
type OrderRequest struct {
UserID string
ProductID string
Quantity int
}
// OrderResponse 表示创建订单的响应
type OrderResponse struct {
OrderID string
Message string // 返回的信息,例如错误信息
}
// OrderServer 接口定义了创建订单的功能
type OrderServer interface {
// validate
ValidateUser(userID string) errors.ErrorCode
GetProductInfo(productID string) (ProductInfo, errors.ErrorCode)
ValidateProduct(productID string) errors.ErrorCode
ValidatePrice(productID string) errors.ErrorCode
ValidateInventory(productID string, quantity int) errors.ErrorCode
ValidatePromotionCode(promoCode string) errors.ErrorCode
CheckFraud() errors.ErrorCode
GeneratePayOrderID() (string, errors.ErrorCode)
GenerateOrderID() (string, errors.ErrorCode)
DeductInventory(productID string, quantity int) errors.ErrorCode
ReturnInventory(productID string, quantity int) errors.ErrorCode
DeductPromotion(promoCode string) errors.ErrorCode
ReturnPromotion(promoCode string) errors.ErrorCode
BuildDBModels() errors.ErrorCode
InsertOrder(order OrderRequest) (OrderResponse, error)
LogOperation(orderID string, userID string) error
PushOrderCreateEvent() errors.ErrorCode
}
// BaseOrderService 实现 OrderServer 接口
type BaseOrderService struct {
// 可以添加数据库连接或其他依赖项
req OrderRequest
resp OrderResponse
OrderModel *order.Model
PayOrderModel *order.PayModel
OrderItemModels []*item.OrderItemModel
}
func (bos *BaseOrderService) ValidateUser(userID string) ErrorCode {
// 简单的用户验证逻辑(示例)
return Success
}
....
订单支付和支付结果回调
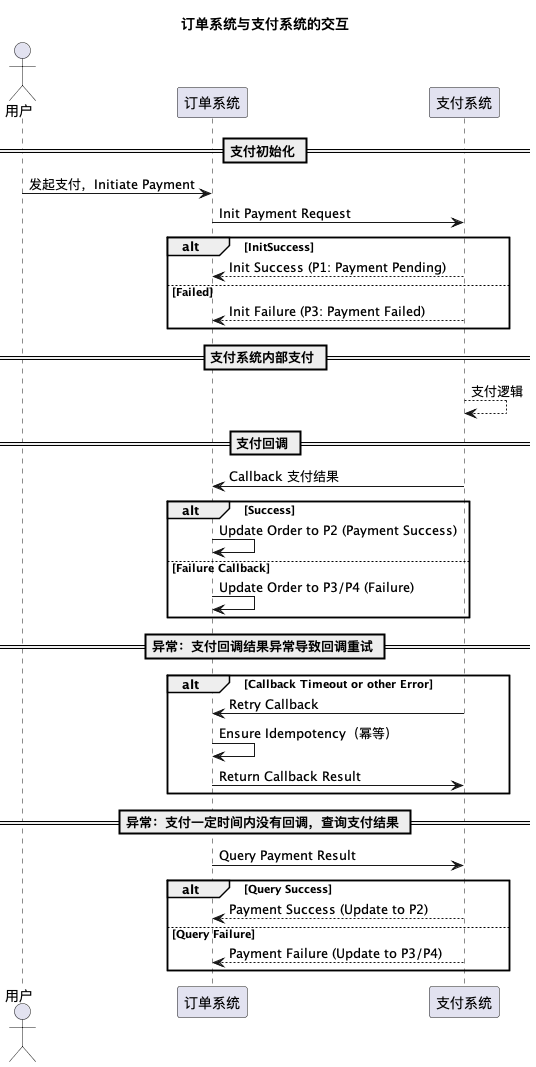
1 | type OrderPayRequest struct { |
订单履约和履约结果回调
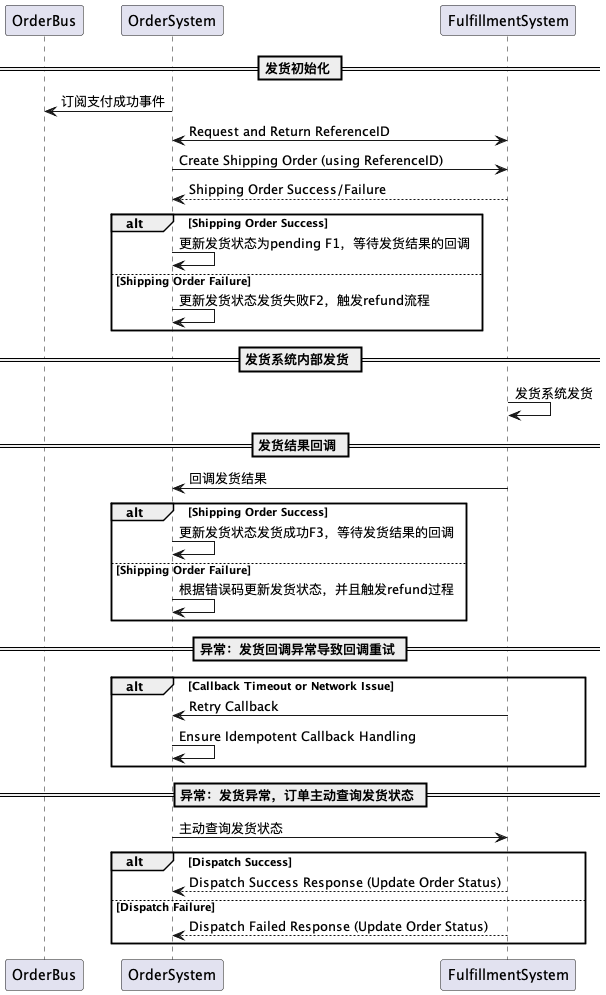
1 | package fulfillmentserver |
return & refund
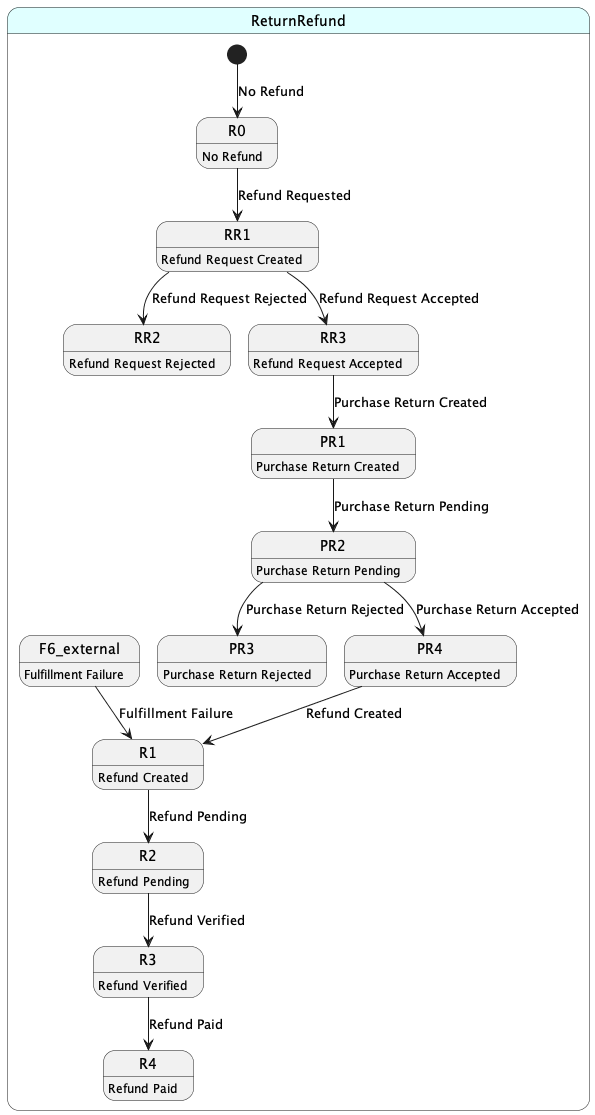
- UserRefundOrderService、AdminRefundOrderService、FailedFulfillmentRefundOrderService
- Return
- refund
RefundPlaceOrder
1 | package refundservice |
RefundApproveService
1 | // RefundApproveRequest 包含退款审批请求所需的参数 |
ReturnPurchaseService
1 | // ReturnPurchaseRequest 包含退货请求所需的参数 |
RefundService
1 | package refundservice |
订单详情查询
系统挑战
如何维护订单状态的最终一致性?
