互联网系统设计 - 概述和技术方案写作
前言
为什么要做设计方案
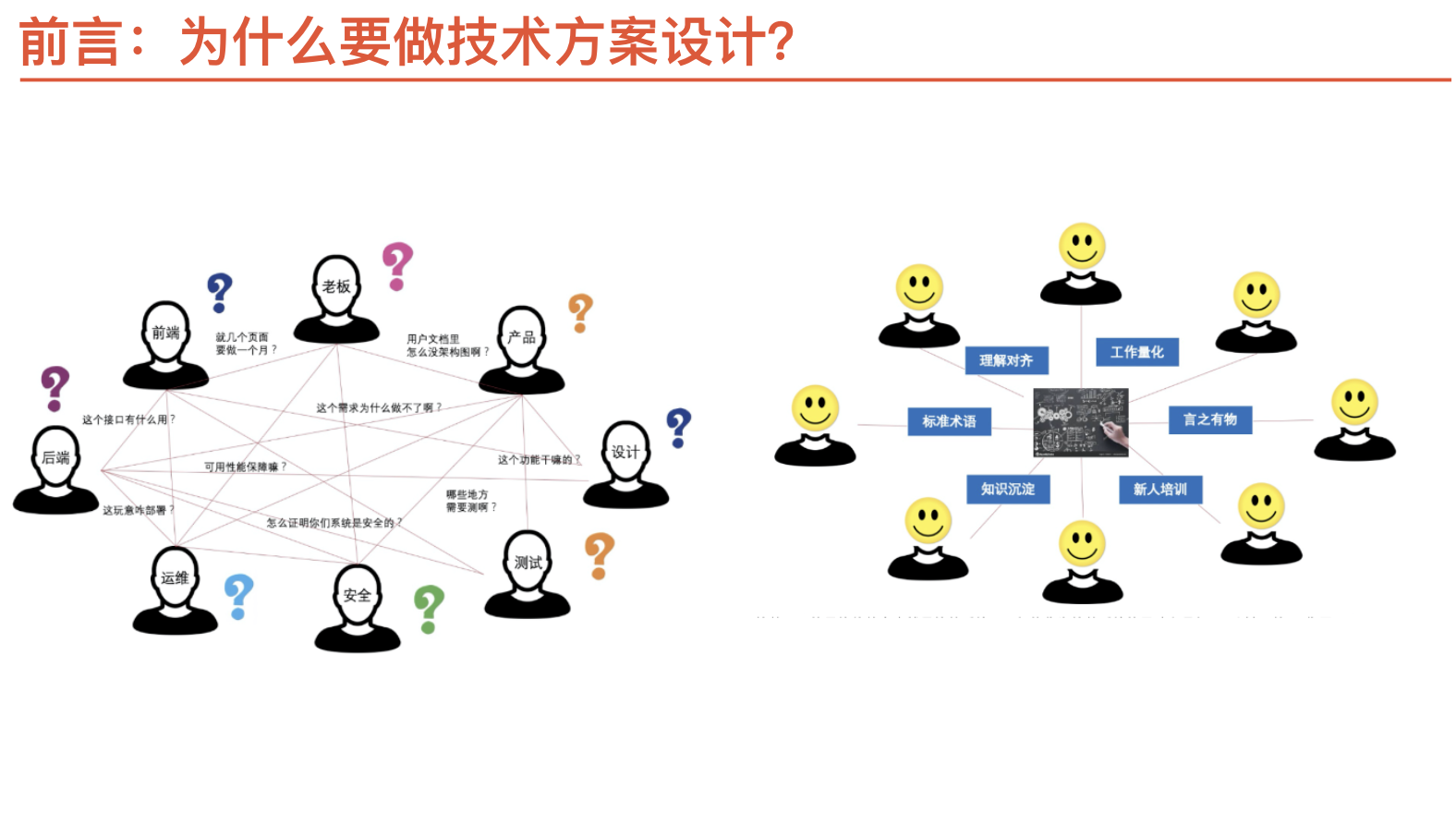
- 设计是系统实现的蓝图
- 设计是沟通协作的基础
- 设计是思考的过程决定了产品的质量
理解对齐:所有软件系统的目的都是为了实现用户需求,但实现的途径有无限种可能性(相比传统工程行业,软件的灵活性更大、知识迭代更快)。架构设计就是去选择其中一条最合适的实现途径,因此其中会涉及非常多关键的选路决策(为什么要这么拆分?为什么选择 A 技术而不是 B?)。这些重要的技术决策需要通过架构描述这种形式被记录和同步,才能让项目组所有成员对整个系统的理解对齐,形成共识。
工作量化:项目管理最重要的步骤之一就是工时评估,它是确定项目排期和里程碑的直接依据。显然,只通过 PRD / 交互图是无法科学量化出项目工作量的,因为很难直观判断出一句简短需求或一个简单页面背后,究竟要写多少代码、实现起来难度有多大。有了清晰明确的架构之后,理论上绝大部分开发工作都能做到可见、可预测和可拆解,自然而然也就能够被更准确地量化。当然,精准的工作量评估在 IT 行业内也一直是个未解之谜,实际的工期会受太多未知因素影响,包括程序员的技能熟练度、心情好不好、有没有吃饱等。
标准术语:编程作为一种具有创造力的工作,从某种角度看跟写科幻小说是类似的。好的科幻小说都喜欢造概念,比如三体中的智子,如果没看过小说肯定不知道这是个啥玩意儿。软件系统在造概念这一点上,相比科幻小说只有过之而无不及,毕竟小说里的世界通常还是以现实为背景,而软件中的世界就全凭造物者(程序员)的想象(建模)了。稍微复杂一点的软件系统,都会引入一些领域特定甚至全新创作的概念。为了避免在项目过程中出现鸡同鸭讲的沟通障碍和理解歧义,就必须对描述这些概念的术语进行统一。而架构的一个重要目的,就是定义和解释清楚系统中涉及的所有关键概念,并在整个架构设计和描述过程中使用标准和一致的术语,真正做到让大家的沟通都在一个频道上。
言之有物 :就跟讨论产品交互时需要对着原型图、讨论代码细节时需要直接看代码一样,架构是在讨论一些较高维技术问题时的必要实物(具体的实物化形式就是所谓架构描述)。否则,要么一堆人对着空气谈(纸上谈兵都说不上),要么每次沟通时都重新找块白板画一画(费时费力且容易遗落信息,显然不是长久之计)。
知识沉淀 & 新人培训:架构应该被作为与代码同等重要的文档资产持续沉淀和维护,同时也是项目新人快速理解和上手系统的重要依据。不要让你的系统跟公司内某些祖传遗留系统一样 —— 只有代码遗留了下来,架构文档却没有;只能靠一些口口相传的残留设计记忆,苦苦维系着项目的生命延续
技术方案应该包含哪些内容
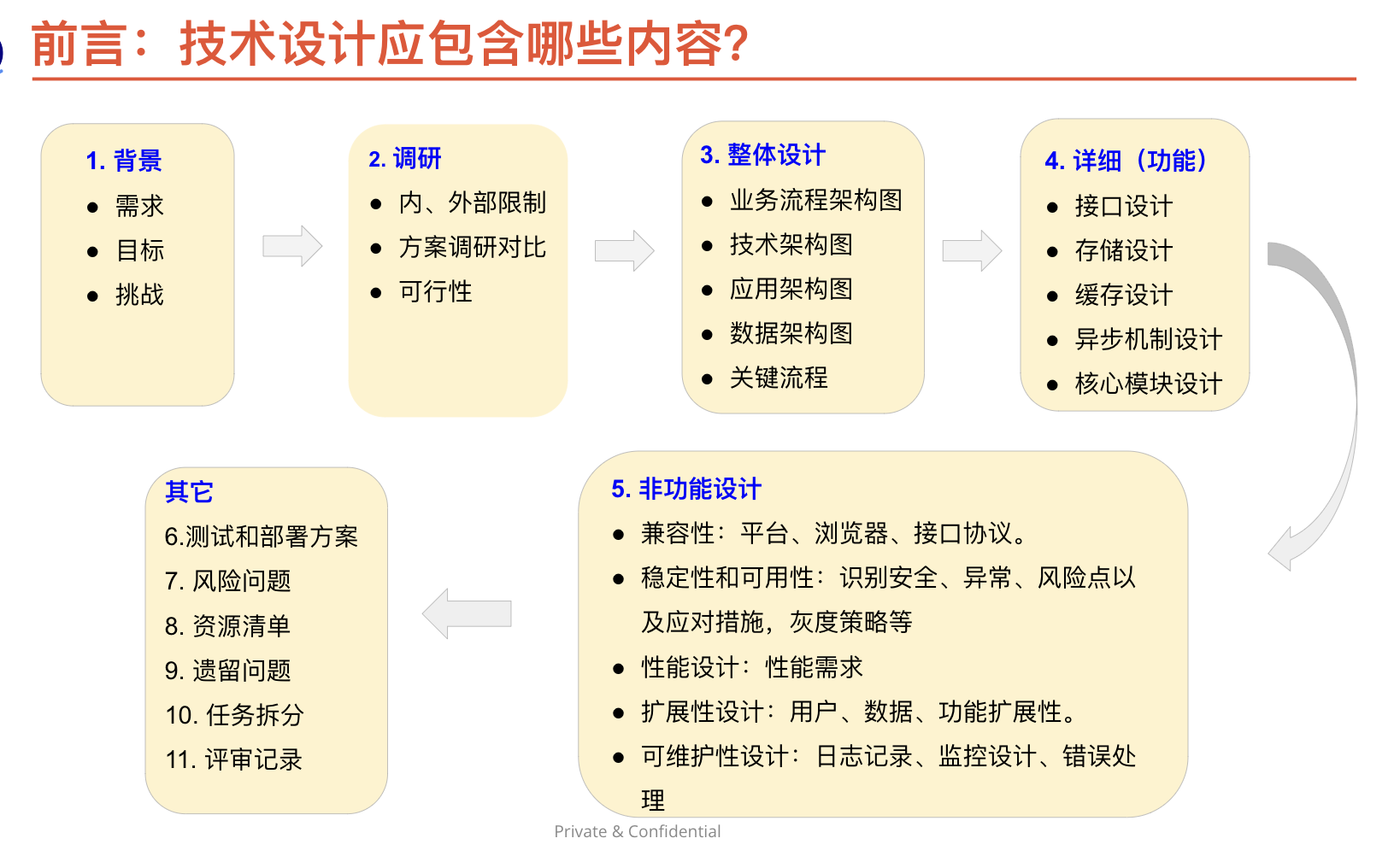
背景:
- 解决的问题:明确要解决的技术问题和产品问题的具体描述。
- 难点和挑战:列出可能遇到的难点、挑战和限制条件。
- 目标和关键指标:明确解决方案的目标和关键指标,例如性能要求、用户体验等。
外部依赖调研
- 外部服务和组件:列出系统所依赖的外部服务、组件或系统,并描述其功能和接口。
- 管理和集成策略:说明如何管理和集成外部依赖,包括版本控制、接口规范等。
业界方案调研和对比:
- 调研结果:调研现有的业界解决方案,并总结其优缺点。
- 对比分析:比较不同方案之间的特点、适用性和可行性。
整体设计:
- 业务流程架构图:展示系统的业务流程和组件之间的关系。
- 系统调用拓扑图:显示系统内部和外部的调用关系。
- 技术架构图:描述系统的技术架构,包括各个模块、组件和数据流之间的关系。
功能设计:
- 存储设计:定义系统中数据的存储方式和结构。
- 接口设计:定义系统的各个模块之间的接口和通信方式。
- 流程设计:描述系统的各个功能模块的流程和交互方式。
- 缓存设计:确定系统中需要使用的缓存策略和机制。
非功能设计:
- 兼容性设计:考虑系统与不同平台、浏览器或设备的兼容性。
- 稳定性设计:定义系统的容错和恢复机制,确保系统的稳定性和可用性。
- 扩展性设计:考虑系统的可扩展性,以便在需要时能够方便地扩展功能和容量。
- 安全设计:定义系统的安全策略和机制,保护用户数据和系统资源。
- 性能设计:考虑系统的性能需求,并设计相应的优化措施。
- 部署设计:定义系统的部署架构和流程,包括服务器配置、网络拓扑等。
- 可维护性设计:考虑系统的可维护性,包括日志记录、错误处理和调试功能。
- 测试策略和方案:定义系统的测试策略和测试计划,包括单元测试、集成测试和系统测试等。
- 部署和运维设计:描述系统的部署和运维策略,包括自动化部署、监控和故障处理等。
- 风险点:识别系统设计中的潜在风险和问题,并提供相应的应对措施。
- 监控设计和异常处理机制:
- 监控需求:定义系统的监控需求,包括日志记录、性能监控和错误监控等。
- 异常处理机制:描述系统对异常情况的处理方式和机制,包括错误提示、异常捕获和处理流程等。
资源清单:
- 硬件资源:列出系统所需的硬件资源,例如服务器、存储设备等。
- 软件资源:列出系统所需的软件资源,例如操作系统、数据库等。
- 人力资源:确定系统开发和维护所需的人力资源,包括开发人员、测试人员等。
任务拆分和排期:
- 任务拆分:将系统开发和实施过程分解为具体的任务和子任务。
- 排期计划:为每个任务和子任务确定时间表和优先级。
评审记录:
- 评审会议记录:记录技术方案评审会议的讨论和决策结果。
- 修改和改进建议:记录评审过程中提出的修改和改进建议,并记录其处理状态。
如何评估技术方案的质量
功能性
- 功能完整度
- 功能正确性
- 功能恰当性
稳定性(Dependability Criteria):
- 可靠性(Reliability):系统处理错误和故障,保证数据完整性和可用性的能力
- 兼容性,向前兼容性值
- 可用性(Availability):系统在投入使用时可操作和可访问的程度。
- 安全性(Security):系统保护用户数据和系统资源,防止未经授权的访问和恶意行为的能力
性能(Performance):
- 响应时间(Latency):系统对请求的反应速度。
- 吞吐量(Throughput):系统处理的工作量
成本(Cost):
- 开发成本(Development Cost):系统的构建和开发所需的费用。
- 部署成本(Deployment Cost):系统部署和运行所需的资源成本。
- 升级成本(Upgrade Cost):将数据从旧系统转换到新系统,以及满足向后兼容性要求的成本。
- 维护成本(Maintenance Cost):包括错误修复和未来功能增强的成本。
- 运营成本(Administration Cost):运行系统的成本。
维护性(Maintainability
- 可扩展性(Extensibility):系统添加新功能的容易程度。
- 可修改性(Modifiability):系统更改功能的容易程度。
- 适应性(Adaptability):系统适应不同应用领域的能力。
- 可移植性(Portability):系统在不同计算机平台上运行的容易程度。
- 可读性(Readability):代码的理解难度。
- 需求可追溯性(Tracability of Requirements):代码与需求之间的映射关系
- 可测试性
用户体验(User Experience)
- 系统提供友好的用户界面和良好的用户交互,以提高用户满意度和使用效率
技术方案模板
** 附录:设计文档模板 **
设计文档没有定式。即使如此,笔者参考谷歌设计文档的结构和格式,并结合实际工作经验加以完善。在此提供一个可供新手参考的设计文档模版,您可以使用此文档模板作为思考的基础。通常,无须事无巨细地填写每一部分,不相关的内容直接略过即可。
计决策的合理性,同时也有助于日后迭代设计时,检查最初的假设是否仍然成立。
背景
我们要解决的问题是什么
为设计文档的目标读者提供理解详细设计所需的背景信息。按读者范围来提供背景。见上文关于目标读者的圈定。设计文档应该是“自足的”(self-contained),即应该为读者提供足够的背景知识,使其无需进一步的查阅资料即可理解后文的设计。保持简洁,通常以几段为宜,每段简要介绍即可。如果需要向读者提供进一步的信息,最好只提供链接。警惕知识的诅咒(知识的诅咒(Curse of knowledge)是一种认知偏差,指人在与他人交流的时候,下意识地假设对方拥有理解交流主题所需要的背景知识)
背景通常可以包括:
需求动机以及可能的例子。 如,“(tRPC) 微服务模式正在公司内变得流行,但是缺少一个通用的、封装了常用内部工具及服务接口的微服务框架”。 - 这是放置需求文档的链接的好地方。
此前的版本以及它们的问题。 如,“(tRPC) Taf 是之前的应用框架, 有以下特点,…………, 但是有以下局限性及历史遗留问题”。
其它已有方案, 如公司内其它方案或开源方案, “tRPC v.s. gRPC v.s. Arvo”
相关的项目,如 “tRPC 框架中可能会对接的其它 PCG 系统”
不要在背景中写你的设计,或对问题的解决思路。
难点和挑战
“解决这个问题的难点和挑战”
用几句话说明该设计文档的关键目的,让读者能够一眼得知自己是否对该设计文档感兴趣。 如:“本文描述 Spanner 的顶层设计”
目标和关键指标
继而,使用 Bullet Points 描述该设计试图达到的重要目标,如:
- 可扩展性
- 多版本
- 全球分布
- 同步复制
非目标也可能很重要。非目标并非单纯目标的否定形式,也不是与解决问题无关的其它目标,而是一些可能是读者非预期的、本可作为目标但并没有的目标,如: - 高可用性
- 高可靠性 如果可能,解释是基于哪些方面的考虑将之作为非目标。如:
- 可维护性: 本服务只是过渡方案,预计寿命三个月,待 XX 上线运行后即可下线
设计不是试图达到完美,而是试图达到平衡。 显式地声明哪些是目标,哪些是非目标,有助于帮助读者理解下文中设
总体设计
“我们如何解决这个问题?”
用一页描述高层设计。说明系统的主要组成部分,以及一些关键设计决策。应该说明该系统的模块和决策如何满足前文所列出的目标。
本设计文档的评审人应该能够根据该总体设计理解你的设计思路并做出评价。描述应该对一个新加入的、不在该项目工作的腾讯工程师而言是可以理解的。
推荐使用系统关系图描述设计。它可以使读者清晰地了解文中的新系统和已经熟悉的系统间的关系。它也可以包含新系统内部概要的组成模块。
注意:不要只放一个图而不做任何说明,请根据上面小节的要求用文字描述设计思想。
一个示例体统关系图
自举的文档结构图
可能不太好的顶层设计
不要在这里描述细节,放在下一章节中; 不要在这里描述背景,放在上一章节中。
详细设计
在这一节中,除了介绍设计方案的细节,还应该包括在产生最终方案过程中,主要的设计思想及权衡(tradeoff)。这一节的结构和内容因设计对象(系统,API,流程等)的不同可以自由决定,可以划分一些小节来更好地组织内容,尽可能以简洁明了的结构阐明整个设计。
不要过多写实现细节。就像我们不推荐添加只是说明”代码做了什么”的注释,我们也不推荐在设计文档中只说明你具体要怎么实现该系统。否则,为什么不直接实现呢? 以下内容可能是实现细节例子,不适合在设计文档中讨论:
- ** API 的所有细节 **
- ** 存储系统的 Data Schema **
- ** 具体代码或伪代码 **
- ** 该系统各模块代码的存放位置、各模块代码的布局 **
- ** 该系统使用的编译器版本 **
开发规范
通常可以包含以下内容(注意,小节的命名可以更改为更清晰体现内容的标题):
** 各子模块的设计 **
阐明一些复杂模块内部的细节,可以包含一些模块图、流程图来帮助读者理解。可以借助时序图进行展现,如一次调用在各子模块中的运行过程。每个子模块需要说明自己存在的意义。如无必要,勿添模块。如果没有特殊情况(例如该设计文档是为了描述并实现一个核心算法),不要在系统设计加入代码或者伪代码。
** API 接口 **
如果设计的系统会暴露 API 接口,那么简要地描述一下 API 会帮助读者理解系统的边界。避免将整个接口复制粘贴到文档中,因为在特定编程语言中的接口通常包含一些语言细节而显得冗长,并且有一些细节也会很快变化。着重表现 API 接口跟设计最相关的主要部分即可。
** 存储 **
介绍系统依赖的存储设计。该部分内容应该回答以下问题,如果答案并非显而易见:
该系统对数据/存储有哪些要求? - 该系统会如何使用数据? - 数据是什么类型的? - 数据规模有多大? - 读写比是多少?读写频率有多高? - 对可扩展性是否有要求? - 对原子性要求是什么? - 对一致性要求是什么?是否需要支持事务? - 对可用性要求是什么? - 对性能的要求是什么? - …………
基于上面的事实,数据库应该如何选型? - 选用关系型数据库还是非关系型数据库?是否有合适的中间件可以使用? - 如何分片?是否需要分库分表?是否需要副本? - 是否需要异地容灾? - 是否需要冷热分离? - …………
数据的抽象以及数据间关系的描述至关重要。可以借助 ER 图(Entity Relationshiop) 的方式展现数据关系。
回答上述问题时,尽可能提供数据,将数据作为答案或作为辅助。 不要回答“数据规模很大,读写频繁”,而是回答“预计数据规模为 300T, 3M 日读出, 0.3M 日写入, 巅峰 QPS 为 300”。这样才能为下一步的具体数据库造型提供详细的决策依据,并让读者信服。 注意:在选型时也应包括可能会造成显著影响的非技术因素,如费用。
避免将所有数据定义(data schema)复制粘贴到文档中,因为 data schema 更偏实现细节。
其他方案
“我们为什么不用另一种方式解决问题?”
在介绍了最终方案后,可以有一节介绍一下设计过程中考虑过的其他设计方案(Alternatives Considered)、它们各自的优缺点和权衡点、以及导致选择最终方案的原因等。通常,有经验的读者(尤其是方案的审阅者)会很自然地想到一些其他设计方案,如果这里的介绍描述了没有选择这些方案的原因,就避免读者带着疑问看完整个设计再来询问作者。这一节可以体现设计的严谨性和全面性。
交叉关注点
基础设施
如果基础设施的选用需要特殊考量,则应该列出。 如果该系统的实现需要对基础设施进行增强或变更,也应该在此讨论。
可扩展性
你的系统如何扩展?横向扩展还是纵向扩展?注意数据存储量和流量都可能会需要扩展。
安全 & 隐私
项目通常需要在设计期即确定对安全性的保证,而难以事后补足。不同于其它部分是可选的,安全部分往往是必需的。即使你的系统不需要考虑安全和隐私,也需要显式地在本章说明为何是不必要的。安全性如何保证?
系统如何授权、鉴权和审计(Authorization, Authentication and Auditing, AAA)?
是否需要破窗(break-glass)机制?
有哪些已知漏洞和潜在的不安全依赖关系?
是否应该与专业安全团队讨论安全性设计评审?
……
数据完整性
如何保证数据完整性(Data Integrity)?如何发现存储数据的损坏或丢失?如何恢复?由数据库保证即可,还是需要额外的安全措施?为了数据完整性,需要对稳定性、性能、可复用性、可维护性造成哪些影响?
延迟
声明延迟的预期目标。描述预期延迟可能造成的影响,以及相关的应对措施。
冗余 & 可靠性
是否需要容灾?是否需要过载保护、有损降级、接口熔断、轻重分离?是否需要备份?备份策略是什么?如何修复?在数据丢失和恢复之间会发生什么?
稳定性
SLA 目标是什么? 如果监控?如何保证?
外部依赖
你的外部依赖的可靠性(如 SLA)如何?会对你的系统的可靠性造成何种影响?如果你的外部依赖不可用,会对你的系统造成何种影响?除了服务级的依赖外,不要忘记一些隐含的依赖,如 DNS 服务、时间协议服务、运行集群等。
任务查分和研发排期
描述时间及人力安排(如里程碑)。 这利于相关人员了解预期,调整工作计划。
遗留的问题、未来计划
未来可能的计划会方便读者更好地理解该设计以及其定位。
技术设计基础
如何量化系统指标(SLA指标)
reliable

available
efficiency
latency and throughput
manageability

系统设计的权衡(top15 trade-off)
性能与可扩展性的权衡:提高性能可能需要牺牲一部分可扩展性,因为某些优化可能会引入复杂性或限制系统的扩展性。
可维护性与性能的权衡:某些优化措施可能会降低代码的可读性和可维护性,因此需要在维护性和性能之间进行权衡。
时间与成本的权衡:系统设计需要考虑开发时间和成本,以确保在给定资源限制下实现最佳的设计方案
安全性与用户体验的权衡:强大的安全措施可能会增加用户的身份验证和授权过程,从而影响用户体验。
架构权衡评估方法(ATAM):如何评估一个系统的质量
架构-trade-off(架构权衡
https://haomo-tech.com/project-docs/%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1%E6%96%87%E6%A1%A3/assets/%E7%B3%BB%E7%BB%9F%E4%B8%9A%E5%8A%A1%E6%9E%B6%E6%9E%84%E5%9B%BE.omnigraffle