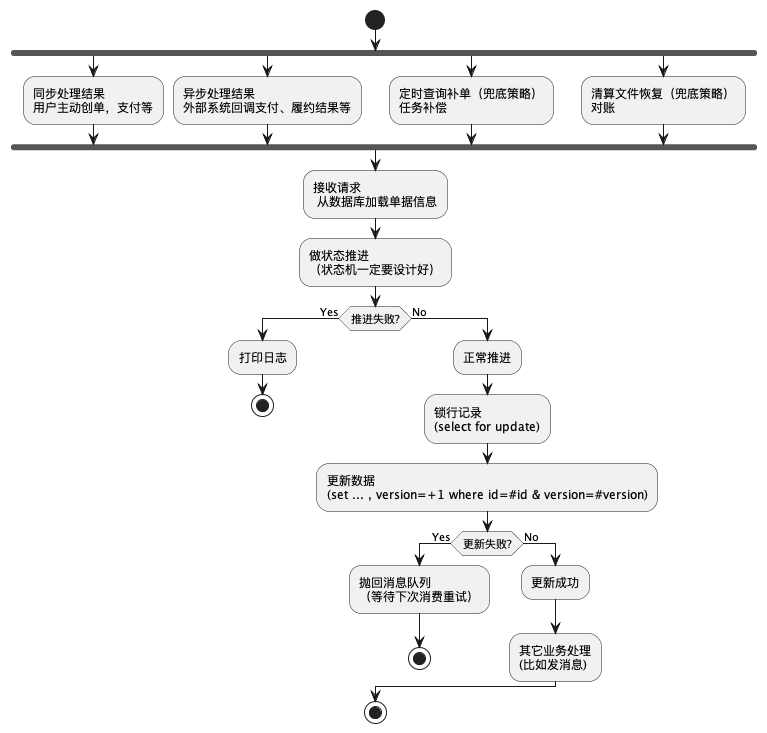
- 状态机一定要设计好,只有特定的原始状态 + 特定的事件才可以推进到指定的状态。
- 并发更新数据库前,要用乐观锁或者悲观锁,先使用select for update进行锁行记录,同时在更新时判断版本号是否是之前取出来的版本号,更新成功就结束,更新失败就组成消息发到消息队列,后面再消费。
- 通过补偿机制兜底,比如查询补单。
- 通过上述三个步骤,正常情况下,最终的数据状态一定是正确的。除非是某个系统有异常,比如外部渠道开始返回支付成功,然后又返回支付失败,说明依赖的外部系统已经异常,这样只能进人工差错处理流程。
商品信息缓存和数据一致性
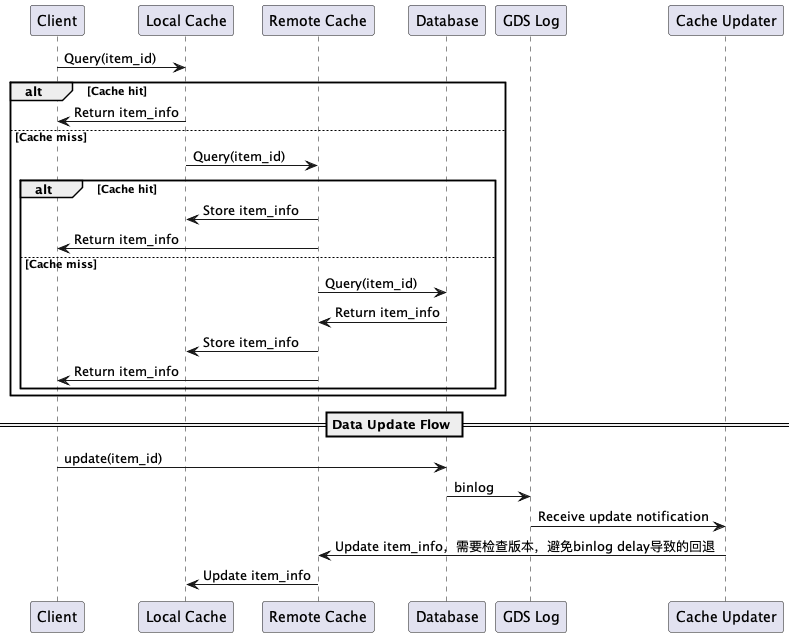
主从架构中如何获取最新的数据,避免因为主从延时导致获得脏数据
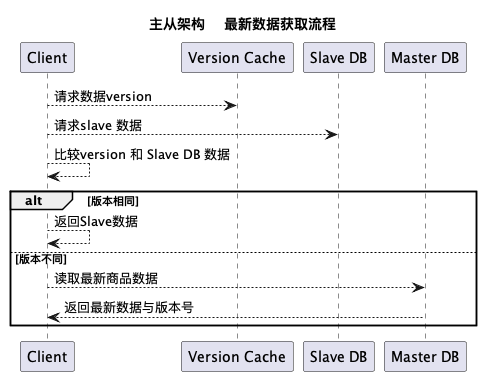
| 策略 | 优点 | 缺点 |
|---|---|---|
| 1. 直接读取主库 | - 一致性: 始终获取最新的数据。 | - 性能: 增加主库的负载,可能导致性能瓶颈。 |
| - 简单性: 实现简单直接,因为它直接查询可信的源。 | - 可扩展性: 主库可能成为瓶颈,限制系统在高读流量下有效扩展的能力。 | |
| 2. 使用VersionCache与从库 | - 性能: 分散读取负载到从库,减少主库的压力。 | - 复杂性: 实现更加复杂,需要进行缓存管理并处理潜在的不一致性问题。 |
| - 可扩展性: 通过将大部分读取操作卸载到从库,实现更好的扩展性。 | - 缓存管理: 需要进行适当的缓存失效处理和同步,以确保数据的一致性。 | |
| - 一致性: 通过比较版本并在必要时回退到主库,提供确保最新数据的机制。 | - 潜在延迟: 从库的数据可能仍然存在不同步的可能性,导致数据更新前有轻微延迟。 |