架构-trade-off(架构权衡
架构权衡评估方法(ATAM):如何评估一个系统的质量
系统架构
面向对象系统设计的原则
单一职责原则(SRP):每个组件或模块应该具有单一的责任,降低耦合度,提高可维护性。
开闭原则(OCP):系统应对扩展开放,对修改关闭,通过接口和抽象来实现。
替换原则(LSP):子类应该能够替换其基类,而不会影响系统的正确性。
接口隔离原则(ISP):客户端不应该依赖于它不需要的接口,接口应该精简而专注。
依赖倒置原则(DIP):高层模块不应该依赖于低层模块,两者都应该依赖于抽象
SOLID 原则是一套比较经典且流行的架构原则(主要还是名字起得好):
单一职责:与 Unix 哲学所倡导的“Do one thing and do it well”不谋而合;
开闭原则:用新增(扩展)来取代修改(破坏现有封装),这与函数式的 immutable 思想也有异曲同工之妙;
里式替换:父类能够出现的地方子类一定能够出现,这样它们之间才算是具备继承的“Is-A”关系;
接口隔离:不要让一个类依赖另一个类中用不到的接口,简单说就是最小化组件之间的接口依赖和耦合;
依赖反转:依赖抽象类与接口,而不是具体实现;让低层次模块依赖高层次模块的稳定抽象,实现解耦
此外,我们做架构设计时也会尽量遵循如下一些原则(与上述 SOLID 原则在本质上也是相通的):
正交性:架构同一层次拆分出的各组件之间,应该尽量保持正交,即彼此职责独立,边界清晰,没有重叠;
高内聚:同一组件内部应该是高度内聚的(cohesive),像是一个不可分割的整体(否则就应该拆开);
低耦合:不同组件之间应该尽量减少耦合(coupling),既降低相互的变化影响,也能增强组件可复用性;
隔离变化:许多架构原则与模式的本质都是在隔离变化 —— 将预期可能变化的部分都隔离到一块,减少发生变化时受影响(需要修改代码、重新测试或产生故障隐患)的其他稳定部分
https://github.com/leewaiho/Clean-Architecture-zh/tree/master?tab=readme-ov-file
互联网系统八大谬论

- 网络是可靠的;
- 通信时延为0;
- 带宽是无限的;
- 网络是安全的;
- 拓扑不会改变;
- 只有一个管理者;
- 传输成本为0;
- 网络是同构的;
https://ably.com/blog/8-fallacies-of-distributed-computing
数学估算
延迟数
1 | Latency Comparison Numbers |
基于上述数字的指标:
- 从磁盘以 30 MB/s 的速度顺序读取
- 以 100 MB/s 从 1 Gbps 的以太网顺序读取
- 从 SSD 以 1 GB/s 的速度读取
- 以 4 GB/s 的速度从主存读取
- 每秒能绕地球 6-7 圈
- 数据中心内每秒有 2,000 次往返
traffic estimates

memory estimates

bandwidth estimates

storage estimates

系统设计核心概念
📌 𝐒𝐲𝐬𝐭𝐞𝐦 𝐃𝐞𝐬𝐢𝐠𝐧 𝐊𝐞𝐲 𝐂𝐨𝐧𝐜𝐞𝐩𝐭𝐬
- Scalability: lnkd.in/gpge_z76
- CAP Theorem: lnkd.in/g3hmVamx
- ACID Transactions: lnkd.in/gMe2JqaF
- Consistent Hashing: lnkd.in/gd3eAQKA
- Rate Limiting: lnkd.in/gWsTDR3m
- API Design: lnkd.in/ghYzrr8q
- Strong vs Eventual Consistency: lnkd.in/gJ-uXQXZ
- Synchronous vs. asynchronous communications: lnkd.in/g4EqcckR
- REST vs RPC: lnkd.in/gN__zcAB
- Batch Processing vs Stream Processing: lnkd.in/gaAnP_fT
- Fault Tolerance: lnkd.in/dVJ6n3wA
- Consensus Algorithms: lnkd.in/ggc3tFbr
- Gossip Protocol: lnkd.in/gfPMtrJZ
- Service Discovery: lnkd.in/gjnrYkyF
- Disaster Recovery: lnkd.in/g8rnr3V3
- Distributed Tracing: lnkd.in/d6r5RdXG
- Top 15 Tradeoffs: lnkd.in/gnM8QC-z
🛠️ 𝐒𝐲𝐬𝐭𝐞𝐦 𝐃𝐞𝐬𝐢𝐠𝐧 𝐁𝐮𝐢𝐥𝐝𝐢𝐧𝐠 𝐁𝐥𝐨𝐜𝐤𝐬
- Horizontal vs Vertical Scaling: lnkd.in/gAH2e9du
- Databases: lnkd.in/gti8gjpz
- Content Delivery Network (CDN): lnkd.in/gjJrEJeH
- Domain Name System (DNS): lnkd.in/gkMcZW8V
- Caching: lnkd.in/gC9piQbJ
- Distributed Caching: lnkd.in/g7WKydNg
- Load Balancing: lnkd.in/gQaa8sXK
- SQL vs NoSQL: lnkd.in/g3WC_yxn
- Database Indexes: lnkd.in/dGnZiNmM
- HeartBeats: lnkd.in/gfb9-hpN
- Circuit Breaker: lnkd.in/gCxyFzKm
- Idempotency: lnkd.in/gPm6EtKJ
- Database Scaling: lnkd.in/gAXpSyWQ
- Data Replication: lnkd.in/gVAJxTpS
- Data Redundancy: lnkd.in/gNN7TF7n
- Database Sharding: lnkd.in/gRHb-67m
- Failover: lnkd.in/dihZ-cEG
- Proxy Server: lnkd.in/gi8KnKS6
- Message Queues: lnkd.in/gTzY6uk8
- WebSockets: lnkd.in/g76Gv2KQ
- Bloom Filters: lnkd.in/dt4QbSUz
- API Gateway: lnkd.in/gnsJGJaM
- Distributed Locking: lnkd.in/gRxNJwWE
- Checksum: lnkd.in/gCTa4DrS
🖇️ 𝐒𝐲𝐬𝐭𝐞𝐦 𝐃𝐞𝐬𝐢𝐠𝐧 𝐀𝐫𝐜𝐡𝐢𝐭𝐞𝐜𝐭𝐮𝐫𝐚𝐥 𝐏𝐚𝐭𝐭𝐞𝐫𝐧𝐬
- Client-Server Architecture: lnkd.in/dAARQYzq
- Microservices Architecture: lnkd.in/gFXUrz_T
- Serverless Architecture: lnkd.in/gQNAXKkb
- Event-Driven Architecture: lnkd.in/dp8CPvey
- Peer-to-Peer (P2P) Architecture: lnkd.in/di32HDu3
整体架构设计
软件架构模式(patterns)
Application Landscape Patterns
- Monolith (单体架构)
- N-tiers,3-tier
- 面向服务的架构 (service - orienterd)
- 微服务架构 (microservices)
- 无服务架构 (serverless)
- p2p 架构 (peer to peer)
Application structure Patterns
- 分层架构 (Layerd architecture)
- 微内核架构 (microkernel)
- 事件驱动架构 (Event-driven)
User Interface Patterns
- MVC
- MVP
参考阅读:
架构 EA+4A
什么是架构 EA+4A
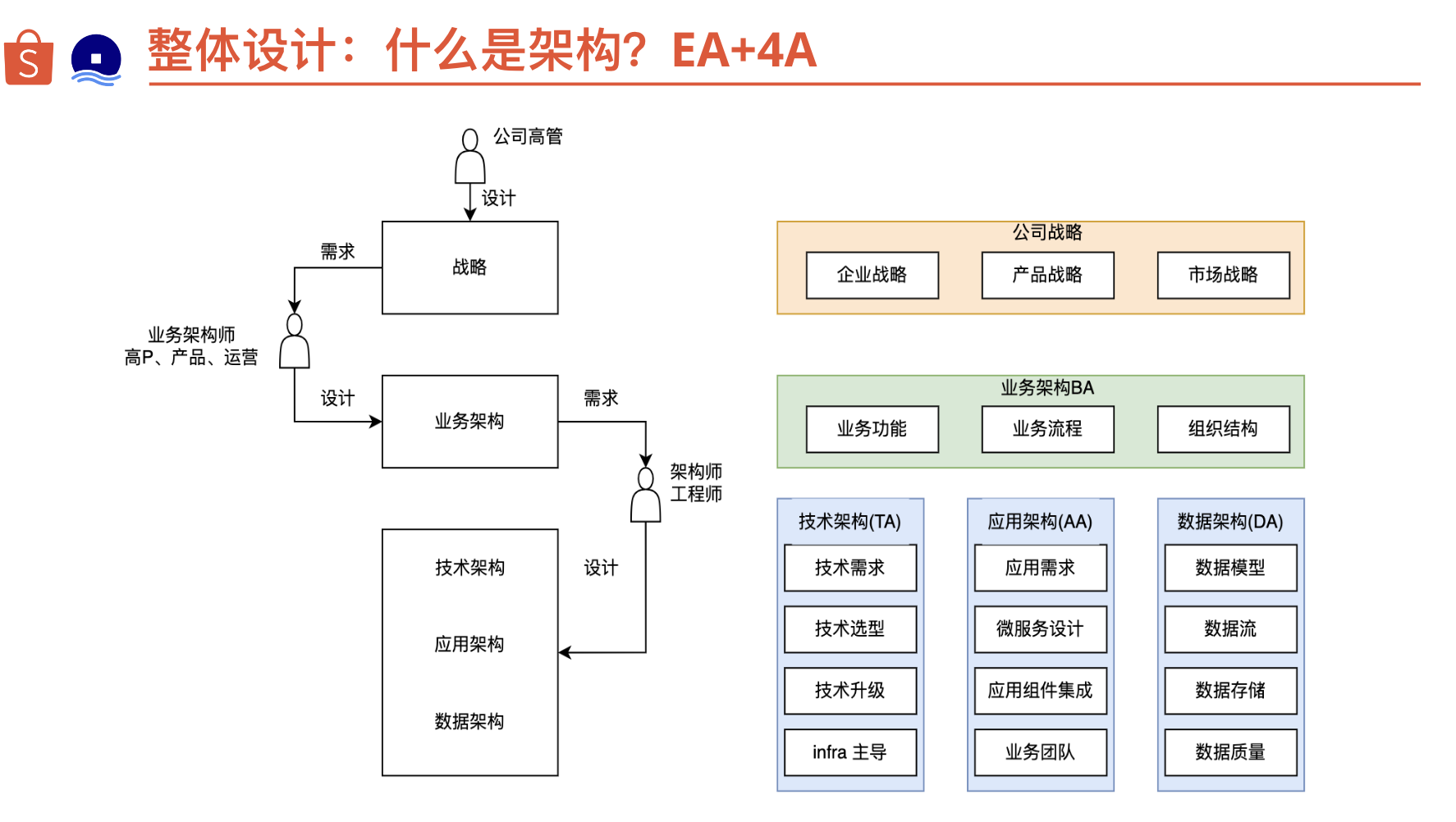
业务架构
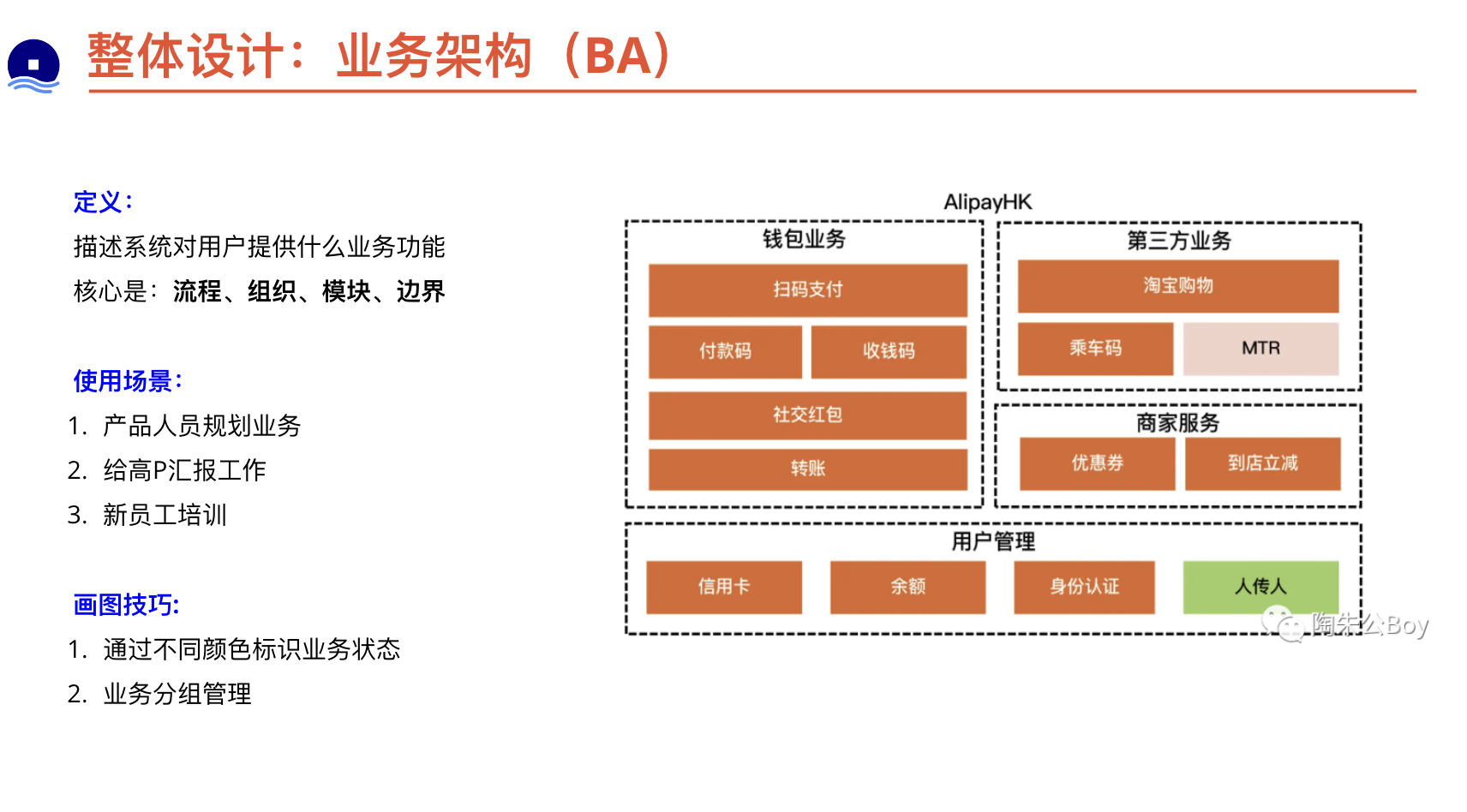
应用架构
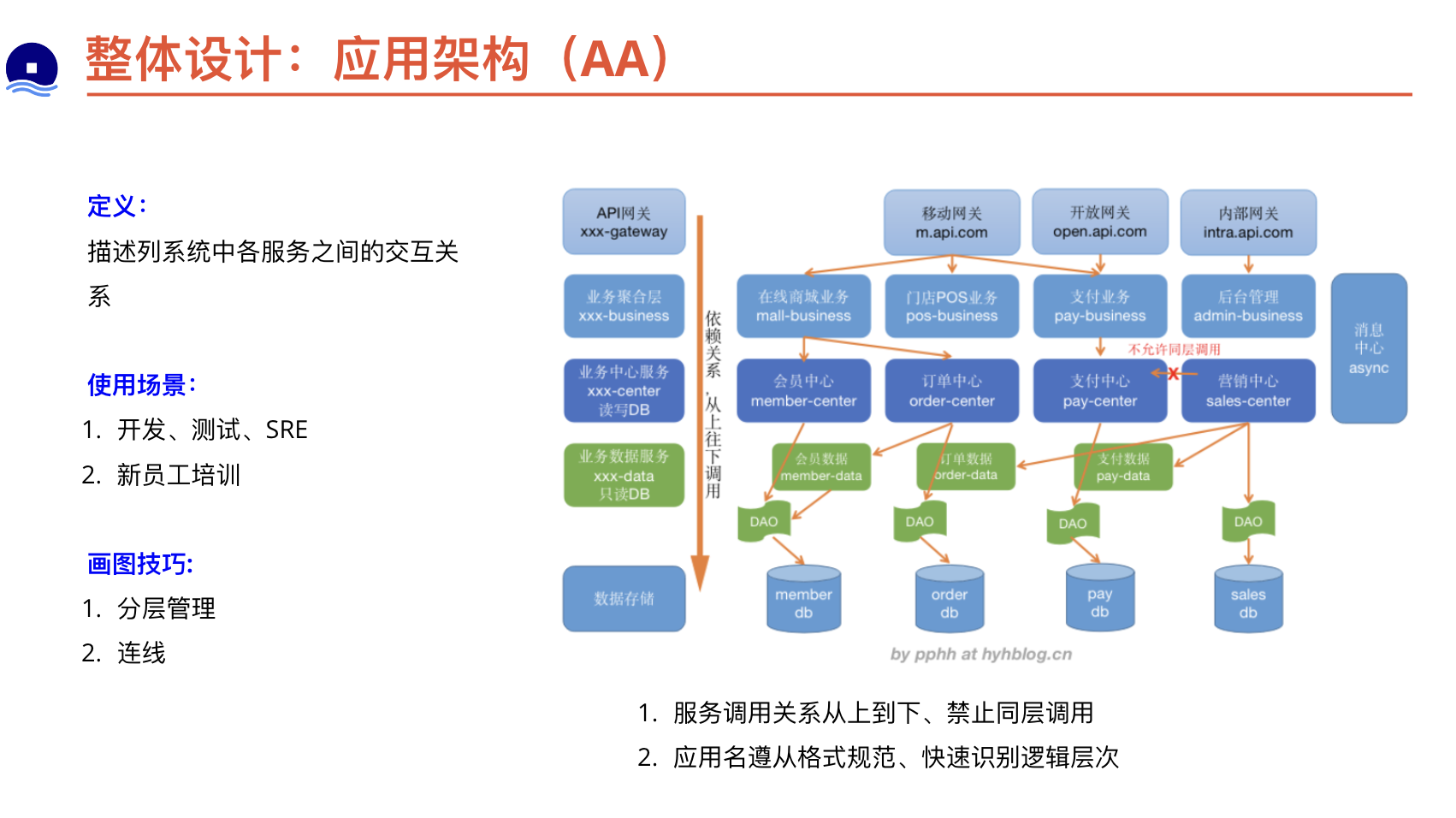
技术架构
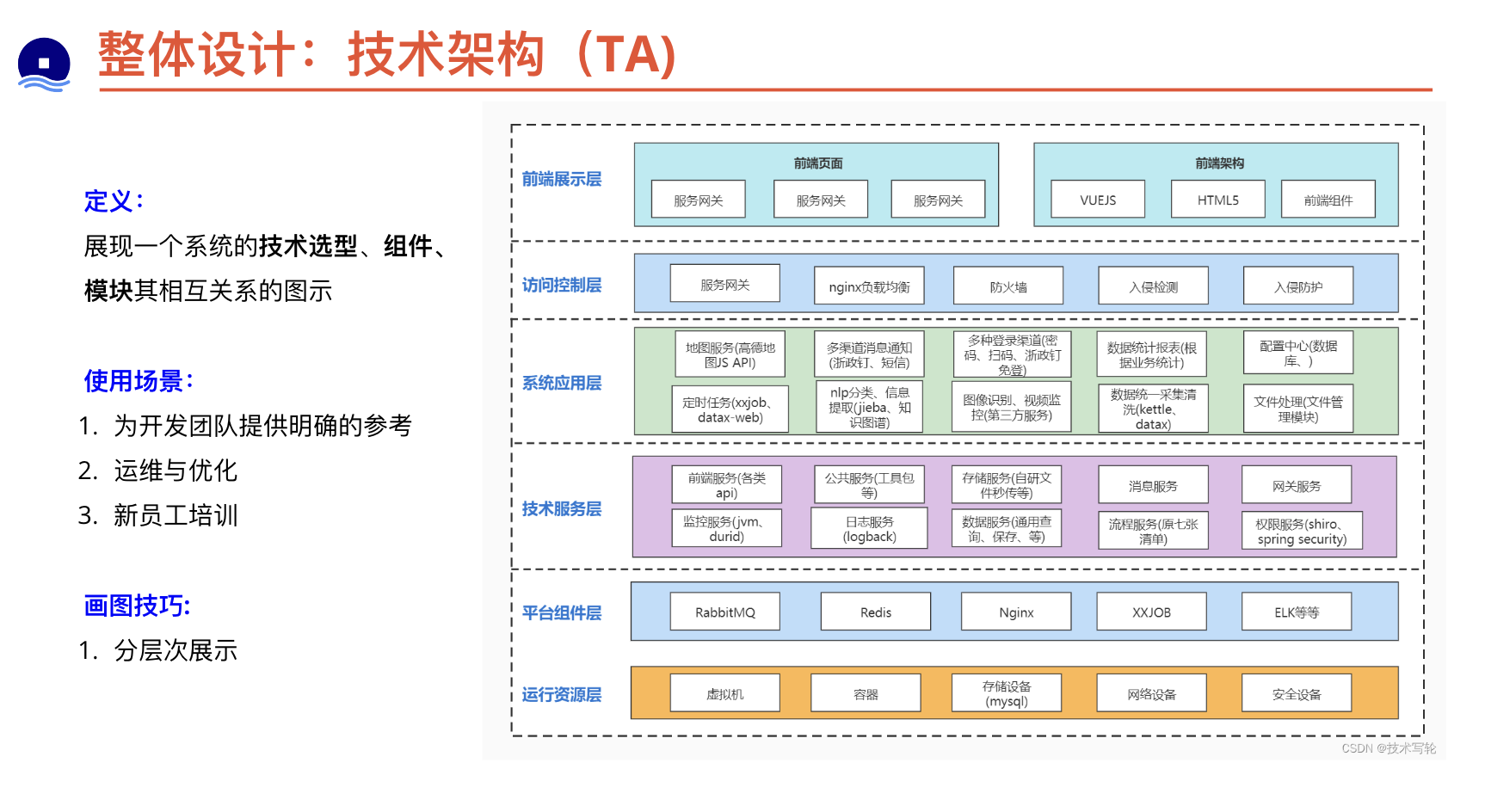
数据架构
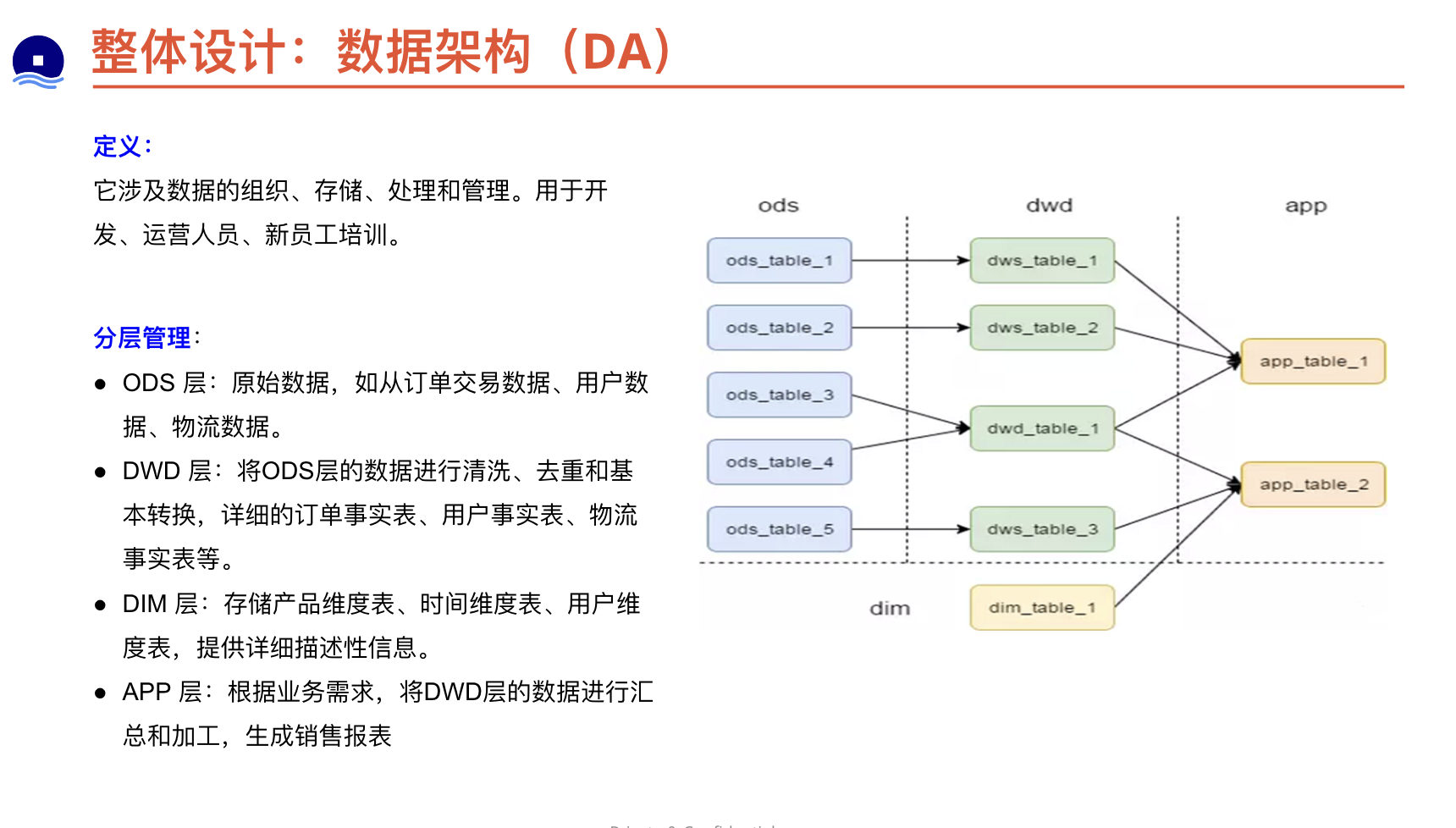
架构设计原则

扩展阅读
微服务架构
单体服务、微服务、Service Mesh
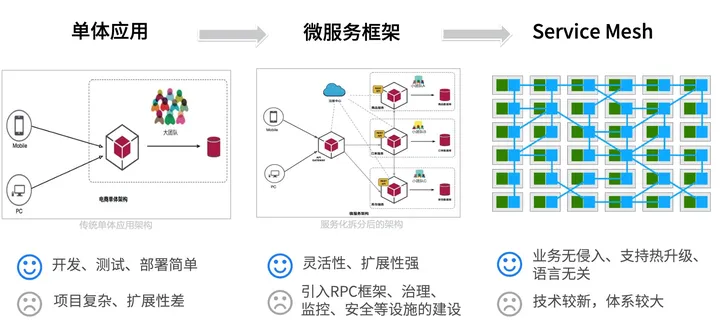
单体服务(Monolithic Services):单体服务是指将整个应用程序作为一个单一的、紧密耦合的单元进行开发、部署和运行的架构模式。在单体服务中,应用程序的各个功能模块通常运行在同一个进程中,并共享相同的数据库和资源。单体服务的优点是开发简单、部署方便,但随着业务规模的增长,单体服务可能变得庞大且难以维护。
微服务(Microservices):微服务是一种将应用程序拆分为一组小型、独立部署的服务的架构模式。每个微服务都专注于单个业务功能,并通过轻量级的通信机制(如RESTful API或消息队列)进行相互通信。微服务的优点是灵活性高、可扩展性好,每个微服务可以独立开发、测试、部署和扩展。然而,微服务架构也带来了分布式系统的复杂性和管理的挑战。
Service Mesh:Service Mesh是一种用于解决微服务架构中服务间通信和治理问题的基础设施层。它通过在服务之间插入一个专用的代理(称为Sidecar)来提供服务间的通信、安全性、可观察性和弹性的功能。Service Mesh可以提供流量管理、负载均衡、故障恢复、安全认证、监控和追踪等功能,而不需要在每个微服务中显式实现这些功能。常见的Service Mesh实现包括Istio、Linkerd和Consul Connect等。
微服务

与此讨论相关的话题是 微服务,可以被描述为一系列可以独立部署的小型的,模块化服务。每个服务运行在一个独立的线程中,通过明确定义的轻量级机制通讯,共同实现业务目标。1例如,Pinterest 可能有这些微服务: 用户资料、关注者、Feed 流、搜索、照片上传等。
服务发现
ZooKeeper
- ZooKeeper是一个开源的分布式协调服务,最初由雅虎开发并后来成为Apache软件基金会的顶级项目。
- ZooKeeper提供了一个分布式的、高可用的、强一致性的数据存储服务。它的设计目标是为构建分布式系统提供可靠的协调机制。
- ZooKeeper使用基于ZAB(ZooKeeper Atomic Broadcast)协议的一致性算法来保证数据的一致性和可靠性。
- ZooKeeper提供了一个类似于文件系统的层次化命名空间(称为ZNode),可以存储和管理数据,并支持对数据的读写操作。
- ZooKeeper还提供了一些特性,如临时节点、顺序节点和观察者机制,用于实现分布式锁、选举算法和事件通知等。
etcd
etcd是一个开源的分布式键值存储系统,由CoreOS开发并后来成为Cloud Native Computing Foundation(CNCF)的项目之一。
etcd被设计为一个高可用、可靠的分布式存储系统,用于存储和管理关键的配置数据和元数据。
etcd使用Raft一致性算法来保证数据的一致性和可靠性,Raft是一种强一致性的分布式共识算法。
etcd提供了一个简单的键值存储接口,可以存储和检索键值对数据,并支持对数据的原子更新操作。
etcd还提供了一些高级特性,如目录结构、事务操作和观察者机制,用于构建复杂的分布式系统和应用
Service Mesh

远程过程调用协议(RPC)
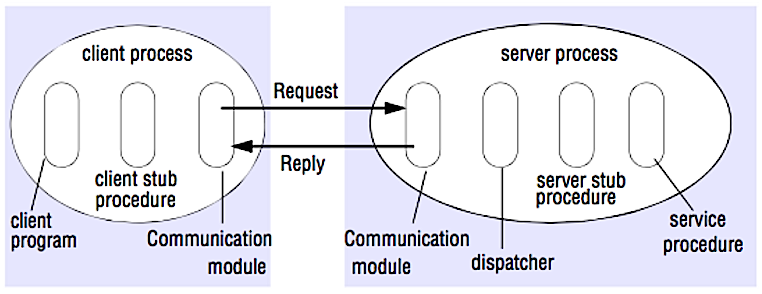
Source: Crack the system design interview
在 RPC 中,客户端会去调用另一个地址空间(通常是一个远程服务器)里的方法。调用代码看起来就像是调用的是一个本地方法,客户端和服务器交互的具体过程被抽象。远程调用相对于本地调用一般较慢而且可靠性更差,因此区分两者是有帮助的。热门的 RPC 框架包括 Protobuf、Thrift 和 Avro。
RPC 是一个“请求-响应”协议:
- 客户端程序 ── 调用客户端存根程序。就像调用本地方法一样,参数会被压入栈中。
- 客户端 stub 程序 ── 将请求过程的 id 和参数打包进请求信息中。
- 客户端通信模块 ── 将信息从客户端发送至服务端。
- 服务端通信模块 ── 将接受的包传给服务端存根程序。
- 服务端 stub 程序 ── 将结果解包,依据过程 id 调用服务端方法并将参数传递过去。
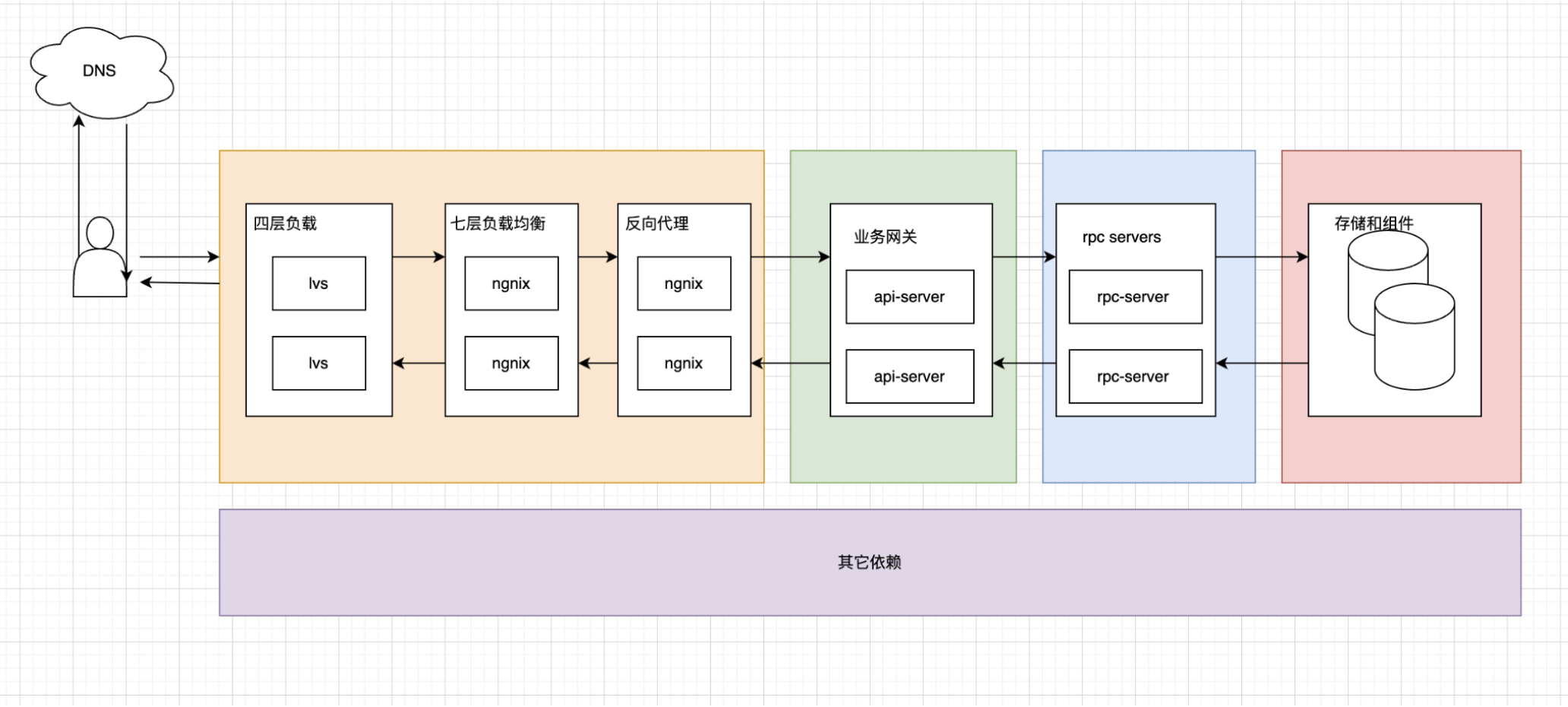
接入层设计:域名/代理/负载均衡
域名系统
Amazon Route 53域名系统
### 域名解析的过程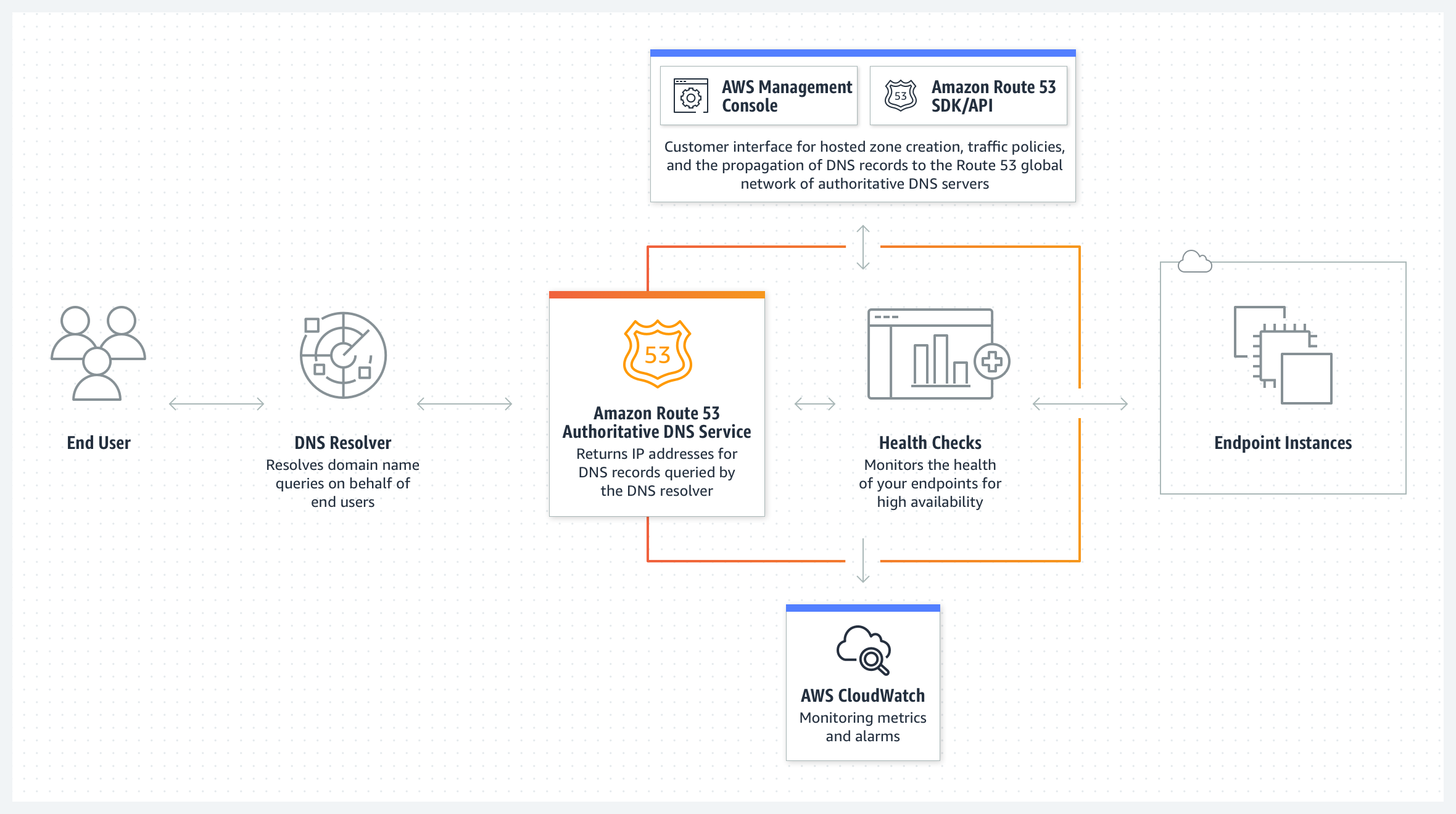
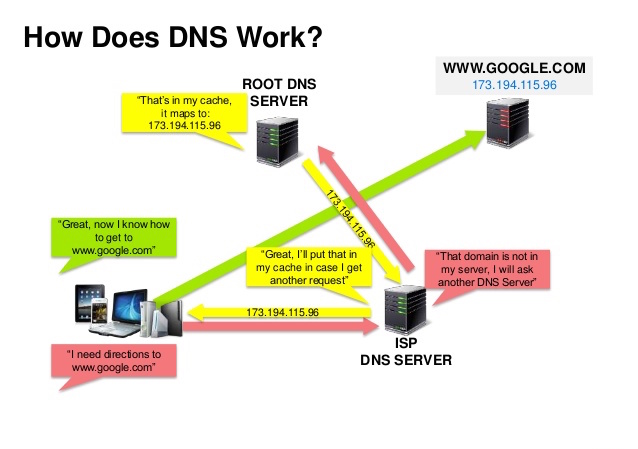
域名系统是把 www.example.com 等域名转换成 IP 地址。域名系统是分层次的,一些 DNS 服务器位于顶层。当查询(域名) IP 时,路由或 ISP 提供连接 DNS 服务器的信息。较底层的 DNS 服务器缓存映射,它可能会因为 DNS 传播延时而失效。DNS 结果可以缓存在浏览器或操作系统中一段时间,时间长短取决于存活时间 TTL。
- A 记录(地址) ─ 指定域名对应的 IP 地址记录。
- CNAME(规范) ─ 一个域名映射到另一个域名或
CNAME记录( example.com 指向 www.example.com )或映射到一个A记录。 - NS 记录(域名服务) ─ 指定解析域名或子域名的 DNS 服务器。
- MX 记录(邮件交换) ─ 指定接收信息的邮件服务.
域名管理服务
常用命令
- nslookup
- dig
来源及延伸阅读
代理+负载均衡器
正向forward proxy
反向reverse proxy
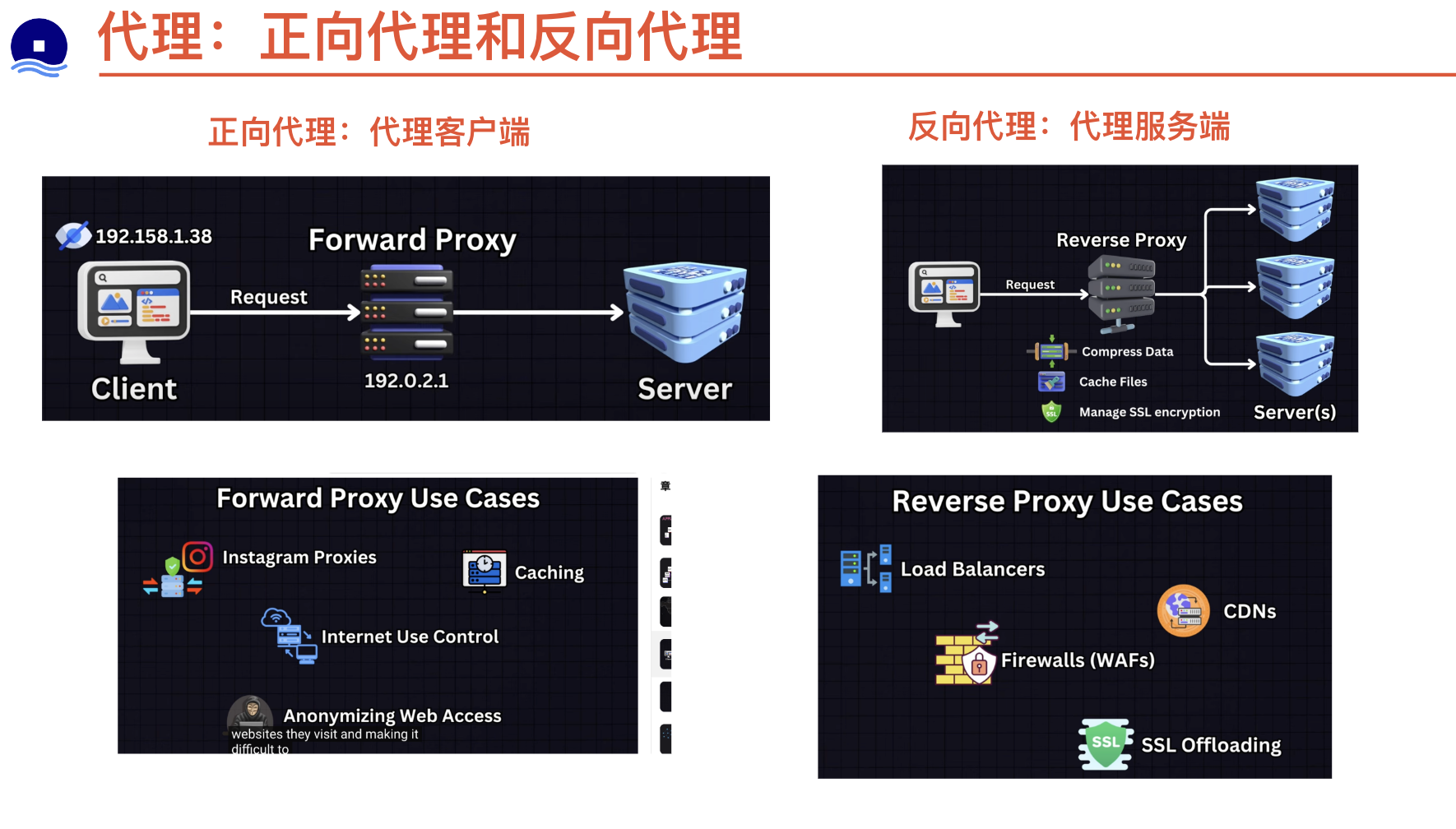
负载均衡器和反向代理
负载均衡器将传入的请求分发到应用服务器和数据库等计算资源。无论哪种情况,负载均衡器将从计算资源来的响应返回给恰当的客户端。负载均衡器的效用在于:
- 防止请求进入不好的服务器
- 防止资源过载
- 帮助消除单一的故障点
- SSL 终结 ─ 解密传入的请求并加密服务器响应,这样的话后端服务器就不必再执行这些潜在高消耗运算了。
- 不需要再每台服务器上安装 X.509 证书。
- Session 留存 ─ 如果 Web 应用程序不追踪会话,发出 cookie 并将特定客户端的请求路由到同一实例。
- 通常会设置采用工作─备用 或 双工作 模式的多个负载均衡器,以免发生故障。
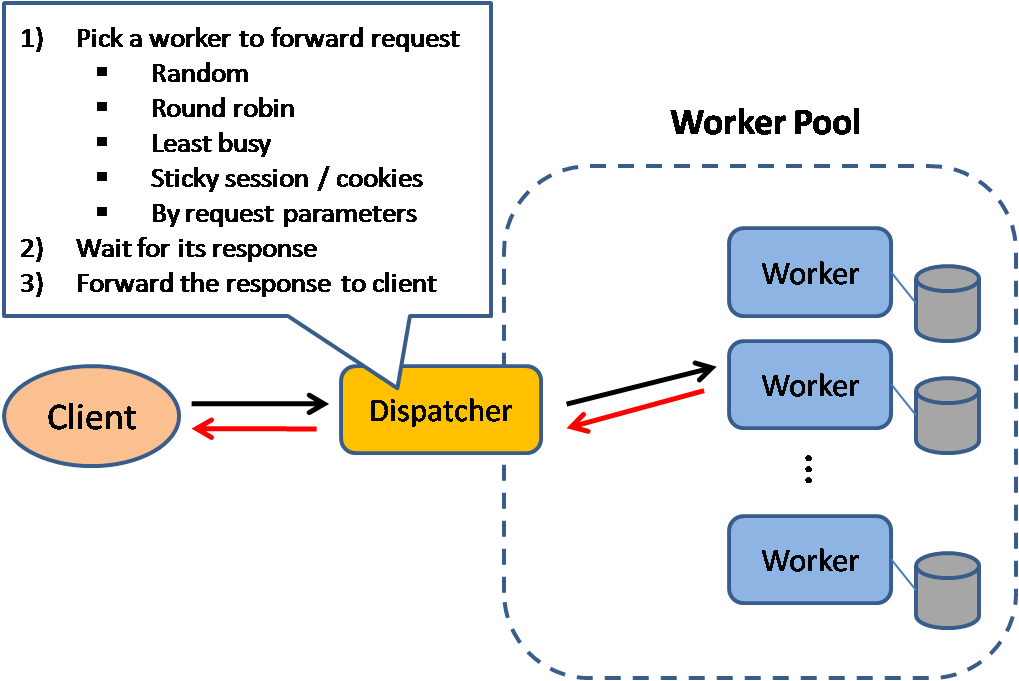
负载均衡器能基于多种方式来路由流量:
- 随机
- 最少负载
- Session/cookie
- 轮询调度或加权轮询调度算法
- 四层负载均衡
- 七层负载均衡
四层负载均衡
四层负载均衡根据监看传输层的信息来决定如何分发请求。通常,这会涉及来源,目标 IP 地址和请求头中的端口,但不包括数据包(报文)内容。四层负载均衡执行网络地址转换(NAT)来向上游服务器转发网络数据包。
七层负载均衡器
七层负载均衡器根据监控应用层来决定怎样分发请求。这会涉及请求头的内容,消息和 cookie。七层负载均衡器终结网络流量,读取消息,做出负载均衡判定,然后传送给特定服务器。比如,一个七层负载均衡器能直接将视频流量连接到托管视频的服务器,同时将更敏感的用户账单流量引导到安全性更强的服务器。
以损失灵活性为代价,四层负载均衡比七层负载均衡花费更少时间和计算资源,虽然这对现代商用硬件的性能影响甚微。
水平扩展
负载均衡器还能帮助水平扩展,提高性能和可用性。使用商业硬件的性价比更高,并且比在单台硬件上垂直扩展更贵的硬件具有更高的可用性。相比招聘特定企业系统人才,招聘商业硬件方面的人才更加容易。
缺陷:水平扩展
- 水平扩展引入了复杂度并涉及服务器复制
- 服务器应该是无状态的:它们也不该包含像 session 或资料图片等与用户关联的数据。
- session 可以集中存储在数据库或持久化缓存(Redis、Memcached)的数据存储区中。
- 缓存和数据库等下游服务器需要随着上游服务器进行扩展,以处理更多的并发连接。
缺陷:负载均衡器
- 如果没有足够的资源配置或配置错误,负载均衡器会变成一个性能瓶颈。
- 引入负载均衡器以帮助消除单点故障但导致了额外的复杂性。
- 单个负载均衡器会导致单点故障,但配置多个负载均衡器会进一步增加复杂性。
反向代理(web 服务器)
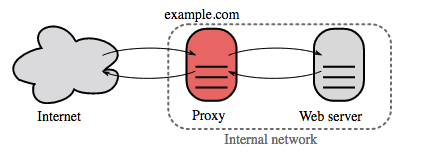
反向代理是一种可以集中地调用内部服务,并提供统一接口给公共客户的 web 服务器。来自客户端的请求先被反向代理服务器转发到可响应请求的服务器,然后代理再把服务器的响应结果返回给客户端。
带来的好处包括:
- 增加安全性 - 隐藏后端服务器的信息,屏蔽黑名单中的 IP,限制每个客户端的连接数。
- 提高可扩展性和灵活性 - 客户端只能看到反向代理服务器的 IP,这使你可以增减服务器或者修改它们的配置。
- 本地终结 SSL 会话 - 解密传入请求,加密服务器响应,这样后端服务器就不必完成这些潜在的高成本的操作。免除了在每个服务器上安装 X.509 证书的需要
- 压缩 - 压缩服务器响应
- 缓存 - 直接返回命中的缓存结果
- 静态内容 - 直接提供静态内容
- HTML/CSS/JS
- 图片
- 视频
- 等等
负载均衡器与反向代理
- 当你有多个服务器时,部署负载均衡器非常有用。通常,负载均衡器将流量路由给一组功能相同的服务器上。
- 即使只有一台 web 服务器或者应用服务器时,反向代理也有用,可以参考上一节介绍的好处。
- NGINX 和 HAProxy 等解决方案可以同时支持第七层反向代理和负载均衡。
不利之处:反向代理
- 引入反向代理会增加系统的复杂度。
- 单独一个反向代理服务器仍可能发生单点故障,配置多台反向代理服务器(如故障转移)会进一步增加复杂度。
来源及延伸阅读
- 反向代理与负载均衡
- NGINX 架构
- HAProxy 架构指南
- Wikipedia
- NGINX 架构
- HAProxy 架构指南
- 可扩展性
- Wikipedia
- 四层负载平衡
- 七层负载平衡
- ELB 监听器配置
应用层web网关设计
将 Web 服务层与应用层(也被称作平台层)分离,可以独立缩放和配置这两层。添加新的 API 只需要添加应用服务器,而不必添加额外的 web 服务器。用于完成基础的:
- 参数校验
- 协议转换等
- 鉴权
- 限流
- 监控、日志
- 熔断(错误率较高时,熔断机制)
- 降级策略(比如电商搜索时正常情况下提供搜索+个性化服务,高负载时仅提供搜索服务,非核心功能降级)
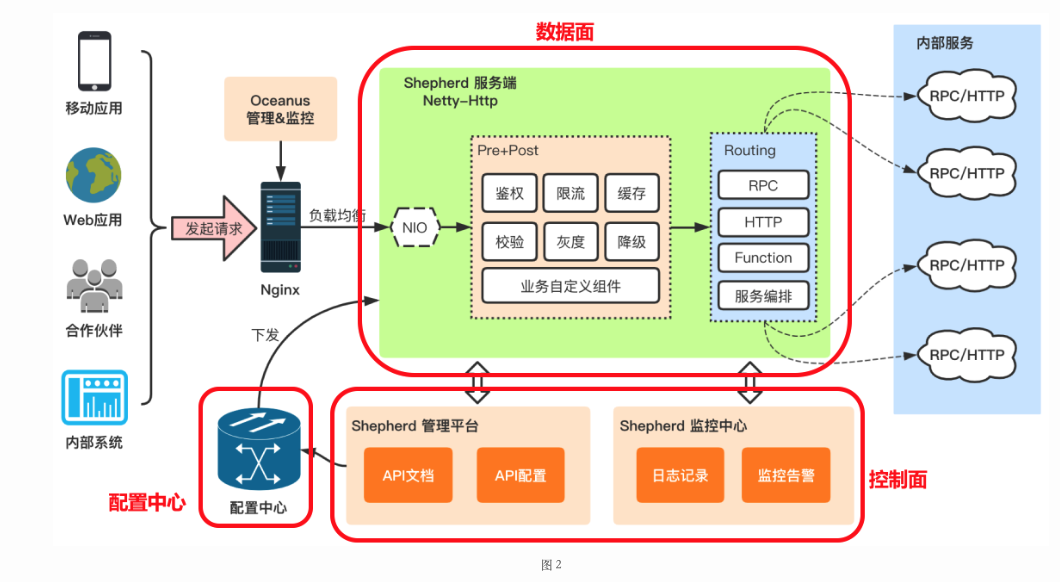
- Shopee Games API 网关设计与实现
- 百亿规模API网关服务Shepherd的设计与实现
- grpc-gateway
API 设计规范和管理
API 架构风格
- RESTful API
- GraphQL
- RPC
- SOA
RESTful API
路径名称避免动词
1
2
3
4
5路径名称避免动词
# Good
curl -X GET /orders
# Bad
curl -X GET /getOrdersGET 获取指定 URI 的资源信息
1
2
3
4
5
6
7# 代表获取当前系统的所有订单信息
curl -X GET /orders
curl -X GET /users/{user_id}/orders
# 代表获取指定订单编号为订单详情信息
curl -X GET /orders/{order_id}POST 通过指定的 URI 创建资源
1
2curl -X POST /orders \
-d '{"name": "awesome", region: "A"}' \PUT 创建或全量替换指定 URI 上的资源
1
2curl -X PUT http://httpbin.org/orders/1 \
-d '{"name": "new awesome", region: "B"}' \PATCH 执行一个资源的部分更新
1
2
3
4
5# 代表将 id 为 1 的 order 中的 region 字段进行更改,其他数据保持不变
curl -X PATCH /orders/{order_id} \
-d '{name: "nameB"}' \
curl -X order/{order_id}/name (用来重命名)
curl -X /order/{order_id}/status(用来更改用户状态)DELETE 通过指定的 URI 移除资源
1
2# 代表将id的 order 删除
curl -X DELETE /orders/{order_id}
其它规则:
规则1:应使用连字符( - )来提高URI的可读性
规则2:不得在URI中使用下划线(_)
规则3:URI路径中全都使用小写字母
API 错误码设计规范
- 不论请求成功或失败,始终返回 200 http status code,在 HTTP Body 中包含用户账号没有找到的错误信息:
1 | 如: Facebook API 的错误 Code 设计,始终返回 200 http status code: |
- 返回 http 404 Not Found 错误码,并在 Body 中返回简单的错误信息:
1 | 如: Twitter API 的错误设计 |
- 返回 http 404 Not Found 错误码,并在 Body 中返回详细的错误信息:
1 | 如: 微软 Bing API 的错误设计,会根据错误类型,返回合适的 HTTP Code,并在 Body 中返回详尽的错误信息 |
- 业务 Code 码设计
- 纯数字表示
- 不同部位代表不同的服务
- 不同的模块(品类)
1 | 如: 错误代码说明:100101 |
接口幂等性设计
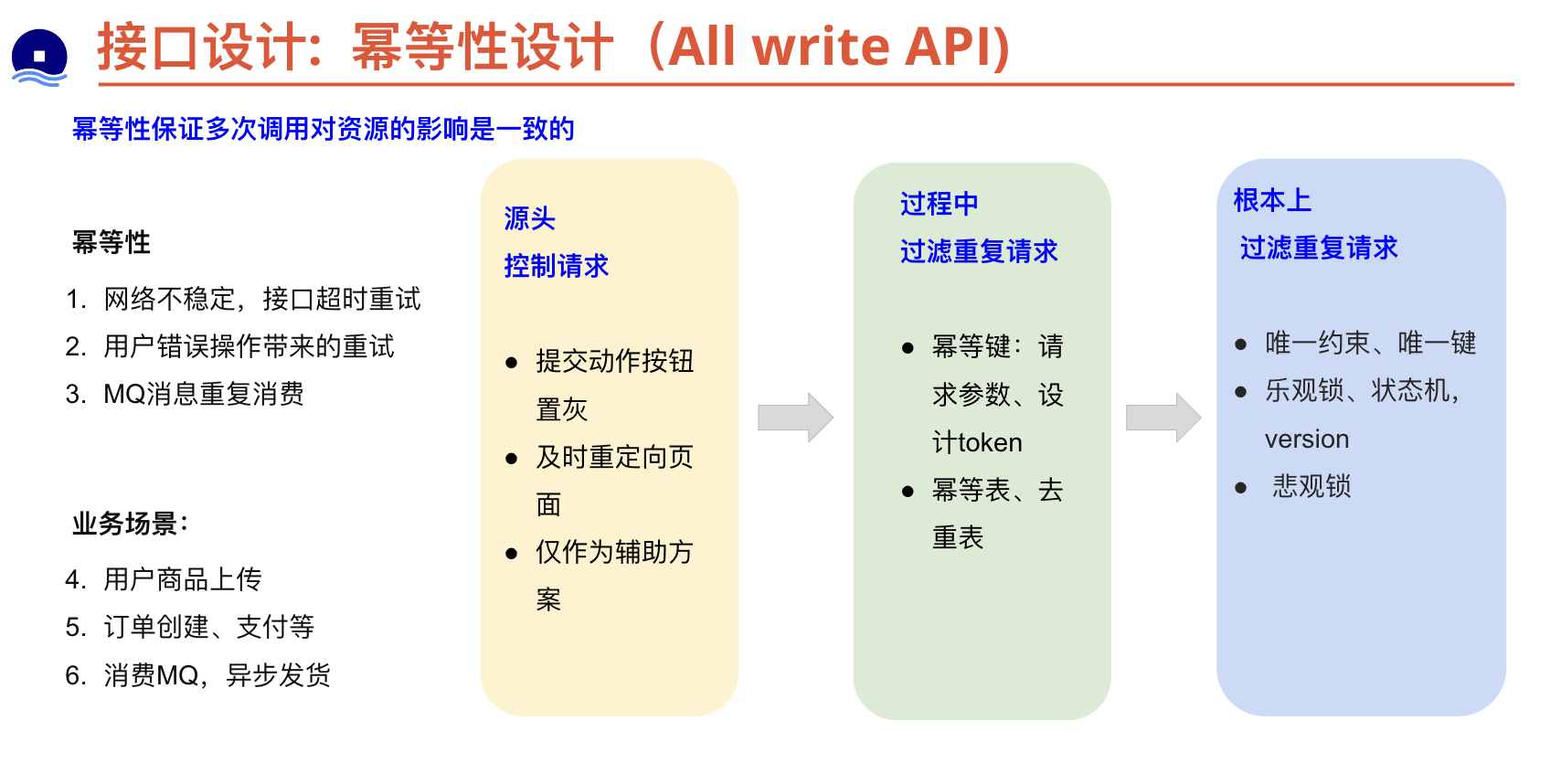
幂等性的重要性
- 提高可靠性:在网络不稳定的情况下,客户端可能会重试请求。幂等性确保重复请求不会导致意外的副作用。
- 简化客户端代码:客户端不需要担心重复请求的副作用,从而简化了错误处理逻辑。
- 改善用户体验:确保用户操作的可预测性,避免因重复提交表单等操作导致的错误或重复数据。
怎么实现幂等性
- 幂等键(Idempotency Key: 由客户端生成一个唯一标识请求的ID,并在请求头中包含此ID。服务器端会检查此ID是否已处理过,如果是,则返回之前的响应。
- 幂等令牌(Idempotency Token):在需要创建资源的请求中,通过幂等令牌保证幂等性。服务器端生成并验证令牌,确保同一令牌只能创建一个资源
中间件和存储
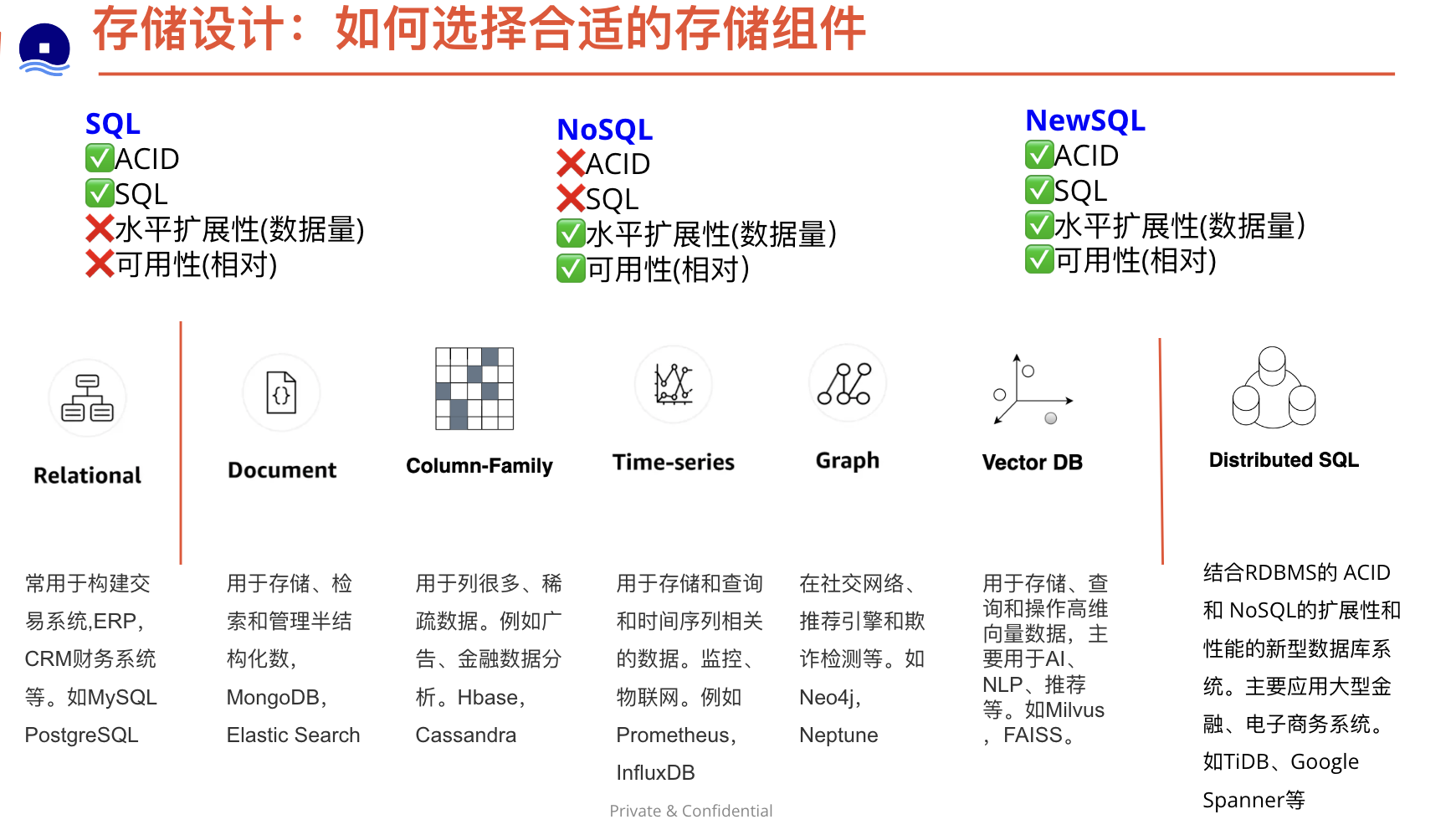
如何选择存储组件
内容分发网络(CDN)
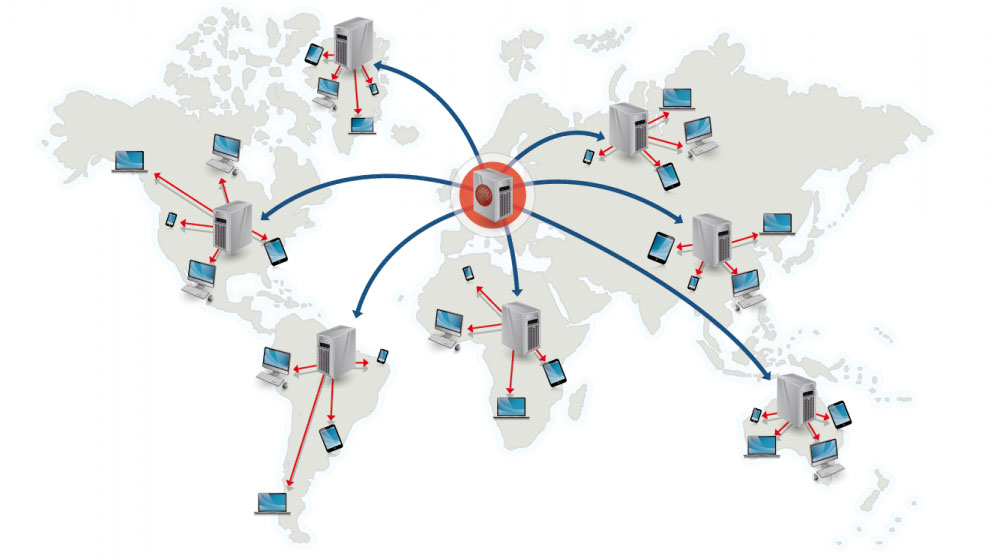
内容分发网络(CDN)是一个全球性的代理服务器分布式网络,它从靠近用户的位置提供内容。通常,HTML/CSS/JS,图片和视频等静态内容由 CDN 提供,虽然亚马逊 CloudFront 等也支持动态内容。CDN 的 DNS 解析会告知客户端连接哪台服务器。
将内容存储在 CDN 上可以从两个方面来提供性能:
- 从靠近用户的数据中心提供资源
- 通过 CDN 你的服务器不必真的处理请求
CDN 推送(push)
当你服务器上内容发生变动时,推送 CDN 接受新内容。直接推送给 CDN 并重写 URL 地址以指向你的内容的 CDN 地址。你可以配置内容到期时间及何时更新。内容只有在更改或新增是才推送,流量最小化,但储存最大化。
CDN 拉取(pull)
CDN 拉取是当第一个用户请求该资源时,从服务器上拉取资源。你将内容留在自己的服务器上并重写 URL 指向 CDN 地址。直到内容被缓存在 CDN 上为止,这样请求只会更慢,
存活时间(TTL)决定缓存多久时间。CDN 拉取方式最小化 CDN 上的储存空间,但如果过期文件并在实际更改之前被拉取,则会导致冗余的流量。
高流量站点使用 CDN 拉取效果不错,因为只有最近请求的内容保存在 CDN 中,流量才能更平衡地分散。
缺陷:CDN
- CDN 成本可能因流量而异,可能在权衡之后你将不会使用 CDN。
- 如果在 TTL 过期之前更新内容,CDN 缓存内容可能会过时。
- CDN 需要更改静态内容的 URL 地址以指向 CDN。
来源及延伸阅读
mysql 数据库
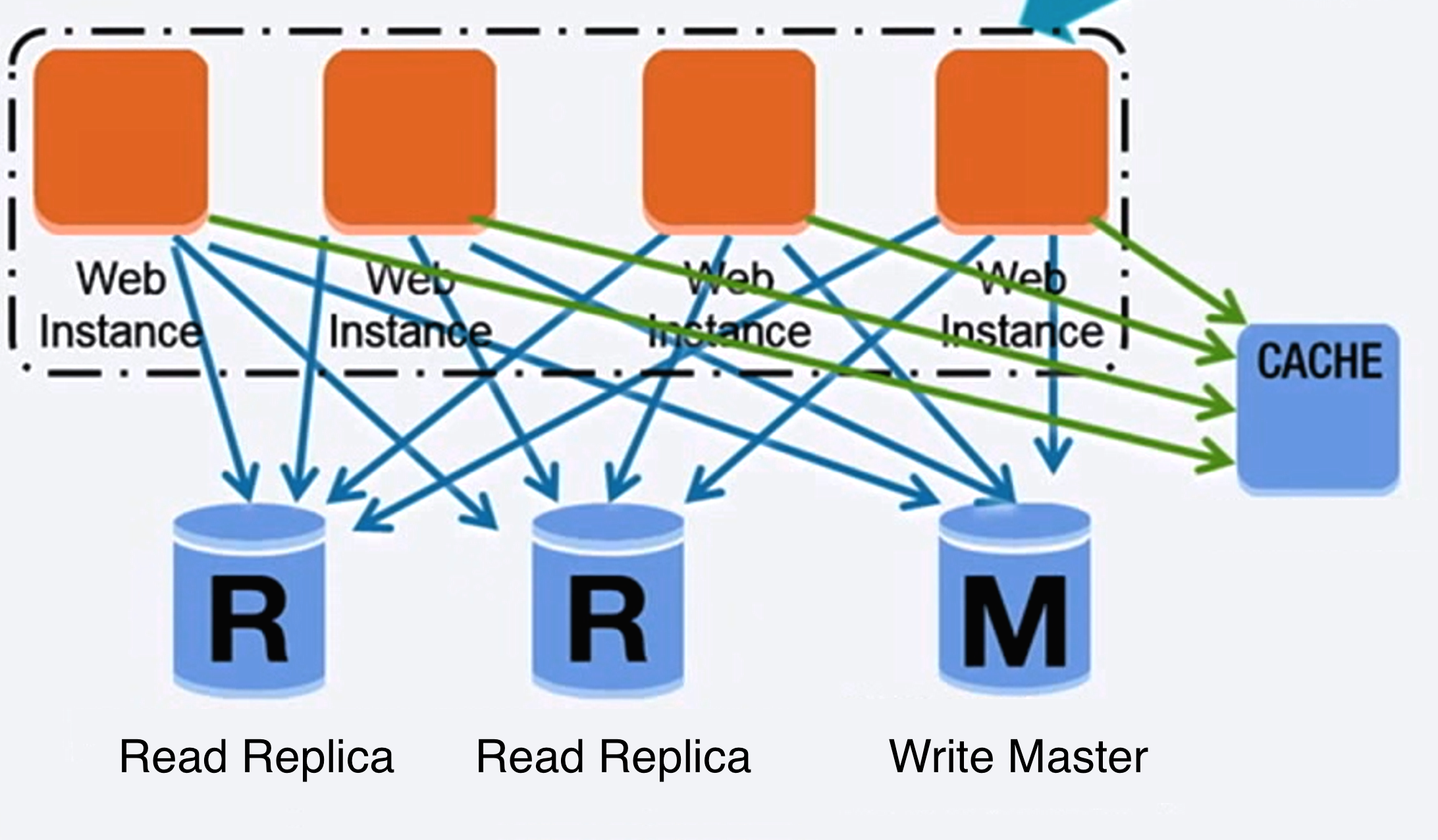
延伸思考和学习
- 如何正确建表。类型选择、主键约束、not null、编码方式等
- 外建约束、还是业务约束
- mysql join 还是业务关联等
- 如何使用index优化查询
- 如何使用事物acid
- DDL注意事项
- 是否需呀分库分表
- 历史数据如何处理
- 如何扩展mysql?垂直分、水平分、主备复制、主主复制
- 性能调优?架构优化、索引优化、sql优化、连接池优化、缓存优化
redis 键值存储系统

延伸思考和学习
- redis 五种数据结构
- redis 使用场景。缓存数据、计数器和限流、分布式锁、bloomfilter等
- redis key 过期时间
- redis 存储数据一致性的容忍度
- redis 扩展和分不少方案
- redis 热key和大key问题
文档类型存储(es)
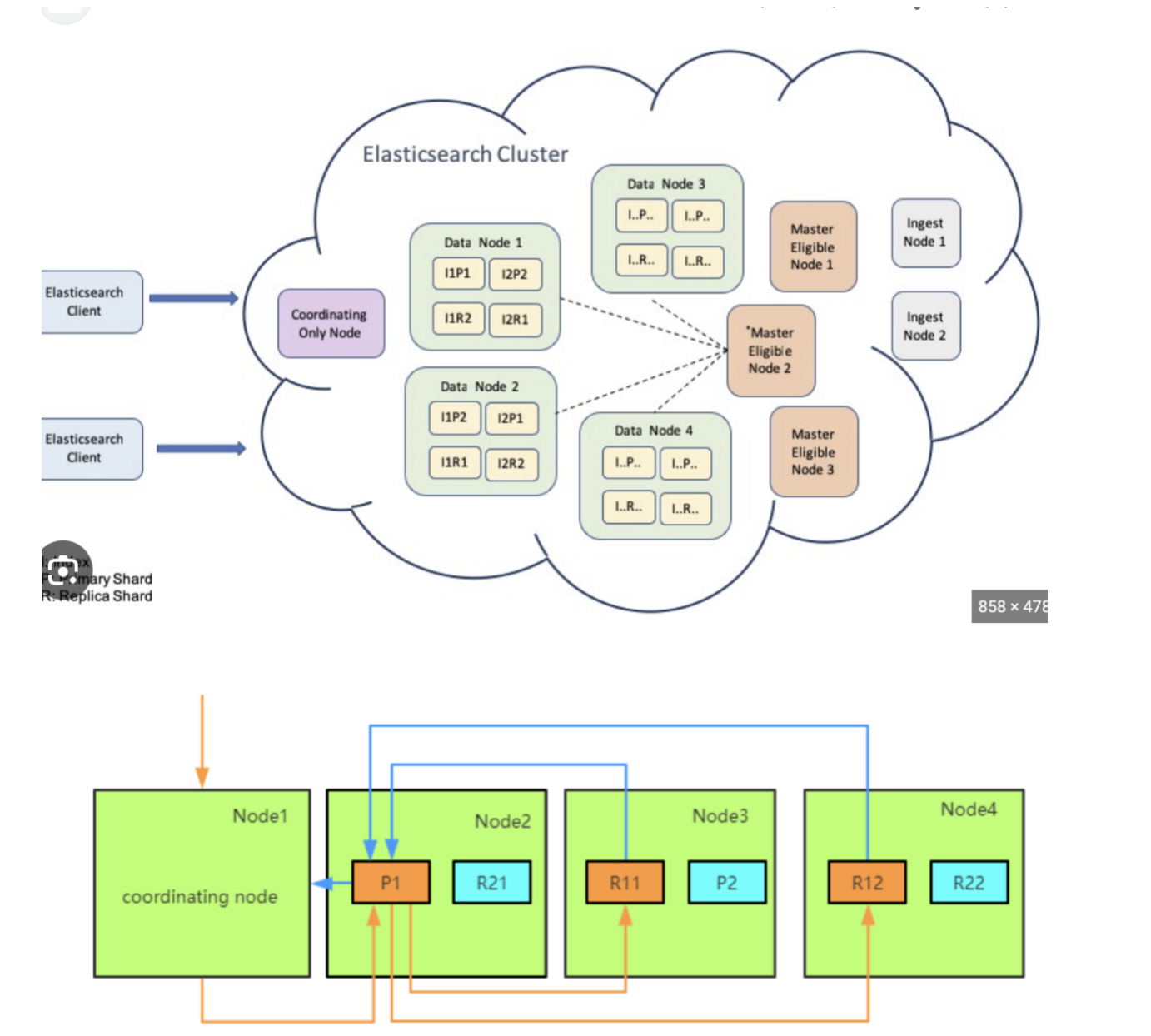
延伸思考和学习
- ES index 的mapping结构
- setting 分片和副本机制
- 分词器
- 检索query dsl
- 读写流程
- 集群架构和规划
- 读写优化
列型存储(hbase)
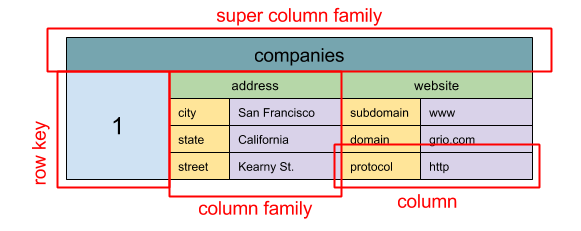
抽象模型:嵌套的
ColumnFamily<RowKey, Columns<ColKey, Value, Timestamp>>映射
类型存储的基本数据单元是列(名/值对)。列可以在列族(类似于 SQL 的数据表)中被分组。超级列族再分组普通列族。你可以使用行键独立访问每一列,具有相同行键值的列组成一行。每个值都包含版本的时间戳用于解决版本冲突。
Google 发布了第一个列型存储数据库 Bigtable,它影响了 Hadoop 生态系统中活跃的开源数据库 HBase 和 Facebook 的 Cassandra。像 BigTable,HBase 和 Cassandra 这样的存储系统将键以字母顺序存储,可以高效地读取键列。
列型存储具备高可用性和高可扩展性。通常被用于大数据相关存储。
来源及延伸阅读:列型存储
图数据库
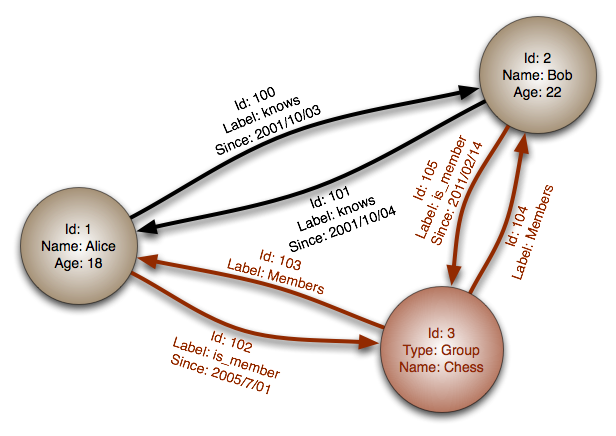
抽象模型: 图
在图数据库中,一个节点对应一条记录,一个弧对应两个节点之间的关系。图数据库被优化用于表示外键繁多的复杂关系或多对多关系。
图数据库为存储复杂关系的数据模型,如社交网络,提供了很高的性能。它们相对较新,尚未广泛应用,查找开发工具或者资源相对较难。许多图只能通过 REST API 访问。
相关资源和延伸阅读:图
来源及延伸阅读:NoSQL
SQL 还是 NoSQL
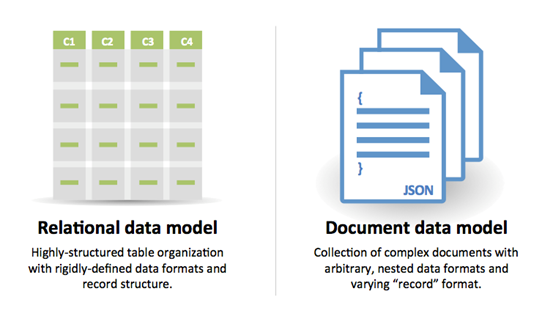
选取 SQL 的原因:
- 结构化数据
- 严格的模式
- 关系型数据
- 需要复杂的联结操作
- 事务
- 清晰的扩展模式
- 既有资源更丰富:开发者、社区、代码库、工具等
- 通过索引进行查询非常快
选取 NoSQL 的原因:
- 半结构化数据
- 动态或灵活的模式
- 非关系型数据
- 不需要复杂的联结操作
- 存储 TB (甚至 PB)级别的数据
- 高数据密集的工作负载
- IOPS 高吞吐量
适合 NoSQL 的示例数据:
- 埋点数据和日志数据
- 排行榜或者得分数据
- 临时数据,如购物车
- 频繁访问的(“热”)表
- 元数据/查找表
来源及延伸阅读:SQL 或 NoSQL
缓存redis
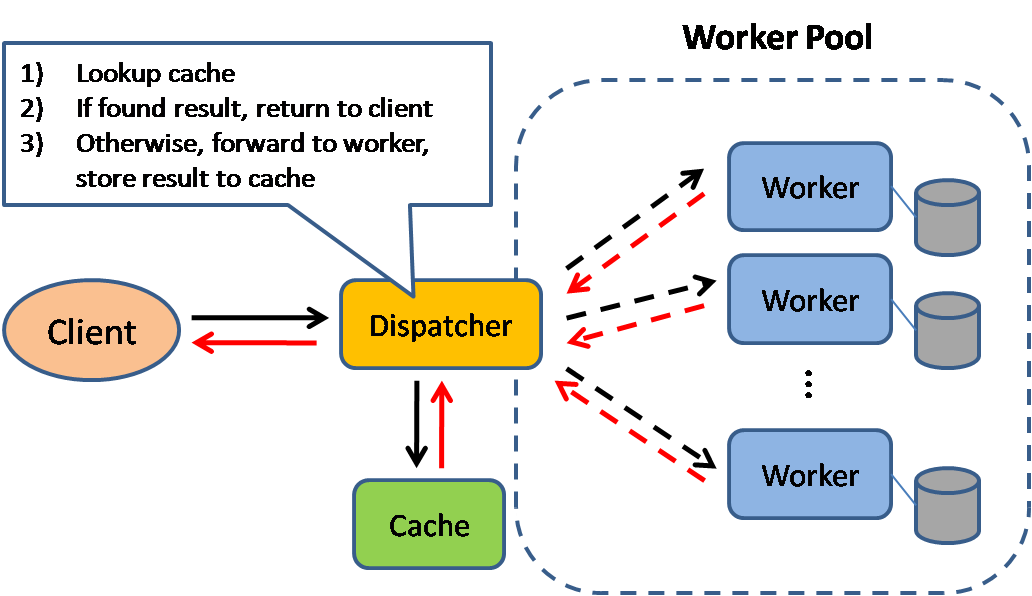
缓存可以提高页面加载速度,并可以减少服务器和数据库的负载。在这个模型中,分发器先查看请求之前是否被响应过,如果有则将之前的结果直接返回,来省掉真正的处理。
数据库分片均匀分布的读取是最好的。但是热门数据会让读取分布不均匀,这样就会造成瓶颈,如果在数据库前加个缓存,就会抹平不均匀的负载和突发流量对数据库的影响。
- 客户端缓存
缓存可以位于客户端(操作系统或者浏览器),服务端或者不同的缓存层。 - CDN 缓存,CDN 也被视为一种缓存。
- Web 服务器缓存
反向代理和缓存(比如 Varnish)可以直接提供静态和动态内容。Web 服务器同样也可以缓存请求,返回相应结果而不必连接应用服务器。 - 应用服务缓存(本地缓存)
- 缓存服务器(remote cache)
- 数据库本身的缓存
延伸思考和学习
- 本地缓存、分布式缓存
- 缓存的TTL
- 缓存的安全性
- 缓存的更新模式
异步与队列
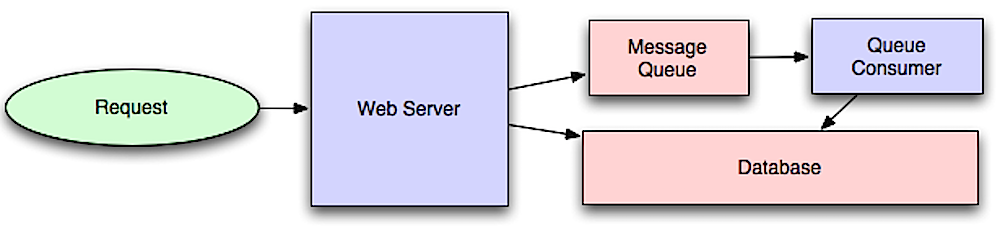
异步工作流有助于减少那些原本顺序执行的请求时间。它们可以通过提前进行一些耗时的工作来帮助减少请求时间,比如定期汇总数据。
消息队列
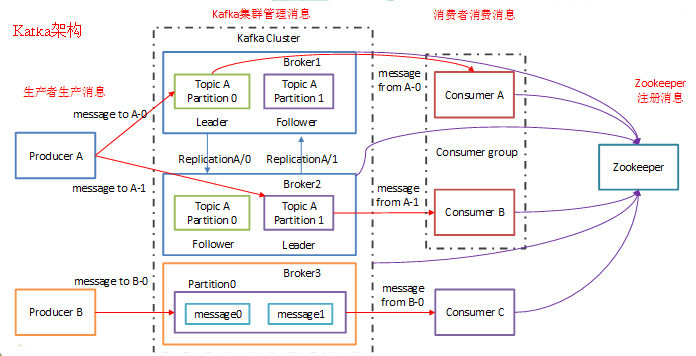
消息队列接收,保留和传递消息。如果按顺序执行操作太慢的话,你可以使用有以下工作流的消息队列:
- 应用程序将作业发布到队列,然后通知用户作业状态
- 一个 worker 从队列中取出该作业,对其进行处理,然后显示该作业完成
不去阻塞用户操作,作业在后台处理。在此期间,客户端可能会进行一些处理使得看上去像是任务已经完成了。例如,如果要发送一条推文,推文可能会马上出现在你的时间线上,但是可能需要一些时间才能将你的推文推送到你的所有关注者那里去。 - kafka 是一个令人满意的简单的消息代理,但是消息有可能会丢失。
- RabbitMQ 很受欢迎但是要求你适应「AMQP」协议并且管理你自己的节点。
- Apache Pulsar Pulsar是一个开源的、可扩展的消息队列和流处理平台。它具有高吞吐量、低延迟和可持久化的特点,支持多租户、多数据中心和多协议等功能
任务队列 (xxl-job)
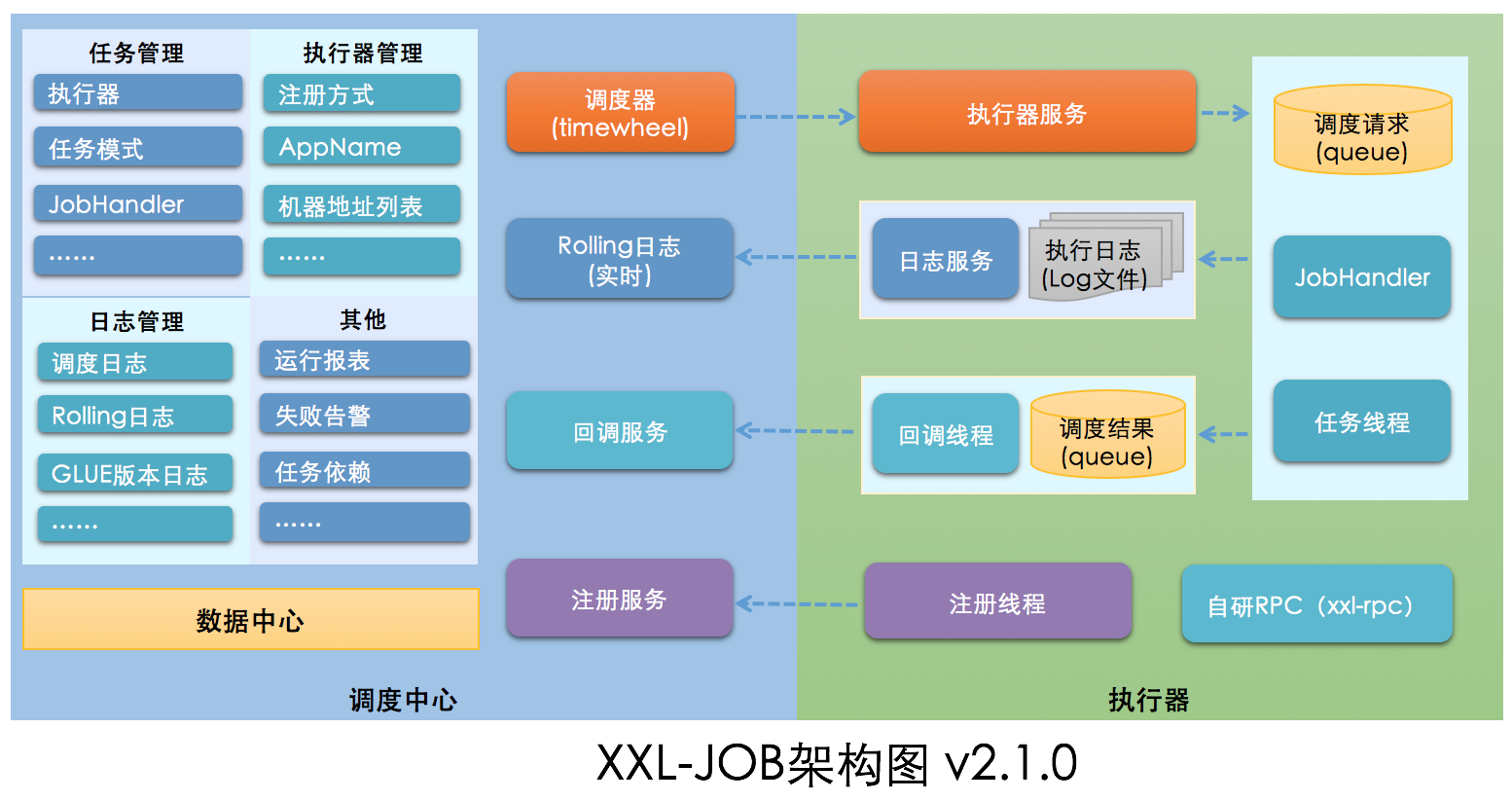
- 单点调度:https://github.com/robfig/cron
- 分布式调度:https://github.com/xuxueli/xxl-job
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性 - 调度模块(调度中心):
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。 - 执行模块(执行器,executor):
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
接收“调度中心”的执行请求、终止请求和日志请求等
参考:
如果队列开始明显增长,那么队列大小可能会超过内存大小,导致高速缓存未命中,磁盘读取,甚至性能更慢。背压可以通过限制队列大小来帮助我们,从而为队列中的作业保持高吞吐率和良好的响应时间。一旦队列填满,客户端将得到服务器忙或者 HTTP 503 状态码,以便稍后重试。客户端可以在稍后时间重试该请求,也许是指数退避
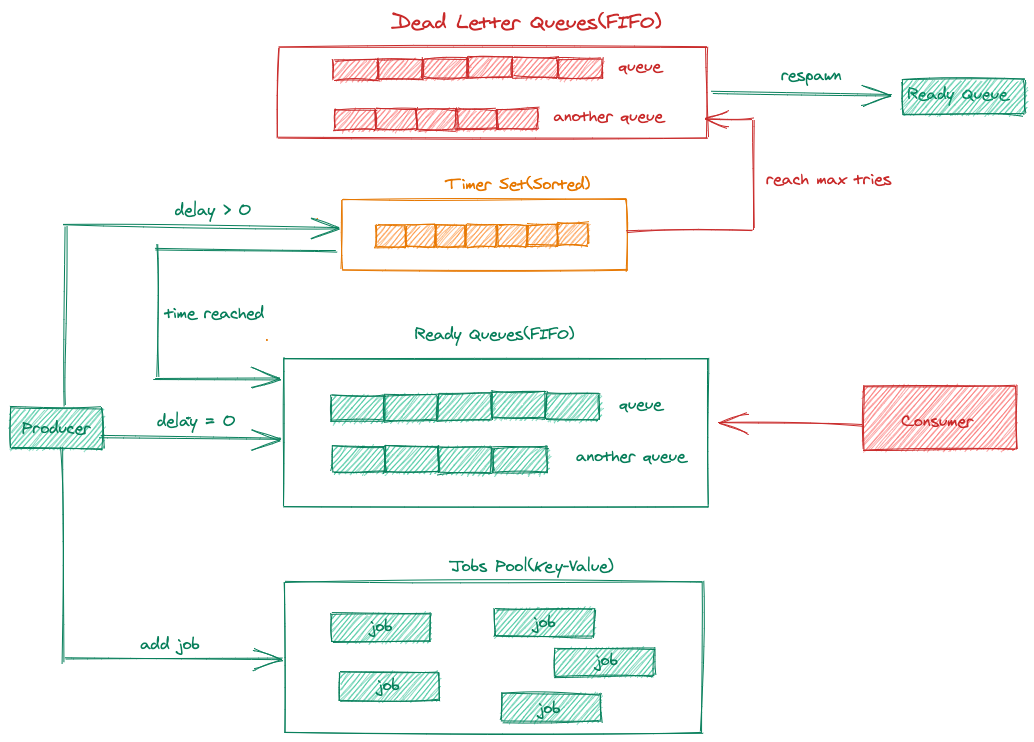
延时任务调度
{kind=link}
{kind=link}
延时任务场景
- 延时处理:有时候需要在某个事件发生后的一段时间内执行任务。例如,当用户提交订单后,可以设置一个延时任务,在一段时间后检查是否是支付
- 提醒和通知:延时任务调度可用于发送提醒和通知。例如,你可以设置一个延时任务,在用户注册后的24小时内发送一封欢迎邮件,或在用户下单后的一段时间内发送订单确认通知。
- 缓存刷新:延时任务调度可用于刷新缓存数据。当缓存过期时,可以设置一个延时任务,在一定的延时时间后重新加载缓存数据,以保持数据的新鲜性
- 任务队列跟消息队列在使用场景上最大的区别是: 任务之间是没有顺序约束而消息要求顺序(FIFO),且可能会对任务的状态更新而消息一般只会消费不会更新。 类似 Kafka 利用消息 FIFO 和不需要更新(不需要对消息做索引)的特性来设计消息存储,将消息读写变成磁盘的顺序读写来实现比较好的性能。而任务队列需要能够任务状态进行更新则需要对每个消息进行索引,如果把两者放到一起实现则很难实现在功能和性能上兼得。比如一下场景:
- 定时任务,如每天早上 8 点开始推送消息,定期删除过期数据等
- 任务流,如自动创建 Redis 流程由资源创建,资源配置,DNS 修改等部分组成,使用任务队列可以简化整体的设计和重试流程
- 重试任务,典型场景如离线图片处理
可用组件
- redis 包括有序集合(Sorted Set)你可以使用Redis的有序集合来实现延时任务队列。将任务的执行时间作为分数(score),任务的内容作为成员(member),将任务按照执行时间排序。通过定期轮询有序集合,检查是否有任务的执行时间到达,然后执行相应的任务
- https://github.com/bitleak/lmstfy
框架和引擎
工作流引擎与任务编排
goflow
- 技术原理:goflow 是基于数据流编程模型的工作流引擎,采用有向无环图(DAG)描述任务节点之间的依赖关系。每个节点可独立执行,节点间通过通道(channel)传递数据,充分利用 Go 的并发特性(goroutine、channel)实现高效的任务编排和并行处理。
- 使用场景:适用于需要复杂任务编排、数据流转、并发处理的场景,如数据处理流水线、ETL、自动化运维流程等。适合对任务依赖关系有明确建模需求的系统。
go-workflow
- 技术原理:go-workflow 是一款轻量级的工作流引擎,支持任务的定义、调度、状态管理和持久化。通过状态机管理任务流转,支持任务重试、超时、失败回调等机制。底层可集成多种存储后端(如 MySQL、Redis)以保证任务可靠性和可恢复性。
- 使用场景:适合需要可靠任务编排、长流程管理、任务状态追踪的业务,如订单处理、审批流、异步任务调度等。适用于对任务持久化和容错有较高要求的系统。
规则引擎与风控、资损、校验
gengine
- 技术原理:gengine 是一款高性能、轻量级的 Go 规则引擎,采用自定义 DSL(领域特定语言)编写规则,支持动态加载和热更新。底层通过 AST(抽象语法树)解析和高效的规则匹配算法,实现复杂业务规则的快速执行。支持规则优先级、条件判断、动作执行等特性。
- 使用场景:广泛应用于风控决策、资损防控、数据校验、营销策略等需要灵活配置和频繁变更规则的场景。适合对规则实时性和可维护性有较高要求的金融、电商等行业。
脚本执行引擎与低代码平台
tengo
- 技术原理:tengo 是一个用 Go 实现的嵌入式脚本语言,语法类似 JavaScript。支持类型安全、垃圾回收、闭包、模块化等特性。可将业务逻辑以脚本形式动态加载和执行,便于扩展和热更新。适合嵌入到 Go 应用中作为业务自定义脚本引擎。
- 使用场景:适用于低代码平台、动态业务规则、用户自定义脚本、插件系统等场景。可用于实现灵活的业务扩展和快速迭代。
参考:tengo GitHub
anko
- 技术原理:anko 是一个简洁的 Go 脚本解释器,支持基本的脚本语法、变量、函数、流程控制等。可与 Go 代码无缝集成,支持在运行时动态执行脚本。适合对脚本功能要求不高但需要快速集成的场景。
- 使用场景:适合低代码平台、配置驱动、动态表达式计算、简单自动化脚本等。适用于对性能和安全性有一定要求但业务逻辑相对简单的系统。
参考:anko GitHub
好用的规范和工具
规范:
- Go编码规范
- api 设计规范
- git 使用规范
工具:
- 绘图工具:https://app.diagrams.net/
- plantuml: https://plantuml.com/
- Postman: https://www.postman.com/
- Charles: https://www.charlesproxy.com/
- API 文档生成工具:Swagger
- DBeaver:开源的数据库管理工具,支持多种数据库
云原生和服务部署CI/CD
- docker
- Kubernetes Kubernetes 入门&进阶实战
- Jenkins
大数据存储和计算
- spark
- spark streaming
- hive
- presto
- Lambda 和 Kappa 架构简介:https://libertydream.github.io/2020/04/12/lambda-%E5%92%8C-kappa-%E7%AE%80%E4%BB%8B/
系统稳定性建设
影响系统可用性的因素
在系统可以用性可以做哪些工作
架构上设计 (拆分/解偶/资源隔离)
- 支持异地多活(DR集群)
- 服务支持横向扩容,扩容时注意事项(mysql,redis,kafka,es,依赖方,监控)
- 离线和在线分离
- mysql分库,分表、kafka topic、不同的ES集群
- 辑架构和物理架构分离,订单系统支持根据业务类型路由
系统保护
- 限流
- 熔断降级(核心功能报错,非核心功能返回空或者固定内容)
技术选型,组件本身的可用性保证和容量评估
- 适用性
- 优缺点
- 产品口碑
- 社区活跃度
- 实战案例
- 扩展性等多个方面进行全量评估
- 容量评估,mysql 一写多读,codis,kafka,ES
- 灾备,快速恢复
功能设计时考虑
- 接口维度的限流、用户维度限流
- 避免单点:比如在主页设计时,主页配置数据需要写在多个redis中
- 核心功能降级策略:redis→cdn
变更和服务扩容发布流程
- 新版本发布兼容,数据准备,变更流程,服务发布顺序
- 扩容时注意事项(mysql,redis,kafka,es,依赖方,监控)
- DB变更、配置变更、组件变更
可观测性&告警
- metric & log & trace
- 监控体系和告警指标
- SLA和NOC指标
可观测性、监控和告警
- 业务层的监控,例如NOC核心指标监控,登陆、首页流量、成功率、PDP流量、成功率、下单流量、成功率、支付数量、成功率等
- 网关的监控。所有接口的流量、成功率、耗时95线,限流监控
- 接口详情监控:可以筛选出每个接口流量、成功率、具体错误吗、耗时均线、95线等
- 核心功能监控:缓存命中率、变价率、数据一致性监控
- 中间件外部组件监控:mysql、redis、kafka、es,容器资源监控等
- 外部依赖监控:支付团队,履约团队、供应商依赖服务监控
如何搭建监控和日志系统
- prometheus,https://prometheus.io/
- grafna,https://www.google.com.hk/search?q=grafana&rlz=1C5GCEM_enCN985CN985&oq=grafana&aqs=chrome..69i57j69i60l3j69i65l3j69i60.8511j0j7&sourceid=chrome&ie=UTF-8
- 日志管理和检索: Elasticsearch、Logstash、Kibana(ELK Stack)
- 指标监控:Prometheus、Grafana、cat
- 分布式追踪:分布式追踪工具包括 Jaeger + opentracing
- 日志组件:https://github.com/uber-go/zap
应该知道的安全问题
这一部分需要更多内容。一起来吧!
安全是一个宽泛的话题。除非你有相当的经验、安全方面背景或者正在申请的职位要求安全知识,你不需要了解安全基础知识以外的内容:
- 在运输和等待过程中加密
- 对所有的用户输入和从用户那里发来的参数进行处理以防止
- SQL 注入
- XSS
- 使用参数化的查询来防止 SQL 注入。
- 使用最小权限原则。
- 为开发者准备的安全引导
- OWASP top ten
参考:
系统设计实践
- 设计类似于 Dropbox 的文件同步服务
- 设计类似于 Google 的搜索引擎
- 设计类似于 Google 的可扩展网络爬虫
- 设计 Google 文档
- 设计类似 Redis 的键值存储
- 设计类似 Memcached 的缓存系统
- 设计类似亚马逊的推荐系统
- 设计类似 Bitly 的短链接系统
- 设计类似 WhatsApp 的聊天应用
- 设计类似 Instagram 的图片分享系统
- 设计 Facebook 的新闻推荐方法
- 设计 Facebook 的时间线系统
- 设计 Facebook 的聊天系统
- 设计类似 Facebook 的图表搜索系统
- 设计类似 CloudFlare 的内容传递网络
- 设计类似 Twitter 的热门话题系统
- 设计一个随机 ID 生成系统
- 返回一定时间段内次数前 k 高的请求
- 设计一个数据源于多个数据中心的服务系统
highscalability.com - 设计一个多人网络卡牌游戏
- 设计一个垃圾回收系统
参考: