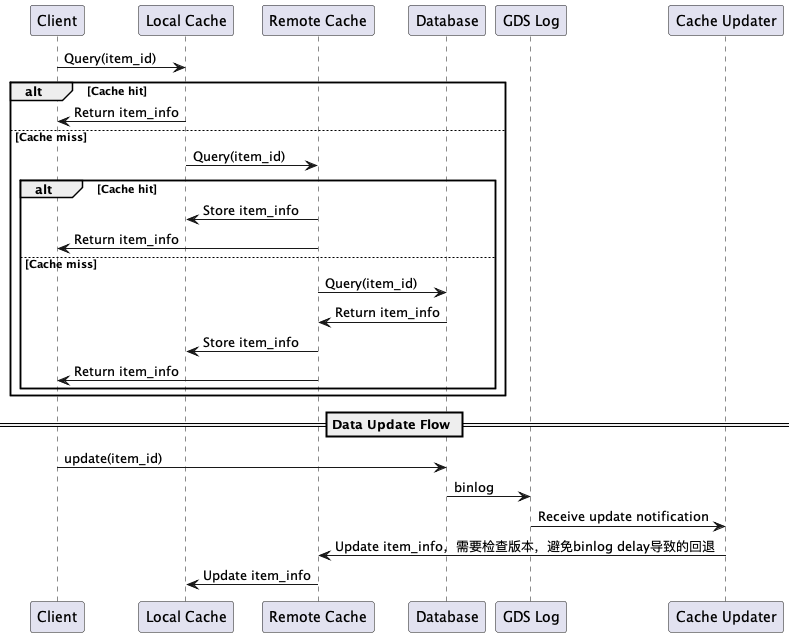
sequenceDiagram
participant FE as 前端
participant Gateway as API Gateway
participant PDPHandler as PDP Handler
participant Cache as Redis Cache
participant Engine as Pricing Engine
participant Item as Item Service
participant Promo as Promotion Service
FE->>Gateway: GetItemPrice(itemId=123, userId=789)
Note over Gateway: 场景路由 → PDP Handler
Gateway->>PDPHandler: Handle(GetItemPriceRequest)
PDPHandler->>Cache: Get(cache_key)
alt 缓存命中(命中率 > 90%)
Cache-->>PDPHandler: ItemPriceResponse
Note over PDPHandler: 直接返回,耗时 < 10ms
else 缓存未命中
PDPHandler->>Engine: Calculate(ScenePDP, SkipLayers=[deduction,charge])
Note over Engine: 仅执行 Layer 1-2(基础价+促销)
Engine->>Item: GetItemBaseInfo(itemId)
Item-->>Engine: marketPrice, discountPrice
Engine->>Promo: GetActivePromotions(itemId, userId)
Promo-->>Engine: flashSale, newUserPrice
Engine->>Engine: 计算价格(无需抵扣/费用计算)
Engine-->>PDPHandler: PricingResult
PDPHandler->>PDPHandler: 构建轻量响应
PDPHandler->>Cache: Set(cache_key, response, 5min)
Note over PDPHandler: 异步预估可用优惠券
end
PDPHandler-->>Gateway: ItemPriceResponse
Gateway-->>FE: 返回价格
Note over FE: 展示:折扣价 + 活动价 + 可用券数
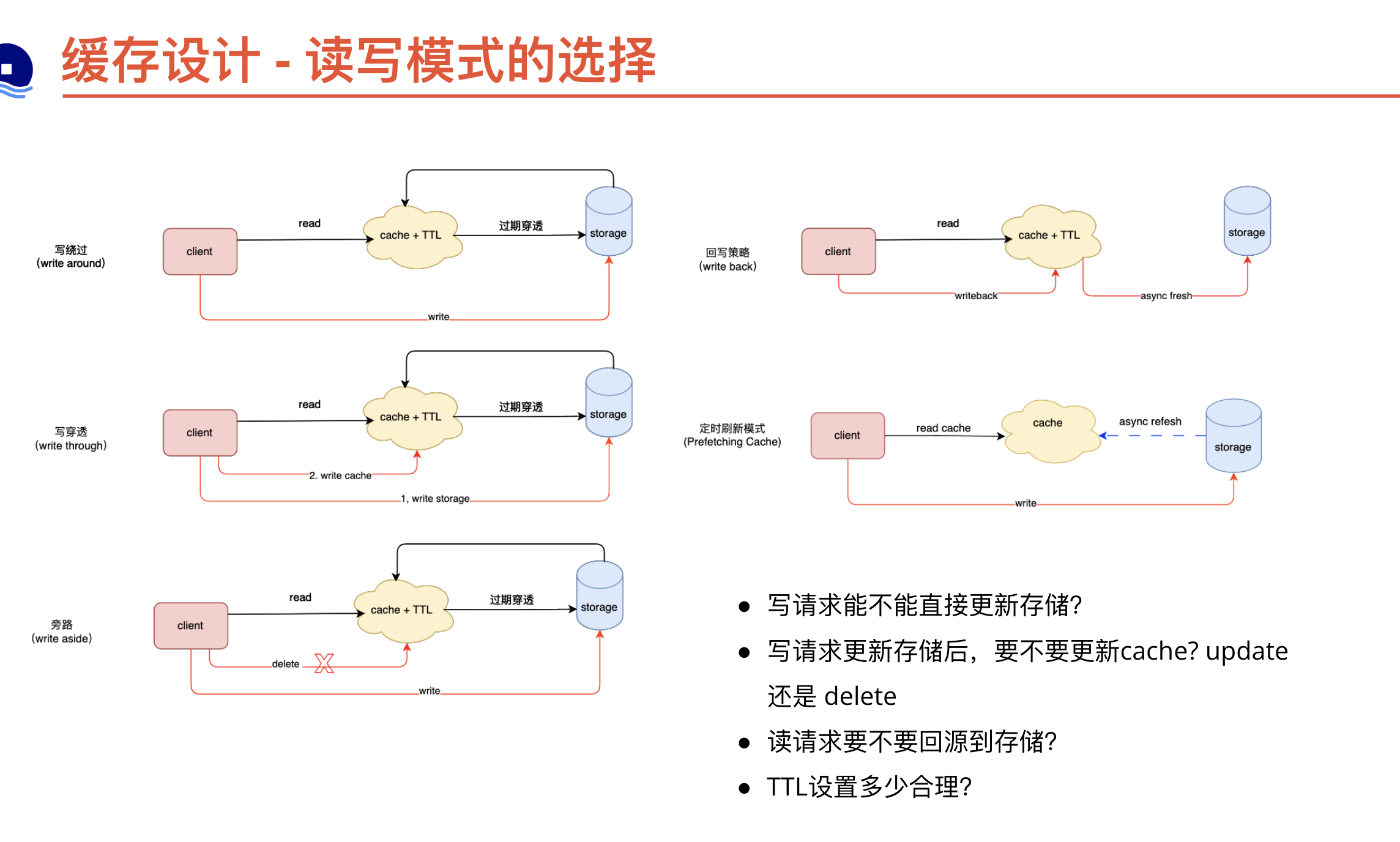
PDP场景特点:
✅ 高缓存命中:缓存命中率 > 90%,命中时延 < 10ms
✅ 轻量计算:只执行 Layer 1-2,跳过抵扣和费用计算
✅ 无锁定:不锁定库存和优惠券
✅ 异步预估:不阻塞主流程,后台估算优惠券
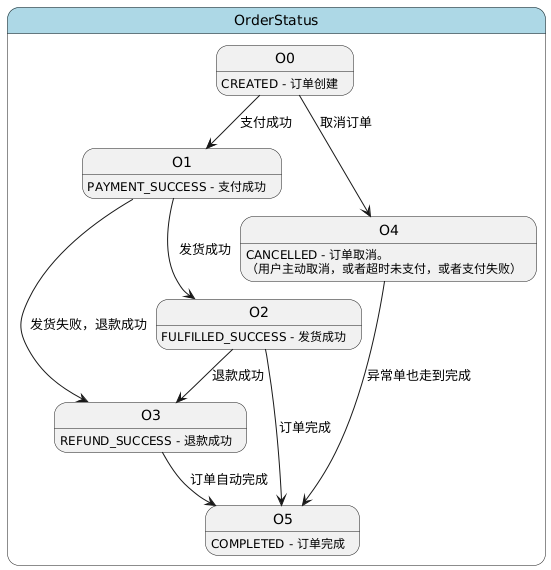
3.4.2 订单创建价格计算流程(CreateOrder - 库存锁定+订单快照)
sequenceDiagram
participant FE as 前端
participant Order as Order Service
participant Gateway as API Gateway
participant OrderHandler as Order Handler
participant SupplierSvc as Supplier Price Service
participant SupplierAPI as 外部供应商API
participant Engine as Pricing Engine
participant Inventory as Inventory Service
participant SnapshotMgr as Snapshot Manager
participant DB as MySQL
FE->>Order: 点击"去结算"
Order->>Gateway: CalculateOrderPrice(items, userId, services)
Note over Gateway: 场景路由 → Order Handler
Gateway->>OrderHandler: Handle(OrderPriceRequest)
rect rgb(255, 230, 230)
Note over OrderHandler: Step 0: 区分自营/供应商品类
OrderHandler->>OrderHandler: classifyItems() → selfOperated + supplier
end
rect rgb(255, 245, 230)
Note over OrderHandler: Step 1: 供应商价格预订(如果有供应商品类)
par 并发查询供应商价格
OrderHandler->>SupplierSvc: QueryAndBook(hotelItem)
SupplierSvc->>SupplierAPI: CheckAvailability(hotelInfo)
alt 供应商超时
Note over SupplierSvc: 降级:使用DB缓存价格
else 供应商正常返回
SupplierAPI-->>SupplierSvc: Available=true Price=1200 BookingToken=TKN-001
end
SupplierSvc-->>OrderHandler: SupplierBooking{price, token, expire}
and 自营品类库存预检
OrderHandler->>Inventory: CheckAvailability(selfOperatedItems)
alt 库存不足
Inventory-->>OrderHandler: ErrOutOfStock
OrderHandler-->>Order: Error: 库存不足
end
end
end
rect rgb(220, 240, 255)
Note over OrderHandler: Step 2: 计算订单价格
OrderHandler->>Engine: Calculate(SceneCreateOrder, items, supplierBookings)
Note over Engine: Layer 1: 基础价格 • 自营:本地价格 • 供应商:SupplierPrice Layer 2: 营销活动 Layer 4: 附加费(含平台服务费,不含支付手续费) 跳过 Layer 3: 优惠券/积分
Engine->>Engine: GetBasePrice() (Layer 1)
Note over Engine: 自营品类:本地数据库价格 供应商品类:SupplierPrice from BookingToken
Engine->>Engine: ApplyPromotions() (Layer 2: 限时抢购/新人价)
Engine->>Engine: CalculateAdditionalFee() (Layer 4: 增值服务费/运费/平台服务费)
Engine->>Engine: CalculateFinalPrice()
Engine-->>OrderHandler: PricingResult (orderPrice=19184)
Note over Engine: 含基础价(供应商报价) + 营销价 + 附加费 不含券/积分/支付手续费
end
rect rgb(230, 255, 230)
Note over OrderHandler: Step 3: 锁定资源
par 自营品类库存锁定
OrderHandler->>Inventory: Reserve(orderID, selfOperatedItems, 30min)
Inventory->>DB: UPDATE inventory SET reserved += qty
alt 锁定失败
Inventory-->>OrderHandler: Error
Note over OrderHandler: 回滚供应商预订
end
Inventory-->>OrderHandler: OK
and 供应商品类预订确认
Note over OrderHandler: 保存 BookingToken(5-15分钟有效)
end
end
rect rgb(230, 240, 255)
Note over OrderHandler: Step 4: 创建订单
OrderHandler->>DB: INSERT INTO order_tab (order_id, order_price, supplier_bookings, status='pending_payment')
Note over OrderHandler: Step 5: 生成订单快照(30分钟)
OrderHandler->>SnapshotMgr: CreateSnapshot(OrderSnapshot + SupplierBookings)
Note over SnapshotMgr: 保存订单价格 (基础价+营销价+附加费) + 供应商BookingToken
SnapshotMgr->>DB: INSERT INTO price_snapshot_tab (含 supplier_booking_token)
SnapshotMgr-->>OrderHandler: snapshotID="ORDER-20260227-001"
end
OrderHandler->>OrderHandler: 构建响应
OrderHandler-->>Gateway: OrderPriceResponse{
orderID, orderPrice=19184,
supplierBookings, snapshotID, expireAt
}
Gateway-->>Order: 返回订单信息
Order-->>FE: 跳转到收银台
Note over FE: 携带 orderID 和 BookingToken 进入收银台
CreateOrder场景特点:
✅ 先创建订单:生成订单ID和订单号
✅ 品类区分:自营品类和供应商品类分别处理
自营品类:使用本地库存和价格
供应商品类:先查询供应商实时价格并获取BookingToken
✅ 供应商价格预订(仅供应商品类):
并发调用外部供应商API查询价格和库存
获取BookingToken(5-15分钟有效)和供应商报价
处理超时降级(使用DB缓存价格)
预订失败需回滚其他资源锁定
✅ 价格计算:包含以下要素
✅ Layer 1: 基础价格
自营品类:本地商品市场价/折扣价
供应商品类:供应商实时报价(SupplierPrice from BookingToken)
✅ Layer 2: 营销价格(限时抢购、新人价、Bundle等活动优惠)
✅ Layer 4: 附加费用
增值服务费(如碎屏险)
运费
平台服务费(供应商品类佣金)
不含支付手续费(留到Checkout)
❌ 不含 Layer 3: 优惠券和积分抵扣(留到Checkout)
✅ 库存预扣/预订:
自营品类:锁定本地库存(30分钟)
供应商品类:保存BookingToken(5-15分钟)
✅ 生成订单快照:保存订单价格和供应商预订信息(30分钟有效)
✅ 订单状态:pending_payment
⚠️ 性能要求:
自营品类:P99 < 300ms
供应商品类:P99 < 1000ms(含外部API调用)
⚠️ 失败回滚:供应商预订失败需释放已锁定的本地库存
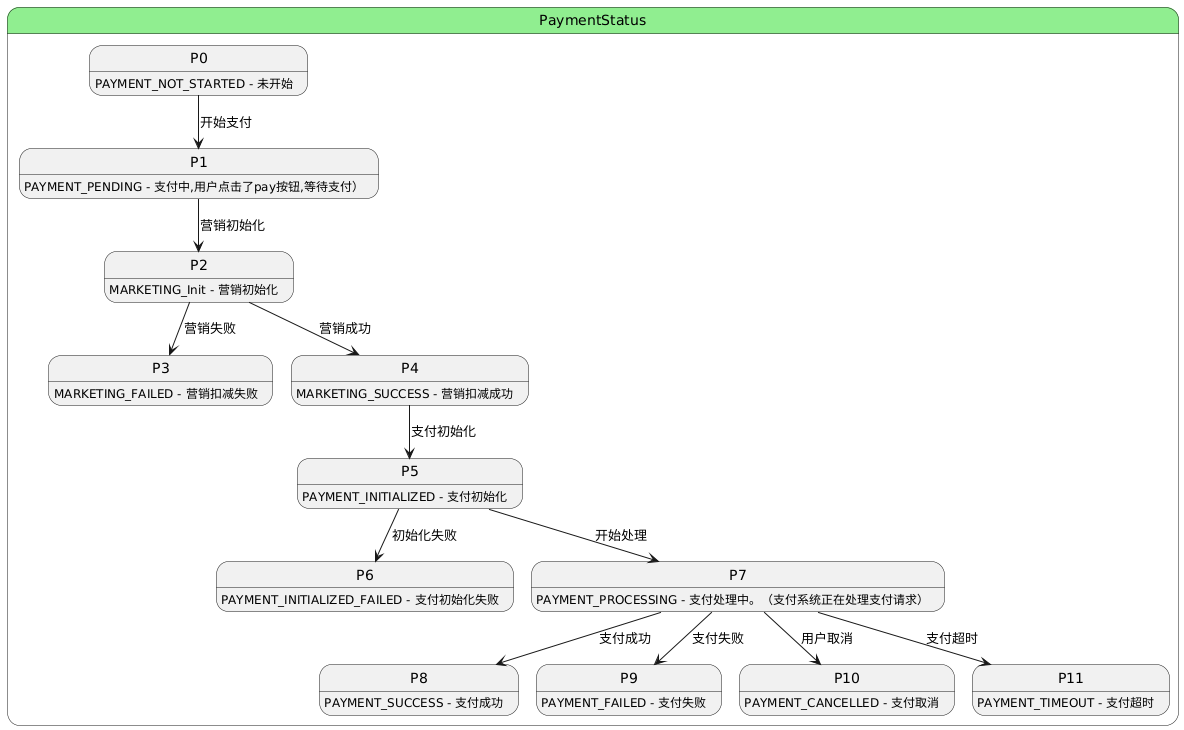
3.4.3 收银台价格计算流程(Checkout - 完整计算+支付快照)
sequenceDiagram
participant FE as 前端/收银台
participant Gateway as API Gateway
participant CheckoutHandler as Checkout Handler
participant SnapshotMgr as Snapshot Manager
participant Engine as Pricing Engine
participant Voucher as Voucher Service
participant Coin as Coin Service
participant DB as MySQL
participant Order as Order Service
FE->>Gateway: GetCheckoutPrice(orderID, voucherCode, useCoin, channelID)
Note over Gateway: 场景路由 → Checkout Handler
Gateway->>CheckoutHandler: Handle(CheckoutPriceRequest)
rect rgb(255, 230, 230)
Note over CheckoutHandler: Step 1: 获取订单快照
CheckoutHandler->>SnapshotMgr: GetSnapshot(orderSnapshotID)
alt 订单快照已过期
SnapshotMgr-->>CheckoutHandler: nil
CheckoutHandler-->>Gateway: Error: 订单已过期
Gateway-->>FE: 提示重新下单
end
SnapshotMgr-->>CheckoutHandler: orderSnapshot (orderPrice=19184) 含基础价+营销价+附加费
Note over CheckoutHandler: Step 2: 验证订单状态
CheckoutHandler->>Order: GetOrder(orderID)
Order-->>CheckoutHandler: order (status='pending_payment')
alt 订单状态异常
CheckoutHandler-->>Gateway: Error: 订单状态无效
end
end
rect rgb(220, 240, 255)
Note over CheckoutHandler: Step 3: 完整计算最终价格
CheckoutHandler->>Engine: Calculate(SceneCheckout, orderID, voucherCode, coin, channel)
Note over Engine: 执行完整 Layer 1-5(包含券/积分/手续费)
Engine->>Engine: 使用订单快照的价格(基础+营销+附加费)
Engine->>Voucher: ValidateVoucher(voucherCode)
Voucher-->>Engine: discount = 500
Engine->>Coin: CalculateCoinDeduction(useCoin, amount)
Coin-->>Engine: coinDeduction = 5
Engine->>Engine: CalculateHandlingFee(channelID)
Engine->>Engine: CalculateFinalPrice()
Engine-->>CheckoutHandler: PricingResult (finalPrice=19051)
end
rect rgb(230, 255, 230)
Note over CheckoutHandler: Step 4: 软锁定券和积分(15分钟)
par 并发软锁定
CheckoutHandler->>Voucher: SoftReserve(orderID, voucherCode)
Note over Voucher: 软锁定(可释放)
Voucher-->>CheckoutHandler: OK
CheckoutHandler->>Coin: SoftReserve(orderID, coinAmount)
Note over Coin: 软锁定(可释放)
Coin-->>CheckoutHandler: OK
end
end
rect rgb(230, 240, 255)
Note over CheckoutHandler: Step 5: 生成支付快照(15分钟)
CheckoutHandler->>SnapshotMgr: CreateSnapshot(PaymentSnapshot)
Note over SnapshotMgr: 保存最终支付价格
SnapshotMgr->>DB: INSERT INTO price_snapshot_tab
SnapshotMgr-->>CheckoutHandler: paymentSnapshotID="PAY-20260227-001"
end
CheckoutHandler->>CheckoutHandler: 构建完整响应
CheckoutHandler-->>Gateway: CheckoutPriceResponse{
orderID, finalPrice=19051,
voucherDiscount=500, coinDeduction=5,
handlingFee=372, breakdown,
paymentSnapshotID, expireAt
}
Gateway-->>FE: 返回价格
Note over FE: 展示最终价格明细 + [确认支付] 按钮
Checkout场景特点:
✅ 基于订单:依赖已创建的订单和订单快照
✅ 完整计算:执行所有 Layer(1-5),包含券/积分/手续费
✅ 软锁定:预核销优惠券和积分(不实际扣减,可释放)
✅ 生成支付快照:保存最终价格(15分钟有效)
✅ 实时重算:用户切换券/积分/渠道时实时重新计算
⚠️ 性能要求:P99 < 200ms
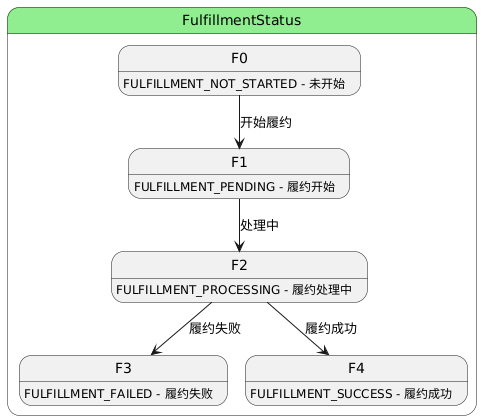
3.4.4 支付价格验证流程(Payment - 快照验证+调起支付)
sequenceDiagram
participant Payment as Payment Service
participant Gateway as API Gateway
participant PaymentHandler as Payment Handler
participant SnapshotMgr as Snapshot Manager
participant SupplierSvc as Supplier Price Service
participant SupplierAPI as 外部供应商API
participant VoucherSvc as Voucher Service
participant CoinSvc as Coin Service
participant DB as MySQL
Payment->>Gateway: GetPaymentPrice(orderID, paymentSnapshotID)
Note over Gateway: 场景路由 → Payment Handler
Gateway->>PaymentHandler: Handle(PaymentPriceRequest)
rect rgb(255, 245, 230)
Note over PaymentHandler: Step 1: 验证快照
PaymentHandler->>SnapshotMgr: ValidateSnapshot(paymentSnapshotID, orderID)
SnapshotMgr->>DB: SELECT * FROM price_snapshot_tab WHERE snapshot_id=?
DB-->>SnapshotMgr: Snapshot Data (含 BookingToken)
alt 快照不存在或已过期
SnapshotMgr-->>PaymentHandler: Error: 快照无效
PaymentHandler-->>Payment: Error: 请重新提交订单
end
alt 订单ID不匹配
SnapshotMgr-->>PaymentHandler: Error: 订单不匹配
PaymentHandler-->>Payment: Error: 订单验证失败
end
alt 快照已使用
SnapshotMgr-->>PaymentHandler: Error: 快照已使用
PaymentHandler-->>Payment: Error: 重复支付
end
SnapshotMgr-->>PaymentHandler: Valid Snapshot (finalPrice=19051, bookingTokens)
end
rect rgb(255, 230, 230)
Note over PaymentHandler: Step 2: 供应商确认预订(如果有)
alt 订单包含供应商品类
PaymentHandler->>SupplierSvc: ConfirmBooking(bookingTokens)
SupplierSvc->>SupplierAPI: ConfirmReservation(TKN-001)
alt BookingToken过期或无效
SupplierAPI-->>SupplierSvc: Error: Token过期
SupplierSvc-->>PaymentHandler: Error: 供应商预订失败
PaymentHandler-->>Payment: Error: 请重新下单
else 供应商确认成功
SupplierAPI-->>SupplierSvc: Confirmed, SupplierOrderID=SP-001
SupplierSvc-->>PaymentHandler: OK (supplierOrderID)
end
end
end
rect rgb(230, 255, 230)
Note over PaymentHandler: Step 3: 正式锁定券/积分
par 锁定优惠券
PaymentHandler->>VoucherSvc: Reserve(orderID, voucherCode)
VoucherSvc-->>PaymentHandler: OK
and 锁定积分
PaymentHandler->>CoinSvc: Reserve(orderID, coinAmount)
CoinSvc-->>PaymentHandler: OK
end
end
PaymentHandler->>PaymentHandler: 验证支付金额
alt 支付金额不匹配
PaymentHandler-->>Payment: Error: 金额不一致
end
PaymentHandler-->>Gateway: PaymentPriceResponse{
finalPrice: 19051,
breakdown,
snapshotID,
supplierOrderIDs
}
Gateway-->>Payment: 返回价格
Note over Payment: 调用第三方支付
Payment->>Payment: 支付成功
rect rgb(230, 240, 255)
Note over Payment: Step 4: 支付成功回调
Payment->>Gateway: MarkSnapshotUsed(snapshotID)
Gateway->>SnapshotMgr: UseSnapshot(snapshotID)
SnapshotMgr->>DB: UPDATE price_snapshot_tab SET status='used', used_at=NOW()
SnapshotMgr-->>Payment: OK
end
// Service 增值服务 type Service struct { ServiceID int64`json:"service_id"` ServiceType string`json:"service_type"`// screen_insurance, warranty, etc. Price int64`json:"price"` Selected bool`json:"selected"` }
// Calculator 价格计算器(策略接口) type Calculator interface { // Calculate 执行计算 Calculate(ctx context.Context, req *PricingRequest) (*PricingResponse, error) // Support 是否支持该品类 Support(categoryID int64) bool // Priority 优先级(用于策略选择) Priority() int }
// Layer 价格计算层(责任链模式) type Layer interface { // Process 处理当前层 Process(ctx context.Context, req *PricingRequest, state *PricingState) error // Name 层名称 Name() string // Order 执行顺序 Order() int }
graph TB
A[开始迁移] --> B{选择品类}
B --> C[开启空跑]
C --> D{空跑比对}
D -->|有差异| E[修复问题]
E --> C
D -->|无差异| F[灰度 1%]
F --> G{观察指标}
G -->|异常| H[回滚]
H --> E
G -->|正常| I[灰度 10%]
I --> J{观察指标}
J -->|异常| H
J -->|正常| K[灰度 50%]
K --> L{观察指标}
L -->|异常| H
L -->|正常| M[灰度 100%]
M --> N[观察 1 周]
N --> O[下线老逻辑]
O --> P[完成迁移]
// 3. 从 MySQL 查 3000 个可用券码 codes, err := db.Query(` SELECT id FROM inventory_code_pool_xx WHERE item_id=? AND sku_id=? AND batch_id=? AND status=1 AND id > ? ORDER BY id LIMIT 3000 `, itemID, skuID, batchID, lastCodeID)
local key = KEYS[1] local book_num = tonumber(ARGV[1]) local promotion_id = ARGV[2] -- 空字符串表示普通库存
-- 1. 获取可用库存 local available = tonumber(redis.call('HGET', key, 'available') or0)
-- 2. 如果有营销活动,合并计算 local promo_stock = 0 if promotion_id ~= ''then promo_stock = tonumber(redis.call('HGET', key, promotion_id) or0) end local total_available = available + promo_stock
-- 3. 检查库存 if book_num > total_available then return-1-- 库存不足 end
-- 4. 优先扣营销库存,不足时扣普通库存 if promo_stock > 0then if book_num <= promo_stock then redis.call('HINCRBY', key, promotion_id, -book_num) else redis.call('HSET', key, promotion_id, 0) redis.call('HINCRBY', key, 'available', -(book_num - promo_stock)) end else redis.call('HINCRBY', key, 'available', -book_num) end
// 单条查询 → 批量查询 // Before: 100 次网络往返 for _, id := range userIDs { user, _ := redis.Get(fmt.Sprintf("user:%s", id)) }
// After: 1 次网络往返 keys := make([]string, len(userIDs)) for i, id := range userIDs { keys[i] = fmt.Sprintf("user:%s", id) } users, _ := redis.MGet(keys...)
3. 数据库优化
a) SQL 优化
问题
优化方案
无索引/索引失效
添加合适索引,避免索引失效场景
**SELECT ***
只查需要的字段
大事务
拆分小事务,减少锁持有时间
深分页
游标分页(WHERE id > last_id LIMIT 10)
N+1 查询
JOIN 或批量查询
b) 索引优化原则
1 2 3 4 5 6 7 8 9 10 11
-- 联合索引最左前缀 CREATE INDEX idx_user_status_time ON orders(user_id, status, create_time);
-- 以下查询可以使用索引 SELECT*FROM orders WHERE user_id =123; SELECT*FROM orders WHERE user_id =123AND status ='PAID'; SELECT*FROM orders WHERE user_id =123AND status ='PAID'AND create_time >'2025-01-01';
-- 以下查询无法使用索引 SELECT*FROM orders WHERE status ='PAID'; -- 缺少最左字段 SELECT*FROM orders WHERE user_id =123OR status ='PAID'; -- OR 导致失效
sequenceDiagram
participant M as 商家
participant API as 商品 API
participant DB as 数据库
participant MQ as Kafka
participant Audit as 审核服务
M->>API: 创建商品
API->>API: 身份验证
API->>API: 限流检查
API->>DB: 保存商品(草稿)
API->>MQ: 发布审核事件
API-->>M: 返回商品 ID
MQ->>Audit: 消费审核事件
Audit->>Audit: 人工审核
Audit->>DB: 更新状态
Audit->>MQ: 发布审核结果
sequenceDiagram
participant Ops as 运营
participant API as 商品 API
participant Parser as Excel 解析器
participant DB as 数据库
participant MQ as Kafka
Ops->>API: 上传 Excel 文件
API->>Parser: 流式解析
loop 每行数据
Parser->>Parser: 验证数据
Parser->>DB: 保存商品
Parser->>MQ: 发布事件
end
API-->>Ops: 返回结果
funcCartesianSKUs(spuID string, defs []SpecDef) []*SKU { iflen(defs) == 0 { return []*SKU{{SPUID: spuID, SKUID: GenerateSKUID(spuID, nil), SpecValues: map[string]string{}}} } var out []*SKU var dfs func(i int, cur map[string]string) dfs = func(i int, cur map[string]string) { if i == len(defs) { m := make(map[string]string, len(cur)) for k, v := range cur { m[k] = v } out = append(out, &SKU{ SPUID: spuID, SKUID: GenerateSKUID(spuID, m), SpecValues: m, }) return } d := defs[i] for _, val := range d.Values { cur[d.Name] = val dfs(i+1, cur) delete(cur, d.Name) } } dfs(0, map[string]string{}) return out }
type Category struct { CategoryID int64 ParentID int64 Name string Level int Path string// 物化路径,如 "1/10/1005" IsLeaf bool }
type Attribute struct { AttributeID int64 Name string InputType string// text/select/multi/date Required bool CategoryIDs []int64// 绑定类目 }
type ProductAttribute struct { SPUID string AttributeID int64 Value string }
funcBuildCategoryTree(nodes []*Category)map[int64][]*Category { children := make(map[int64][]*Category) for _, n := range nodes { children[n.ParentID] = append(children[n.ParentID], n) } return children }
funcIndexCategoriesByID(nodes []*Category)map[int64]*Category { m := make(map[int64]*Category, len(nodes)) for _, n := range nodes { m[n.CategoryID] = n } return m }
funcGetCategoryPath(byID map[int64]*Category, leafID int64) []*Category { var path []*Category cur, ok := byID[leafID] for ok && cur != nil { path = append([]*Category{cur}, path...) if cur.ParentID == 0 { break } cur, ok = byID[cur.ParentID] } return path }
graph TD
ROOT[根类目] --> A[服饰]
ROOT --> B[数码]
A --> A1[男装]
A --> A2[女装]
B --> B1[手机]
B1 --> B1L[智能手机 叶子]
var adapterRegistry = map[ProductType]ProductAdapter{ ProductTypeStandard: &StandardProductAdapter{}, ProductTypeService: &ServiceProductAdapter{}, }
funcRouteAdapter(spu *SPU) ProductAdapter { t := ProductType(spu.ProductType) if a, ok := adapterRegistry[t]; ok { return a } return adapterRegistry[ProductTypeStandard] }
classDiagram
class ProductAdapter {
<>
+Type() ProductType
+Validate()
+NormalizeForSearch()
+StockDimensions()
}
class StandardProductAdapter
class ServiceProductAdapter
ProductAdapter <|.. StandardProductAdapter
ProductAdapter <|.. ServiceProductAdapter
funcCheckBundleStock(ctx context.Context, b *BundleProduct)error { for _, it := range b.Items { n, err := inventory.GetStock(ctx, it.ChildSKUID, "") if err != nil { return err } if n < int64(it.Quantity) { return fmt.Errorf("insufficient stock for %s", it.ChildSKUID) } } returnnil }
funcAllocateBundlePrice(items []BundleItem, total int64)map[string]int64 { out := make(map[string]int64) var units int64 for _, it := range items { units += int64(it.Quantity) } if units == 0 { return out } var allocated int64 for i, it := range items { var share int64 if i == len(items)-1 { share = total - allocated } else { share = total * int64(it.Quantity) / units } out[it.ChildSKUID] = share allocated += share } return out }
graph TB
subgraph Layer1[第一层:基础数据服务层]
PC[商品中心系统]
end
subgraph Layer2[第二层:业务规则服务层]
INV[库存系统]
MKT[营销系统]
PRICE[计价引擎]
end
subgraph Layer3[第三层:核心交易流程层]
ORDER[订单系统]
PAY[支付系统]
end
subgraph Layer4[第四层:B端管理应用层]
LIST[商品上架系统]
OPS[B端运营系统]
end
%% 依赖关系(自下而上)
PC --> INV
PC --> PRICE
PC --> ORDER
INV --> ORDER
MKT --> PRICE
PRICE --> ORDER
ORDER --> PAY
LIST --> PC
LIST --> INV
LIST --> PRICE
OPS --> PC
OPS --> INV
OPS --> MKT
OPS --> PRICE
%% 样式
classDef layer1 fill:#e8f5e9,stroke:#4caf50,stroke-width:2px
classDef layer2 fill:#e3f2fd,stroke:#2196f3,stroke-width:2px
classDef layer3 fill:#fff3e0,stroke:#ff9800,stroke-width:2px
classDef layer4 fill:#f3e5f5,stroke:#9c27b0,stroke-width:2px
class PC layer1
class INV,MKT,PRICE layer2
class ORDER,PAY layer3
class LIST,OPS layer4
CREATETABLE user_operation_logs ( log_id INTPRIMARY KEY AUTO_INCREMENT, -- Unique identifier for each log entry user_id INTNOTNULL, -- ID of the user who made the edit entity_id INTNOTNULL, -- ID of the entity being edited entity_type VARCHAR(50) NOTNULL, -- Type of entity (e.g., SPU, SKU, Price, Stock) operation_type VARCHAR(50) NOTNULL, -- Type of operation (e.g., CREATE, UPDATE, DELETE) timestampTIMESTAMPDEFAULTCURRENT_TIMESTAMP, -- Time of the operation details TEXT, -- Additional details about the operation FOREIGN KEY (user_id) REFERENCES users(id) -- Assuming a users table exists ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
// Order 订单基础信息 type Order struct { ID string`json:"id"` UserID string`json:"user_id"` Type OrderType `json:"type"` Status OrderStatus `json:"status"` Amount float64`json:"amount"` Detail json.RawMessage `json:"detail"`// 不同类型订单的特殊字段 CreatedAt time.Time `json:"created_at"` UpdatedAt time.Time `json:"updated_at"` }
是不是犯错了!!!!,那么有什么好的解决方案吗? 数据库表引入一个额外字段 version ,每次更新时,判断表中的版本号与请求参数携带的版本号是否一致。这个版本字段可以是时间戳 复制 update order set logistics_num = #{logistics_num} , version = #{version} + 1 where order_id= 1111 and version = #{version}
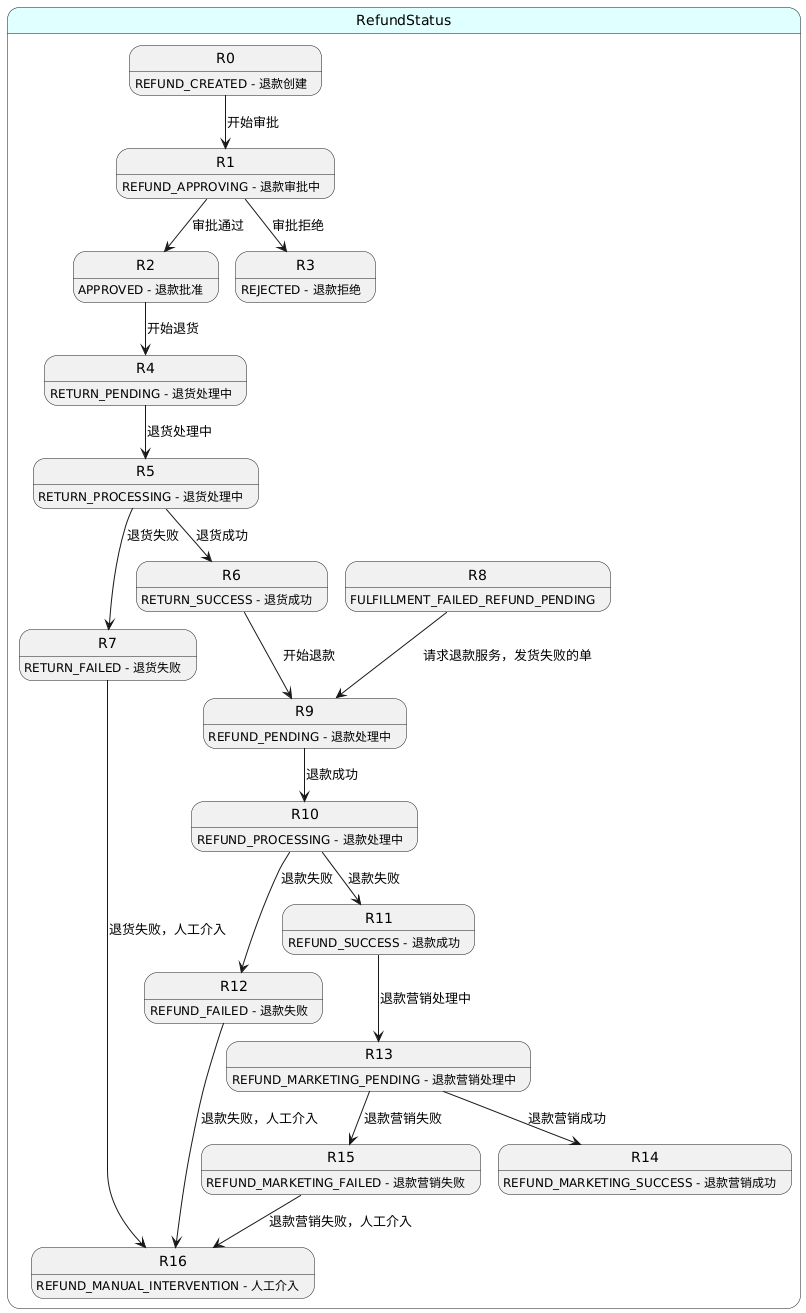
秒杀系统中的库存管理和订单蓄洪
常见的库存扣减方式有: 下单减库存: 即当买家下单后,在商品的总库存中减去买家购买数量。下单减库存是最简单的减库存方式,也是控制最精确的一种,但是有些人下完单可能并不会付款。 付款减库存: 即买家下单后,并不立即减库存,而是等到有用户付款后才真正减库存,否则库存一直保留给其他买家。但因为付款时才减库存,如果并发比较高,有可能出现买家下单后付不了款的情况,因为可能商品已经被其他人买走了。 预扣库存: 这种方式相对复杂一些,买家下单后,库存为其保留一定的时间(如 30 分钟),超过这个时间,库存将会自动释放,释放后其他买家就可以继续购买。在买家付款前,系统会校验该订单的库存是否还有保留:如果没有保留,则再次尝试预扣; 方案一:数据库乐观锁扣减库存 通常在扣减库存的场景下使用行级锁,通过数据库引擎本身对记录加锁的控制,保证数据库的更新的安全性,并且通过where语句的条件,保证库存不会被减到 0 以下,也就是能够有效的控制超卖的场景。 先查库存 然后乐观锁更新:update … set amount = amount - 1 where id = $id and amount = x 设置数据库的字段数据为无符号整数,这样减后库存字段值小于零时 SQL 语句会报错 方案二:redis 扣减库存,异步同步到DB redis 原子操作扣减库存 异步通过MQ消息同步到DB
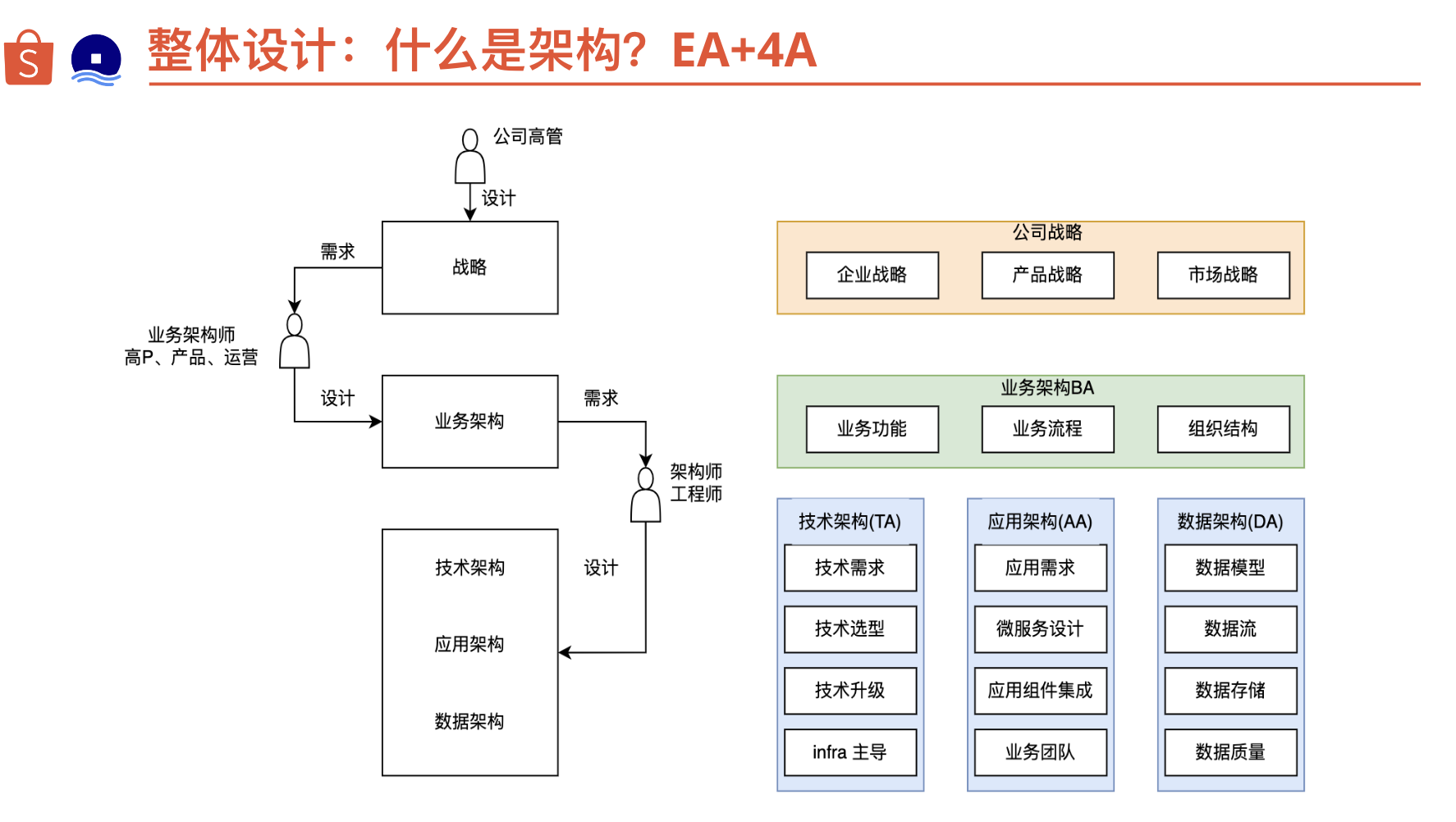
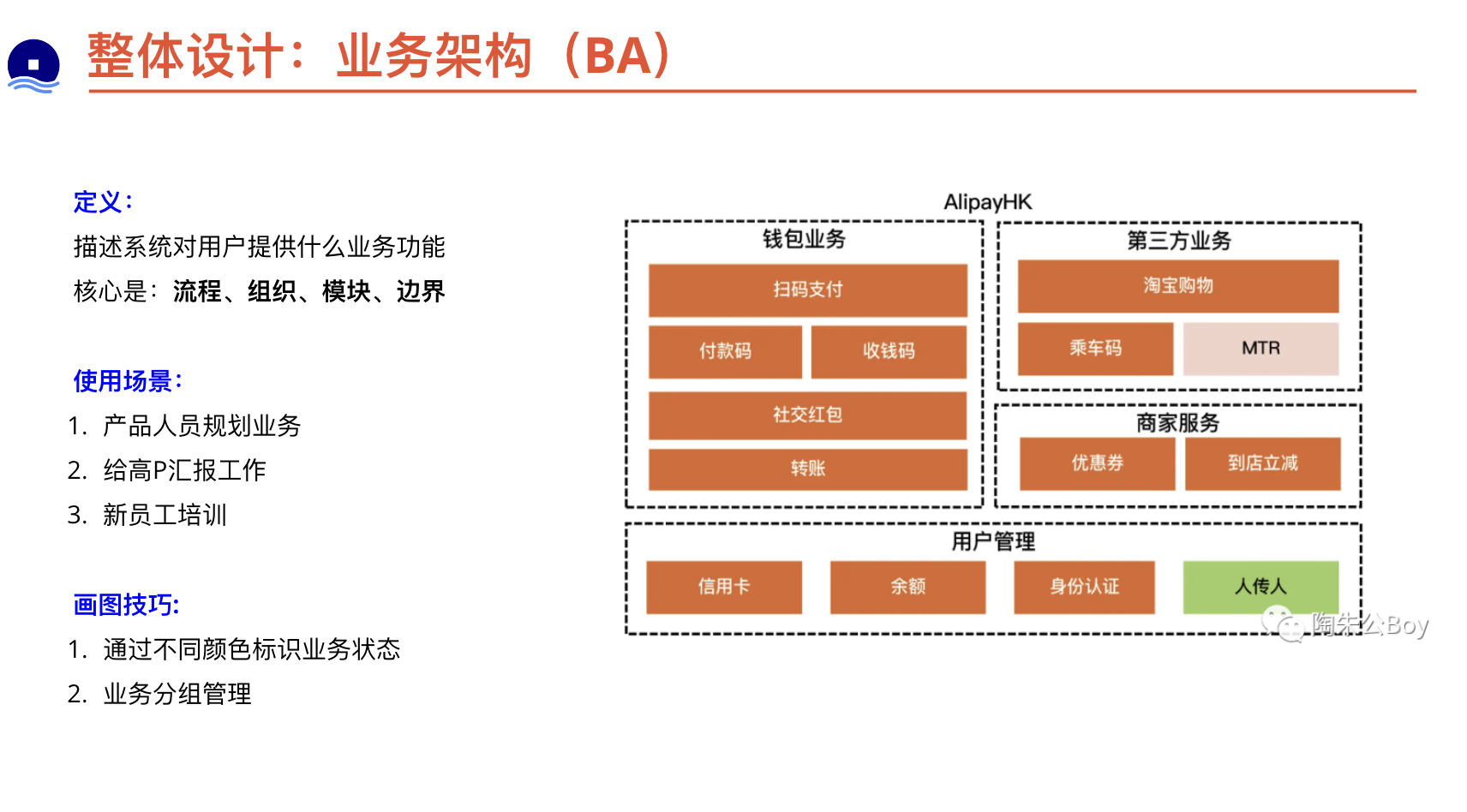
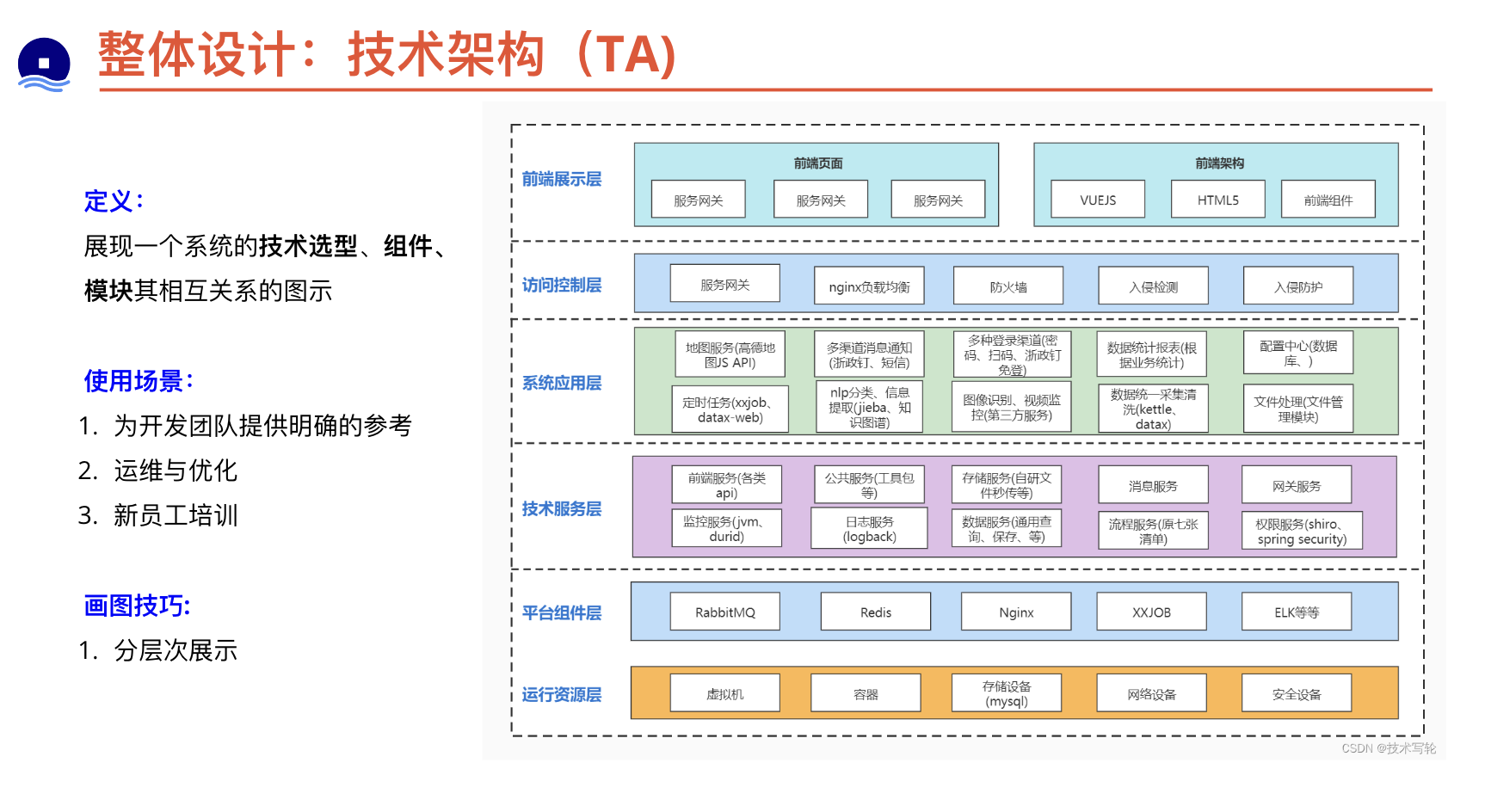
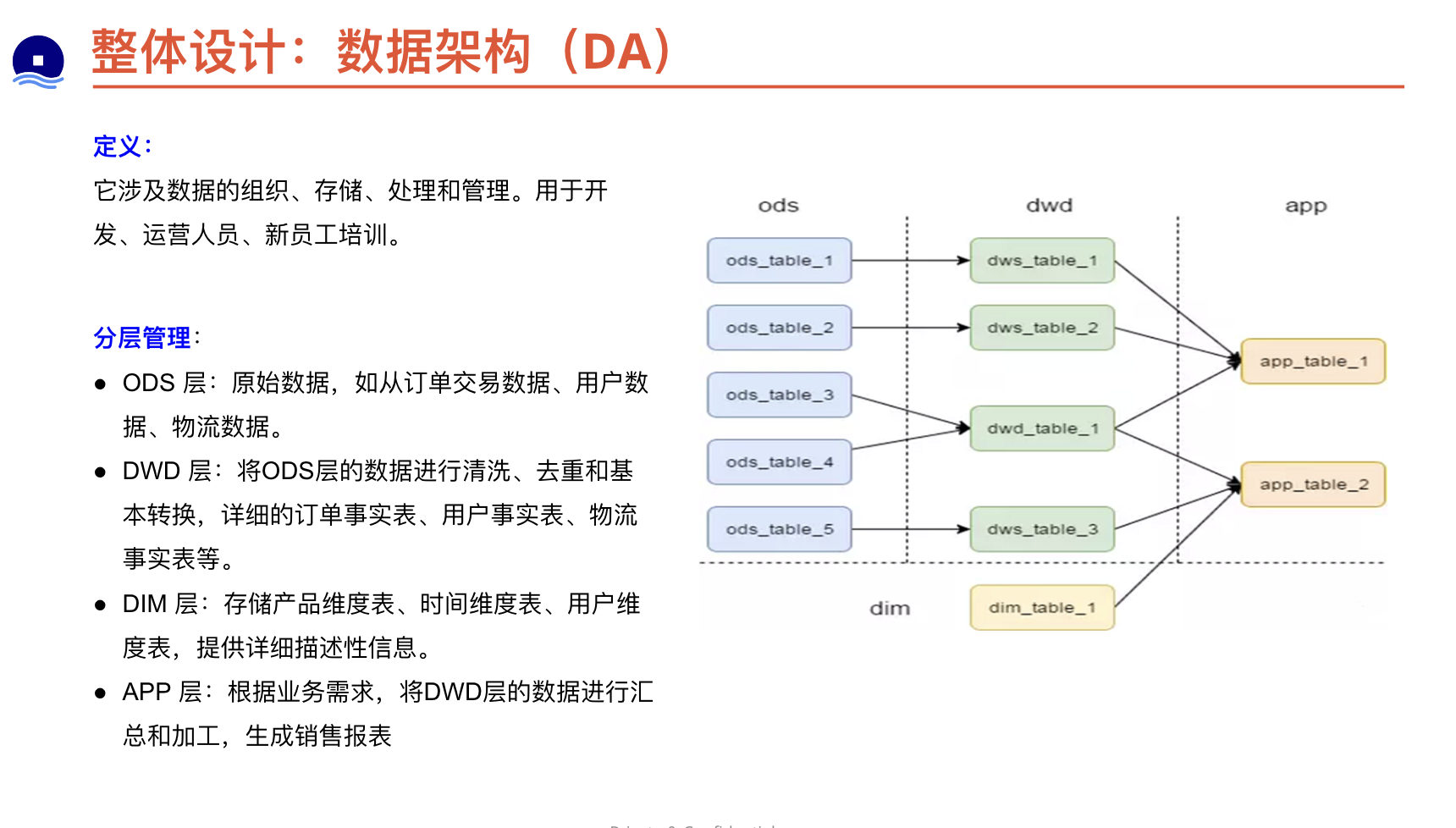
为设计文档的目标读者提供理解详细设计所需的背景信息。按读者范围来提供背景。见上文关于目标读者的圈定。设计文档应该是“自足的”(self-contained),即应该为读者提供足够的背景知识,使其无需进一步的查阅资料即可理解后文的设计。保持简洁,通常以几段为宜,每段简要介绍即可。如果需要向读者提供进一步的信息,最好只提供链接。警惕知识的诅咒(知识的诅咒(Curse of knowledge)是一种认知偏差,指人在与他人交流的时候,下意识地假设对方拥有理解交流主题所需要的背景知识)
SOLID 原则是一套比较经典且流行的架构原则(主要还是名字起得好): 单一职责:与 Unix 哲学所倡导的“Do one thing and do it well”不谋而合; 开闭原则:用新增(扩展)来取代修改(破坏现有封装),这与函数式的 immutable 思想也有异曲同工之妙; 里式替换:父类能够出现的地方子类一定能够出现,这样它们之间才算是具备继承的“Is-A”关系; 接口隔离:不要让一个类依赖另一个类中用不到的接口,简单说就是最小化组件之间的接口依赖和耦合;
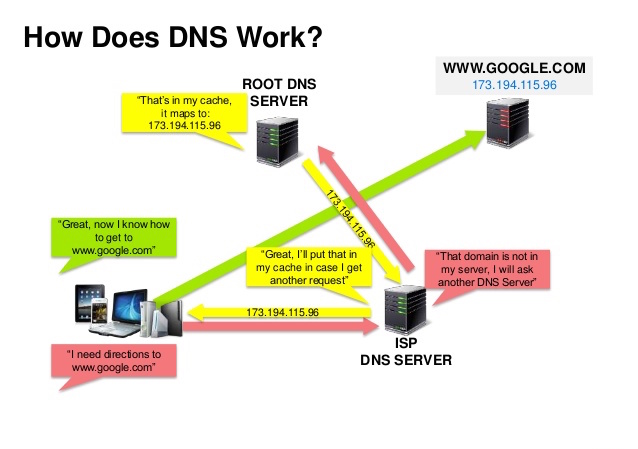
域名系统是把 www.example.com 等域名转换成 IP 地址。域名系统是分层次的,一些 DNS 服务器位于顶层。当查询(域名) IP 时,路由或 ISP 提供连接 DNS 服务器的信息。较底层的 DNS 服务器缓存映射,它可能会因为 DNS 传播延时而失效。DNS 结果可以缓存在浏览器或操作系统中一段时间,时间长短取决于存活时间 TTL。
不论请求成功或失败,始终返回 200 http status code,在 HTTP Body 中包含用户账号没有找到的错误信息:
1 2 3 4 5 6 7 8 9 10 11 12 13
如: Facebook API 的错误 Code 设计,始终返回 200 http status code: { "error": { "message": "Syntax error \"Field picture specified more than once. This is only possible before version 2.1\" at character 23: id,name,picture,picture", "type": "OAuthException", "code": 2500, "fbtrace_id": "xxxxxxxxxxx" } }
缺点: 对于每一次请求,我们都要去解析 HTTP Body,从中解析出错误码和错误信息
返回 http 404 Not Found 错误码,并在 Body 中返回简单的错误信息:
1 2 3 4 5
如: Twitter API 的错误设计 根据错误类型,返回合适的 HTTP Code,并在 Body 中返回错误信息和自定义业务 Code
HTTP/1.1 400 Bad Request {"errors":[{"code":215,"message":"Bad Authentication data."}]}
返回 http 404 Not Found 错误码,并在 Body 中返回详细的错误信息:
1 2 3 4 5 6 7
如: 微软 Bing API 的错误设计,会根据错误类型,返回合适的 HTTP Code,并在 Body 中返回详尽的错误信息 HTTP/1.1 400 { "code": 100101, "message": "Database error", "reference": "https://github.com/xx/tree/master/docs/guide/faq/xxxx" }
{"id":1,"content":"Elasticsearch is a search engine"} {"id":2,"content":"Lucene is a search library"} {"id":3,"content":"Elasticsearch is built on Lucene"}
倒排索引表:
Term(关键词)
Document IDs(文档列表)
Frequency(词频)
elasticsearch
[1, 3]
2
search
[1, 2]
2
engine
[1]
1
lucene
[2, 3]
2
library
[2]
1
built
[3]
1
**查询 “elasticsearch search”**:
查倒排索引表:elasticsearch → [1,3],search → [1,2]
求交集:[1,3] ∩ [1,2] = [1]
返回文档 ID=1
Analyzer 工作流程
Analyzer 三大组件:
组件
作用
示例
Character Filter
字符预处理(去特殊字符)
<html> → 空
Tokenizer
分词
Elasticsearch is → [Elasticsearch, is]
Token Filter
词项后处理(小写、停用词)
[Elasticsearch, is] → [elasticsearch]
示例:
1 2 3 4 5 6 7 8 9 10 11
// 输入 "Elasticsearch is a SEARCH Engine!!!"
// Character Filter: 去掉特殊字符 "Elasticsearch is a SEARCH Engine"
Go and C++ are two different programming languages with different design goals, syntax, and feature sets. Here’s a brief comparison of the two:
Syntax: Go has a simpler syntax than C++. It uses indentation for block structure and has fewer keywords and symbols. C++ has a more complex syntax with a lot of features that can make it harder to learn and use effectively.
Memory Management: C++ gives the programmer more control over memory management through its support for pointers, manual memory allocation, and deallocation. Go, on the other hand, uses a garbage collector to automatically manage memory, making it less error-prone.
Concurrency: Go has built-in support for concurrency through goroutines and channels, which make it easier to write concurrent code. C++ has a thread library that can be used to write concurrent code, but it requires more manual management of threads and locks.
Performance: C++ is often considered a high-performance language, and it can be used for system-level programming and performance-critical applications. Go is also fast but may not be as fast as C++ in some cases.
Libraries and Frameworks: C++ has a vast ecosystem of libraries and frameworks that can be used for a variety of applications, from game development to machine learning. Go’s ecosystem is smaller, but it has good support for web development and distributed systems.
Overall, the choice of programming language depends on the project requirements, the available resources, and the developer’s expertise. Both Go and C++ have their strengths and weaknesses, and the best choice depends on the specific needs of the project.
func main() { done := make(chan struct{}) s := make(chan int) go func() { s <- 1 close(done) }() fmt.Println(<-s) <-done } func main() { sem := make(chan struct{}, 2) //two groutine var wg sync.WaitGroup for i := 0; i < 10; i++ { wg.Add(1) go func(id int) { defer wg.Done() defer func() { <-sem }() sem <- struct{}{} time.Sleep(1 * time.Second) fmt.Println("id=", id) }(i) } wg.Wait() } func main() { go func() { tick := time.Tick(1 * time.Second) for { select { case <-time.After(5 * time.Second): fmt.Println("time out") case <-tick: fmt.Println("time tick 1s") default: fmt.Println("default") } } }() <-(chan struct{})(nil) }
Go并发模型 (Goroutine/channel/GMP)
what’s CSP?
The Communicating Sequential Processes (CSP) model is a theoretical model of concurrent programming that was first introduced by Tony Hoare in 1978. The CSP model is based on the idea of concurrent processes that communicate with each other by sending and receiving messages through channels.The Go programming language provides support for the CSP model through its built-in concurrency features, such as goroutines and channels. In Go, concurrent processes are represented by goroutines, which are lightweight threads of execution. The communication between goroutines is achieved through channels, which provide a mechanism for passing values between goroutines in a safe and synchronized manner.
Which is Goroutine ?
Goroutines are lightweight, user-level threads of execution that run concurrently with other goroutines within the same process.
Unlike traditional threads, goroutines are managed by the Go runtime, which automatically schedules and balances their execution across multiple CPUs and makes efficient use of available system resources.
Goroutines, threads, and processes are all mechanisms for writing concurrent and parallel code, but they have some important differences:
Goroutines: A goroutine is a lightweight, user-level thread of execution that runs concurrently with other goroutines within the same process. Goroutines are managed by the Go runtime, which automatically schedules and balances their execution across multiple CPUs. Goroutines require much less memory and have much lower overhead compared to threads, allowing for many goroutines to run simultaneously within a single process.
Threads: A thread is a basic unit of execution within a process. Threads are independent units of execution that share the same address space as the process that created them. This allows threads to share data and communicate with each other, but also introduces the need for explicit synchronization to prevent race conditions and other synchronization issues.
Processes: A process is a self-contained execution environment that runs in its own address space. Processes are independent of each other, meaning that they do not share memory or other resources. Communication between processes requires inter-process communication mechanisms, such as pipes, sockets, or message queues.
In general, goroutines provide a more flexible and scalable approach to writing concurrent code compared to threads, as they are much lighter and more efficient, and allow for many more concurrent units of execution within a single process. Processes provide a more secure and isolated execution environment, but have higher overhead and require more explicit communication mechanisms.
Why is Goroutine lighter and more efficient than thread or process?
Stack size: Goroutines have a much smaller stack size compared to threads. The stack size of a goroutine is dynamically adjusted by the Go runtime, based on the needs of the goroutine. This allows for many more goroutines to exist simultaneously within a single process, as they require much less memory.
Scheduling: Goroutines are scheduled by the Go runtime, which automatically balances and schedules their execution across multiple CPUs. This eliminates the need for explicit thread management and synchronization, reducing overhead.
Context switching: Context switching is the process of saving and restoring the state of a running thread in order to switch to a different thread. Goroutines have a much lower overhead for context switching compared to threads, as they are much lighter and require less state to be saved and restored.
Resource sharing: Goroutines share resources with each other and with the underlying process, eliminating the need for explicit resource allocation and deallocation. This reduces overhead and allows for more efficient use of system resources.
Overall, the combination of a small stack size, efficient scheduling, low overhead context switching, and efficient resource sharing makes goroutines much lighter and more efficient than threads or processes, and allows for many more concurrent units of execution within a single process.
Cooperative (协作式). The scheduler uses a cooperative scheduling model, which means that goroutines voluntarily yield control to the runtime when they are blocked or waiting for an event.
Timer-based preemption. The scheduler uses a technique called timer-based preemption to interrupt the execution of a running goroutine and switch to another goroutine if it exceeds its time slice
Work-stealing. The scheduler uses a work-stealing algorithm, where each CPU has its own local run queue, and goroutines are dynamically moved between run queues to balance the o balance the load and improve performance.
no explicit prioritization. The Go runtime scheduler does not provide explicit support for prioritizing goroutines. Instead, it relies on the cooperative nature of goroutines to ensure that all goroutines make progress. In a well-designed Go program, the program should be designed such that all goroutines make progress in a fair and balanced manner.
G 的数量可以远远大于 M 的数量,换句话说,Go 程序可以利用少量的内核级线程来支撑大量 Goroutine 的并发。多个 Goroutine 通过用户级别的上下文切换来共享内核线程 M 的计算资源,但对于操作系统来说并没有线程上下文切换产生的性能损耗,支持任务窃取(work-stealing)策略:为了提高 Go 并行处理能力,调高整体处理效率,当每个 P 之间的 G 任务不均衡时,调度器允许从 GRQ,或者其他 P 的 LRQ 中获取 G 执行。
如果在 Goroutine 去执行一个 sleep 操作,导致 M 被阻塞了。Go 程序后台有一个监控线程 sysmon,它监控那些长时间运行的 G 任务然后设置可以强占的标识符,别的 Goroutine 就可以抢先进来执行。
What are the states of Goroutine and how do they flow?
协程的状态流转?Grunnable、Grunning、Gwaiting
In Go, a Goroutine can be in one of several states during its lifetime. The states are:
New: The Goroutine is created but has not started executing yet.
Running: The Goroutine is executing on a machine-level thread.
Waiting: The Goroutine is waiting for some external event, such as I/O, channel communication, or a timer.
Sleeping: The Goroutine is sleeping, or waiting for a specified amount of time.
Dead: The Goroutine has completed its execution and is no longer running.
In summary, the lifetime of a Goroutine in Go starts when it is created and ends when it completes its execution or encounters a panic, and can be influenced by synchronization mechanisms such as channels and wait groups.
What are the memory leak scenarios in Go language?
Goroutine leaks: If a goroutine is created and never terminated, it can result in a memory leak. This can occur when a program creates a goroutine to perform a task but fails to provide a mechanism for the goroutine to terminate, such as a channel to receive a signal to stop.
Leaked closures: Closures are anonymous functions that capture variables from their surrounding scope. If a closure is created and assigned to a global variable, it can result in a memory leak, as the closure will continue to hold onto the captured variables even after they are no longer needed.
Incorrect use of channels: Channels are a mechanism for communicating between goroutines. If a program creates a channel but never closes it, it can result in a memory leak. Additionally, if a program receives values from a channel but never discards them, they will accumulate in memory and result in a leak.
Unclosed resources: In Go, it’s important to close resources, such as files and network connections, when they are no longer needed. Failure to do so can result in a memory leak, as the resources and their associated memory will continue to be held by the program.
Unreferenced objects: In Go, unreferenced objects are objects that are no longer being used by the program but still exist in memory. This can occur when an object is created and never explicitly deleted or when an object is assigned a new value and the old object is not properly disposed of. By following best practices and being mindful of these common scenarios, you can help to avoid memory leaks in your Go programs. Additionally, you can use tools such as the Go runtime profiler to detect and diagnose memory leaks in your programs.
Marking phase: In this phase, the Go runtime identifies all objects that are accessible by the program and marks them as reachable. Objects that are not marked as reachable are considered unreachable and eligible for collection.
Sweeping phase: In this phase, the Go runtime scans the memory heap and frees all objects that are marked as unreachable. The memory space occupied by these objects is now available for future allocation.
Compacting phase: In this phase, the Go runtime rearranges the remaining objects on the heap to reduce fragmentation and minimize the impact of future allocations and deallocations.
标记-清扫: 标记清扫是古老的垃圾回收算法,出现在70年代。通过指定每个内存阈值或者时间长度,垃圾回收器会挂起用户程序,也称为STW(stop the world)。垃圾回收器gc会对程序所涉及的所有对象进行一次遍历以确定哪些内存单元可以回收,因此分为标记(mark)和清扫(sweep),标记阶段标明哪些内存在使用不能回收,清扫阶段将不需要的内存单元释放回收。标记清扫法最大的问题是需要STW,当程序使用的内存较多时,其性能会比较差,延时较高。
In Go, a closure is a function that has access to variables from its outer (enclosing) function’s scope. The closure “closes over” the variables, meaning that it retains access to them even after the outer function has returned. This makes closures a powerful tool for encapsulating data and functionality and for creating reusable code.
funcmemoize(f func(int)int) func(int)int { cache := make(map[int]int) returnfunc(n int)int { if val, ok := cache[n]; ok { return val } result := f(n) cache[n] = result return result } }
funcfibonacci(n int)int { if n <= 1 { return n } return fibonacci(n-1) + fibonacci(n-2) }
funcmain() { fib := memoize(fibonacci) for i := 0; i < 10; i++ { fmt.Println(fib(i)) } }
Factorial
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
package main
import"fmt"
funcmain() { factorial := func(n int)int { if n <= 1 { return1 } return n * factorial(n-1) }
// Local per-P Pool appendix.
type poolLocalInternal struct {
private interface{} // Can be used only by the respective P.
shared []interface{} // Can be used by any P.
Mutex // Protects shared.
}
$ go build -gcflags=-m test_esc.go command-line-arguments ./test_esc.go:9:17: Sum make([]int, count) does not escape ./test_esc.go:23:13: answer escapes to heap ./test_esc.go:23:13: main ... argument does not escape
The Go runtime is a collection of software components that provide essential services for Go programs, including memory management, garbage collection, scheduling, and low-level system interaction. The runtime is responsible for managing the execution of Go programs and for providing a consistent, predictable environment for Go code to run in.
At a high level, the Go runtime is responsible for several core tasks:
Memory management: The runtime manages the allocation and deallocation of memory used by Go programs, including the stack, heap, and other data structures.
Garbage collection: The runtime automatically identifies and frees memory that is no longer needed by a program, preventing memory leaks and other related issues.
Scheduling: The runtime manages the scheduling of Goroutines, the lightweight threads used by Go programs, to ensure that they are executed efficiently and fairly.
Low-level system interaction: The runtime provides an interface for Go programs to interact with low-level system resources, including system calls, I/O operations, and other low-level functionality.
The Go runtime is an essential component of the Go programming language, and it is responsible for many of the language’s unique features and capabilities. By providing a consistent, efficient environment for Go code to run in, the runtime enables developers to write high-performance, scalable software that can run on a wide range of platforms and architectures.
找一个golang编译的可执行程序test,info file查看其入口地址:gdb test,info files (gdb) info files Symbols from “/home/terse/code/go/src/learn_golang/test_init/main”. Local exec file: /home/terse/code/go/src/learn_golang/test_init/main’, file type elf64-x86-64. Entry point: 0x452110 …..
利用断点信息找到目标文件信息: (gdb) b *0x452110 Breakpoint 1 at 0x452110: file /usr/local/go/src/runtime/rt0_linux_amd64.s, line 8.
依次找到对应的文件对应的行数,设置断点,调到指定的行,查看具体的内容: (gdb) b _rt0_amd64 (gdb) b b runtime.rt0_go 至此,由汇编代码针对特定平台实现的引导过程就全部完成了,后续的代码都是用Go实现的。分别实现命令行参数初始化,内存分配器初始化、垃圾回收器初始化、协程调度器的初始化等功能。
//go:notinheap type stackpoolItem struct { mu mutex span mSpanList }
// Global pool of large stack spans. var stackLarge struct { lock mutex free [heapAddrBits - pageShift]mSpanList // free lists by log_2(s.npages) }
funcstackinit() { if _StackCacheSize&_PageMask != 0 { throw("cache size must be a multiple of page size") } for i := range stackpool { stackpool[i].item.span.init() lockInit(&stackpool[i].item.mu, lockRankStackpool) } for i := range stackLarge.free { stackLarge.free[i].init() lockInit(&stackLarge.lock, lockRankStackLarge) } }
newproc 需要一个初始的stack
1 2 3 4 5 6
if gp.stack.lo == 0 { // Stack was deallocated in gfput or just above. Allocate a new one. systemstack(func() { gp.stack = stackalloc(startingStackSize) }) gp.stackguard0 = gp.stack.lo + _StackGuard
funcproduce() { a := total / producerLimit b := total % producerLimit var wg sync.WaitGroup for i := 0; i < int(producerLimit); i++ { batch := a if i < int(b) { batch += 1 } wg.Add(1) gofunc(x int32) { defer wg.Done() for j := 0; j < int(x); j++ { num := rand.Intn(10) atomic.AddInt32(&AtomicSum, int32(num)) Q <- int32(num) } }(batch) } gofunc() { wg.Wait() close(Q) }() }
funcconsumer()int32 { var wg sync.WaitGroup for i := 0; i < int(consumerLimit); i++ { wg.Add(1) gofunc() { defer wg.Done() var batchSum int32 = 0 for num := range Q { batchSum += num } SumQ <- batchSum }() }
gofunc() { wg.Wait() close(SumQ) }()
var ans int32 = 0 for sum := range SumQ { ans += sum } return ans }
const bookNormalStockScript = ` local key = KEYS[1] local book_num = tonumber(ARGV[1]) local platform = tonumber(ARGV[2]) or1
local normal_stock = tonumber(redis.call("HGET", key, "0")) or0 if book_num > normal_stock then return-1 end redis.call("hincrby", key, "0", -book_num) redis.call("HINCRBY", key, "booking", book_num) end
graph LR
A[创建Hash] --> B{元素数<=512 且 值长度<=64B?}
B -->|是| C[ziplist 压缩列表]
B -->|否| D[hashtable 哈希表]
C -->|超过阈值| D
style C fill:#e8f5e9
style D fill:#e1f5fe
GIL(Global Interpreter Lock)全局解释锁,CPython在解释执行任何Python代码的时候,首先都需要they acquire GIL when running,release GIL when blocking for I/O。如果没有涉及I/O操作,只有CPU密集型操作时,解释器每隔100一段时间(100ticks)就会释放GIL。GIL是实现Python解释器的(Cython)时所引入的一个概念,不是Python的特性。 由于GIL的存在,使得Python对于计算密集型任务,多线程threading模块形同虚设,因为线程在实际运行的时候必须获得GIL,而GIL只有一个,因此无法发挥多核的优势。为了绕过GIL的限制,只能使用multiprocessing等多进程模块,每个进程各有一个CPython解释器,也就各有一个GIL。
class TemplateTracker { public: TemplateTracker();
void SetSampling(unsigned int sample_i, unsigned int sample_j); void SetLambda(double lamda); void SetIterationMax(unsigned int n); void SetPyramidal(unsigned int nlevels, unsigned int level_to_stop); void SetUseTemplateSelect(bool bselect); void SetThresholdGradient(float threshold);
int Init(unsigned char* imgData, unsigned int h, unsigned int w, int* ref, unsigned int points_num, bool bshow); int InitWithMask(unsigned char* imgData, unsigned int h, unsigned int w, int* ref, unsigned int points_num, bool bshow, unsigned char* mask_data,int h2,int w2);
int ComputeH(unsigned char* imgData, unsigned int h,unsigned int w,float* H_matrix,int num); int ComputeHWithMask(unsigned char* imgData, unsigned int h,unsigned int w,float* H_matrix,int num,unsigned char* mask_data,int h2,int w2); void Reset(); ~TemplateTracker(); void say_hello();
%apply (unsigned char* IN_ARRAY2, int DIM1, int DIM2) {(unsigned char* imgData, unsigned int h, unsigned int w)} %apply (unsigned char* IN_ARRAY2, int DIM1, int DIM2) {(unsigned char* mask_data, int h2, int w2)} %apply (int* IN_ARRAY1, int DIM1) {(int* ref, unsigned int points_num)} %apply (float* INPLACE_ARRAY1, int DIM1) {(float* H_matrix,int num)}
NUMS = 100000 def job2(): ''' cpu and io ''' for i in range(NUMS): print("hello,world")
def multi_threads(num,job): threads = [] for i in range(num): t = threading.Thread(target=job,args=()) threads.append(t) for t in threads: t.start() for t in threads: t.join()
def multi_process(num,job): process = [] for i in range(num): p = multiprocessing.Process(target=job,args=()) process.append(p) for p in process: p.start() for p in process: p.join()
编码方式:utf8mb4:通过 show variables like ‘character_set_%’; 可以查看系统默认字符集。mysql中有utf8和utf8mb4两种编码,在mysql中请大家忘记utf8,永远使用utf8mb4。这是mysql的一个遗留问题,mysql中的utf8最多只能支持3bytes长度的字符编码,对于一些需要占据4bytes的文字,mysql的utf8就不支持了,要使用utf8mb4才行
-- 逻辑表结构 CREATETABLEuser ( id INTPRIMARY KEY, name VARCHAR(50), age INT );
-- 实际物理存储(包含隐藏列) | id | name | age | DB_TRX_ID | DB_ROLL_PTR | DB_ROW_ID | |----|-------|-----|-----------|-------------|-----------| |1| Alice |25|100|0x7f3a... |NULL|
funcTransferMoney(ctx context.Context, fromUserID, toUserID int64, amount decimal.Decimal)error { tx, err := db.BeginTx(ctx, nil) if err != nil { return err } defer tx.Rollback() // 锁定两个账户(注意:按照ID顺序加锁避免死锁) accounts := []int64{fromUserID, toUserID} sort.Slice(accounts, func(i, j int)bool { return accounts[i] < accounts[j] }) var balances = make(map[int64]decimal.Decimal) for _, uid := range accounts { var balance decimal.Decimal err = tx.QueryRowContext(ctx, "SELECT balance FROM wallet WHERE user_id = ? FOR UPDATE", uid).Scan(&balance) if err != nil { return err } balances[uid] = balance } // 检查余额 if balances[fromUserID].LessThan(amount) { return errors.New("insufficient balance") } // 扣款和入账 _, err = tx.ExecContext(ctx, "UPDATE wallet SET balance = balance - ? WHERE user_id = ?", amount, fromUserID) if err != nil { return err } _, err = tx.ExecContext(ctx, "UPDATE wallet SET balance = balance + ? WHERE user_id = ?", amount, toUserID) if err != nil { return err } return tx.Commit() }
锁等待监控
1 2 3 4 5 6 7 8
-- 查看当前锁等待情况 SELECT * FROM information_schema.innodb_locks; SELECT * FROM information_schema.innodb_lock_waits; SELECT * FROM performance_schema.data_locks; -- MySQL 8.0+
-- 设置锁等待超时 SET innodb_lock_wait_timeout = 5; -- 默认50秒
// ❌ 错误:没有检查影响行数 _, err := db.Exec("UPDATE ... WHERE id = ? AND version = ?", id, version) if err != nil { return err } // 即使version不匹配,err也是nil,但实际没更新成功!
// ✅ 正确:检查affected_rows result, err := db.Exec("UPDATE ... WHERE id = ? AND version = ?", id, version) if err != nil { return err } affected, _ := result.RowsAffected() if affected ==0 { return errors.New("version conflict or record not found") }
方案1: -- SQL语句 SELECT * FROM employees ORDER BY salary DESC LIMIT 10 OFFSET 100000;
方案2: CREATE INDEX idx_salary ON employees(salary);
-- SQL语句 SELECT * FROM employees ORDER BY salary DESC LIMIT 10 OFFSET 100000;
方案3: CREATE INDEX idx_salary ON employees(salary);
-- SQL语句 SELECT e.* FROM employees e INNER JOIN ( SELECT id FROM employees ORDER BY salary DESC LIMIT 10 OFFSET 100000 ) t ON e.id = t.id ORDER BY e.salary DESC;
方案4: CREATE INDEX idx_salary_name_age ON employees(salary, name, age);
-- SQL语句(只查询索引中的列) SELECT id, salary, name, age FROM employees ORDER BY salary DESC LIMIT 10 OFFSET 100000;
方案5:
-- 索引 CREATE INDEX idx_salary ON employees(salary);
-- SQL语句 SELECT * FROM employees WHERE id >= ( SELECT id FROM employees ORDER BY salary DESC LIMIT 1 OFFSET 100000 ) ORDER BY salary DESC LIMIT 10;
方案6:
-- 索引 CREATE INDEX idx_salary_id ON employees(salary DESC, id DESC);
-- 第一次查询(第1页) SELECT * FROM employees ORDER BY salary DESC, id DESC LIMIT 10; -- 返回: 最后一行 salary=99990, id=12345
-- 第N次查询(基于上次的最后一行) SELECT * FROM employees WHERE salary < 99990 OR (salary = 99990 AND id < 12345) ORDER BY salary DESC, id DESC LIMIT 10;
explain select * from test_xxxx_tab txt order by id limit 10000,10; explain SELECT * from test_xxxx_tab txt where id >= (select id from test_xxxx_tab txt order by id limit 10,1) limit 10; id列:在复杂的查询语句中包含多个查询使用id标示 select_type:select/subquery/derived/union table: 显示对应行正在访问哪个表 type:访问类型,关联类型。非常重要,All,index,range,ref,const, possible_keys: 显示可以使用哪些索引列 key列:显示mysql决定使用哪个索引来优化对该表的访问 key_len:显示在索引里使用的字节数 rows:为了找到所需要的行而需要读取的行数
慢查询日志样例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
# Time: 2022-05-10T10:15:32.123456Z # User@Host: myuser[192.168.0.1] @ localhost [] Id: 12345 # Query_time: 3.456789 Lock_time: 0.123456 Rows_sent: 10 Rows_examined: 100000 SET timestamp=1657475732; SELECT * FROM orders WHERE customer_id = 1001 ORDER BY order_date DESC LIMIT 10; 这个慢查询日志示例包含以下重要的信息:
时间戳(Time): 日志记录的时间,以 UTC 时间表示。 用户和主机(User@Host): 执行查询的用户和主机地址。 连接 ID(Id): 表示执行查询的连接 ID。 查询时间(Query_time): 查询执行所花费的时间,以秒为单位。 锁定时间(Lock_time): 在执行查询期间等待锁定资源所花费的时间,以秒为单位。 返回行数(Rows_sent): 查询返回的结果集中的行数。 扫描行数(Rows_examined): 在执行查询过程中扫描的行数。 时间戳(SET timestamp): 查询开始执行的时间戳。 查询语句(SELECT * FROM orders WHERE customer_id = 1001 ORDER BY order_date DESC LIMIT 10): 实际执行的查询语句
show global variables; show variables like '%max_connection%'; 查看最大连接数 show status like 'Threads%'; show processlist; show variables like '%connection%';
-- desc information_schema.tables; -- 查看 MySQL「所有库」的容量大小 SELECT table_schema AS '数据库', SUM(table_rows) AS '记录数', SUM(truncate(data_length / 1024 / 1024, 2)) AS '数据容量(MB)', SUM(truncate(index_length / 1024 / 1024, 2)) AS '索引容量(MB)', SUM(truncate(DATA_FREE / 1024 / 1024, 2)) AS '碎片占用(MB)' FROM information_schema.tables GROUP BY table_schema ORDER BY SUM(data_length) DESC, SUM(index_length) DESC; -- 指定书库查看表的数据量 SELECT table_schema as '数据库', table_name as '表名', table_rows as '记录数', truncate(data_length/1024/1024, 2) as '数据容量(MB)', truncate(index_length/1024/1024, 2) as '索引容量(MB)', truncate(DATA_FREE/1024/1024, 2) as '碎片占用(MB)' from information_schema.tables where table_schema='<数据库名>' order by data_length desc, index_length desc;
mysql登陆: mysql -h主机 -P端口 -u用户 -p密码 SET PASSWORD FOR ‘root‘@’localhost’ = PASSWORD(‘root’); create database wxquare_test; show databases; use wxquare_test;
UPDATE employees SET salary = CASE WHEN grade = 'A' THEN salary * 1.1 WHEN grade = 'B' THEN salary * 1.05 WHEN grade = 'C' THEN salary * 1.03 ELSE salary END WHERE department = 'IT';
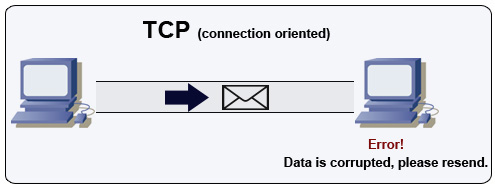
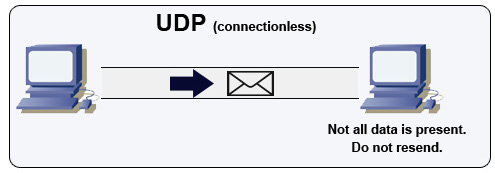
udp协议怎么做可靠传输? 由于在传输层UDP已经是不可靠的连接,那就要在应用层自己实现一些保障可靠传输的机制,简单来讲,要使用UDP来构建可靠的面向连接的数据传输,就要实现类似于TCP协议的,超时重传(定时器),有序接受 (添加包序号),应答确认 (Seq/Ack应答机制),滑动窗口流量控制等机制 (滑动窗口协议),等于说要在传输层的上一层(或者直接在应用层)实现TCP协议的可靠数据传输机制,比如使用UDP数据包+序列号,UDP数据包+时间戳等方法。目前已经有一些实现UDP可靠传输的机制,比如UDT(UDP-based Data Transfer Protocol)基于UDP的数据传输协议(UDP-based Data Transfer Protocol,简称UDT)是一种互联网数据传输协议。UDT的主要目的是支持高速广域网上的海量数据传输,而互联网上的标准数据传输协议TCP在高带宽长距离网络上性能很差。 顾名思义,UDT建于UDP之上,并引入新的拥塞控制和数据可靠性控制机制。UDT是面向连接的双向的应用层协议。它同时支持可靠的数据流传输和部分可靠的数据报传输。 由于UDT完全在UDP上实现,它也可以应用在除了高速数据传输之外的其它应用领域,例如点到点技术(P2P),防火墙穿透,多媒体数据传输等等

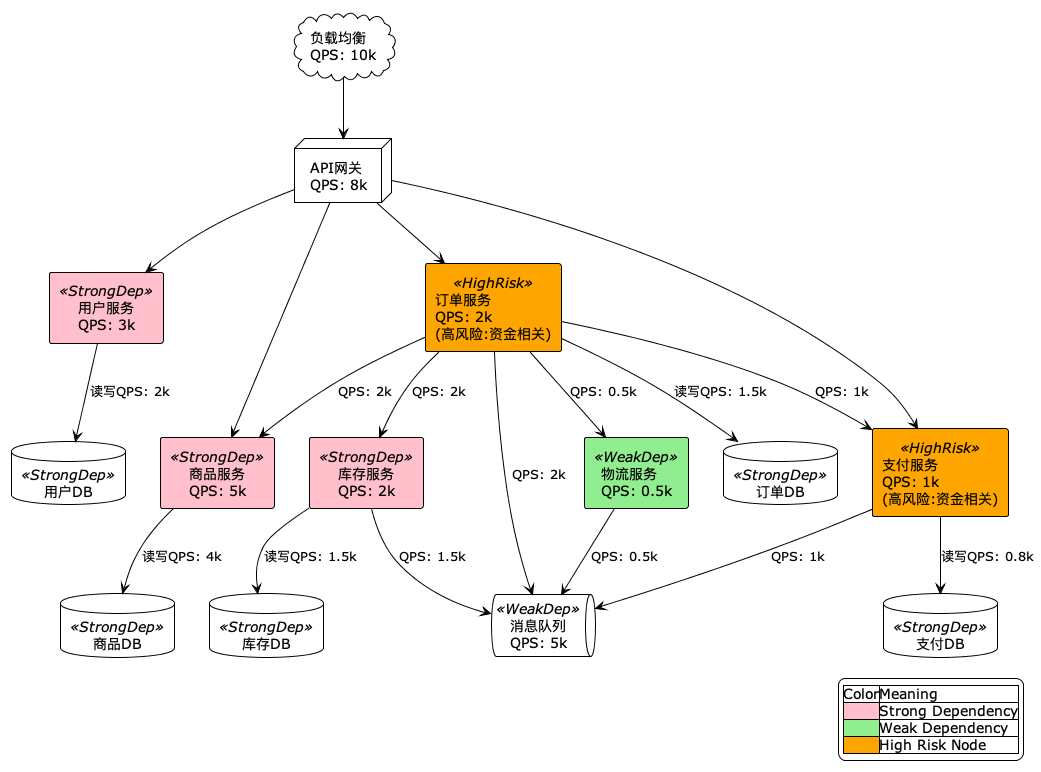

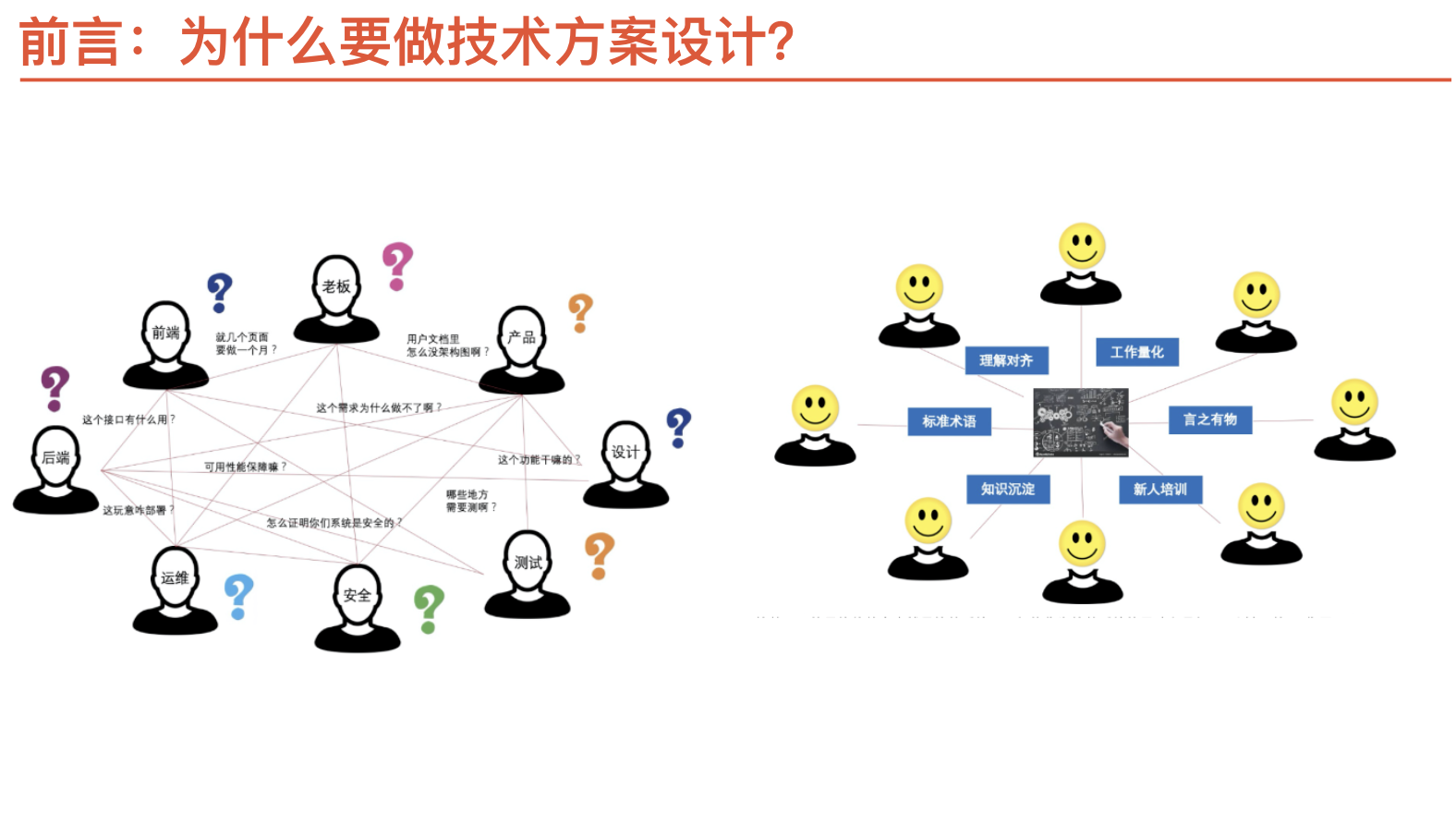
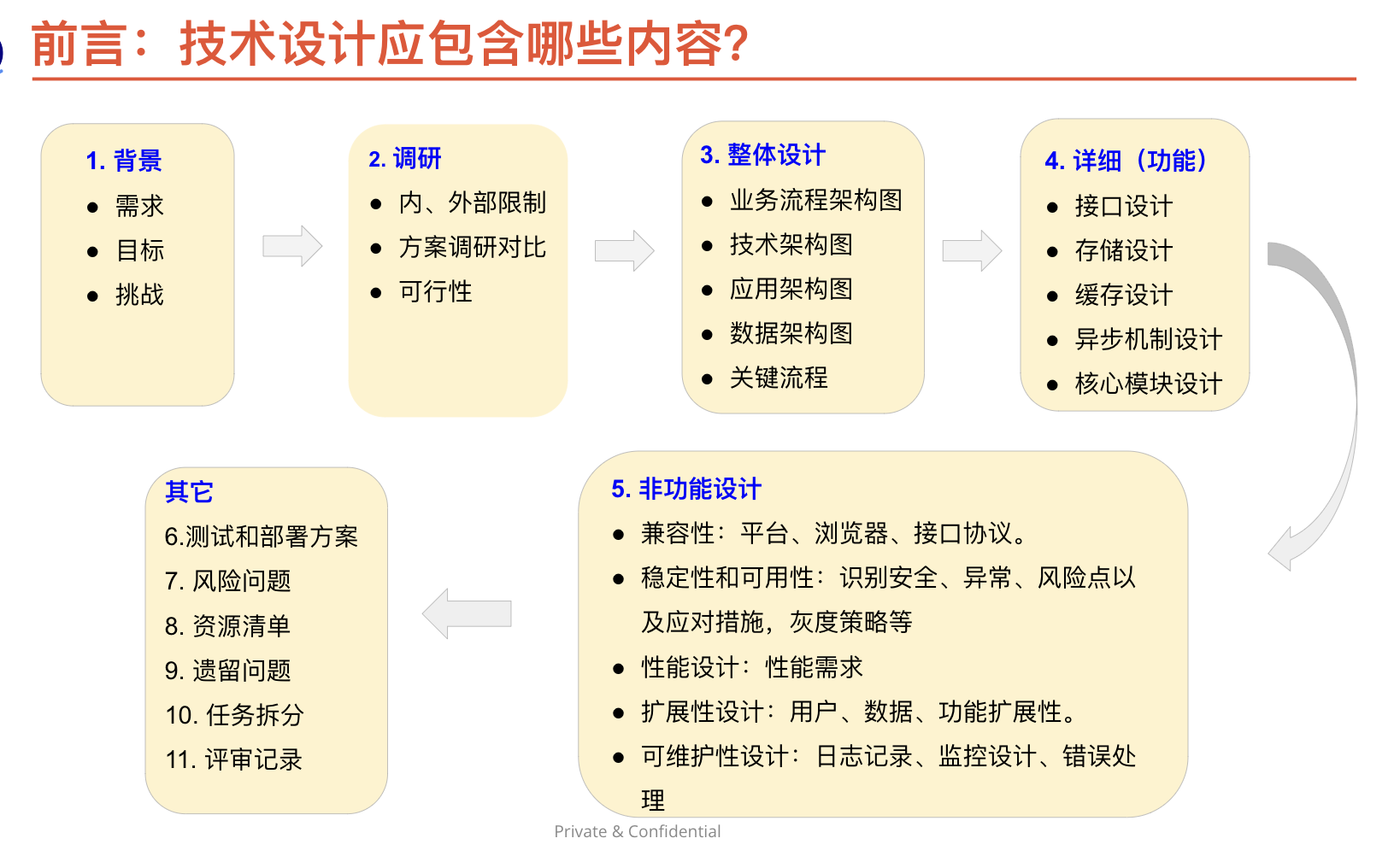

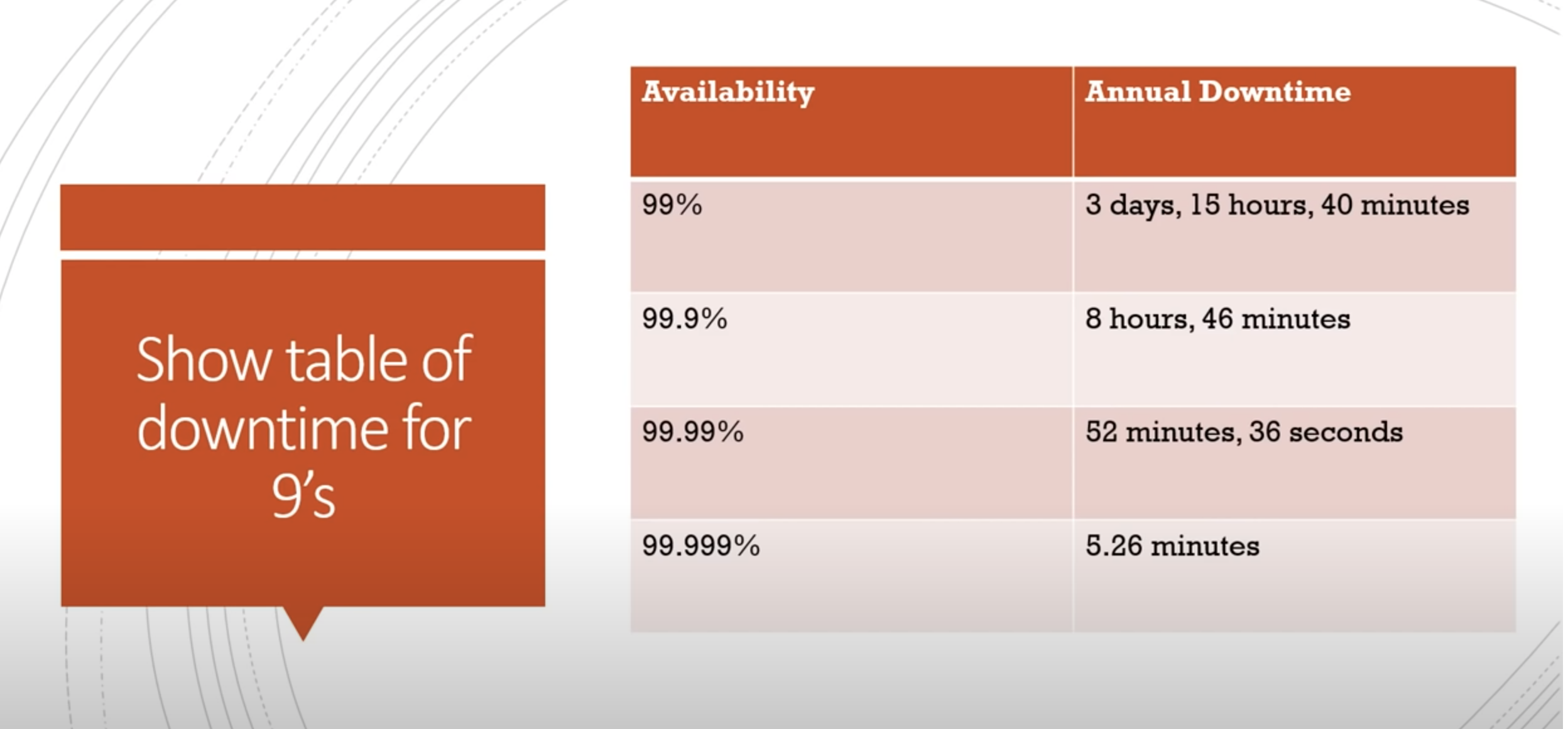















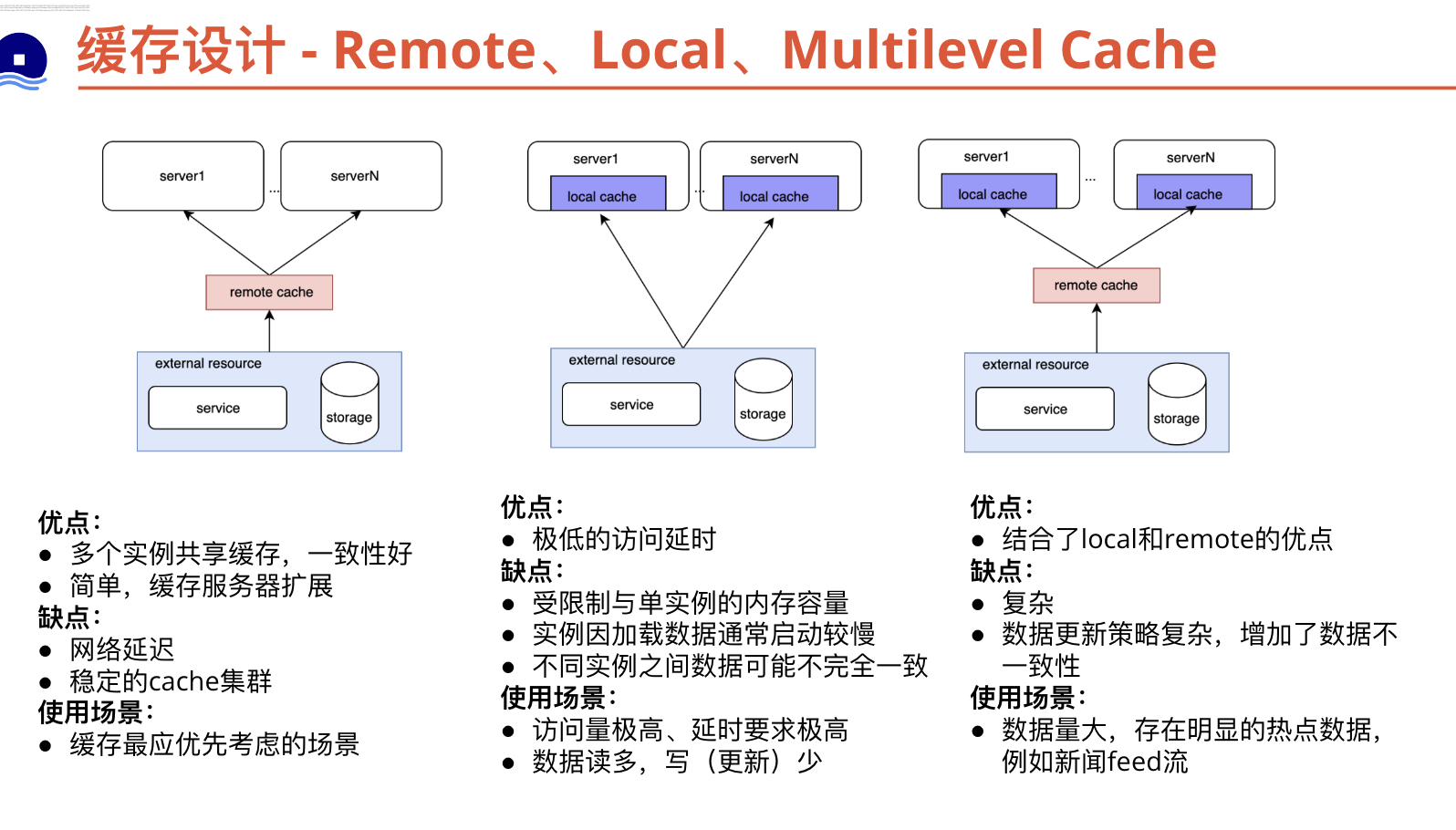
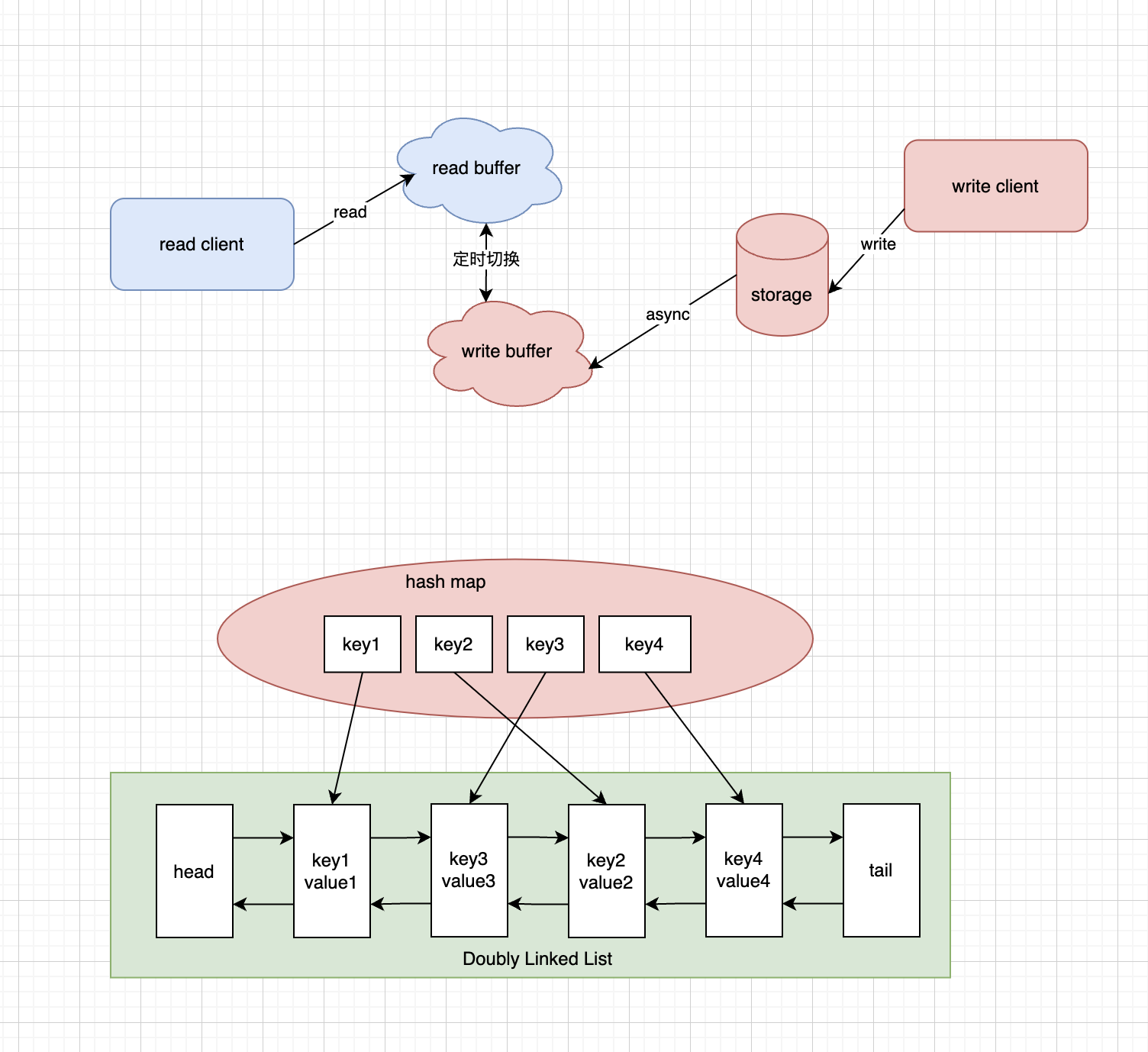
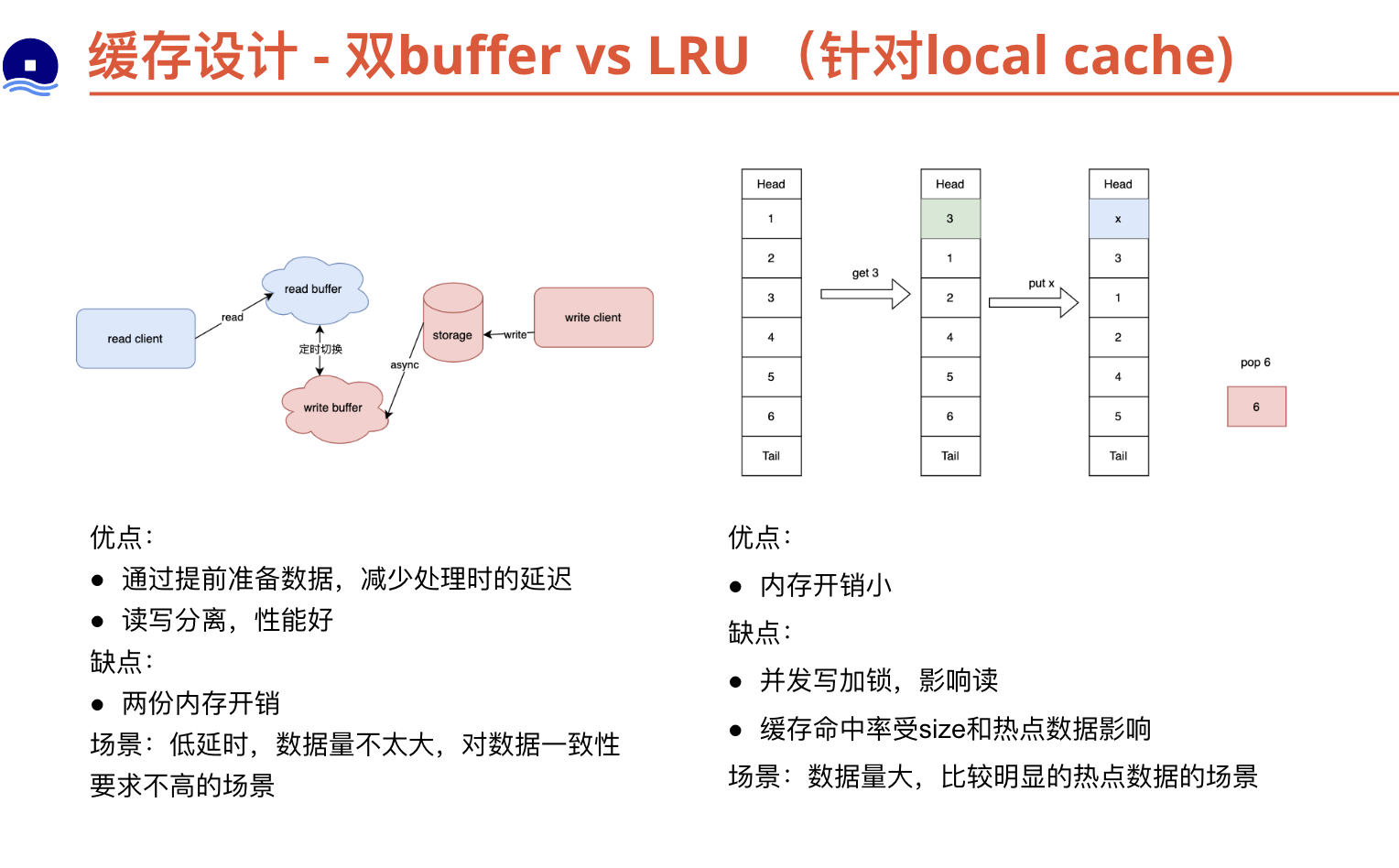
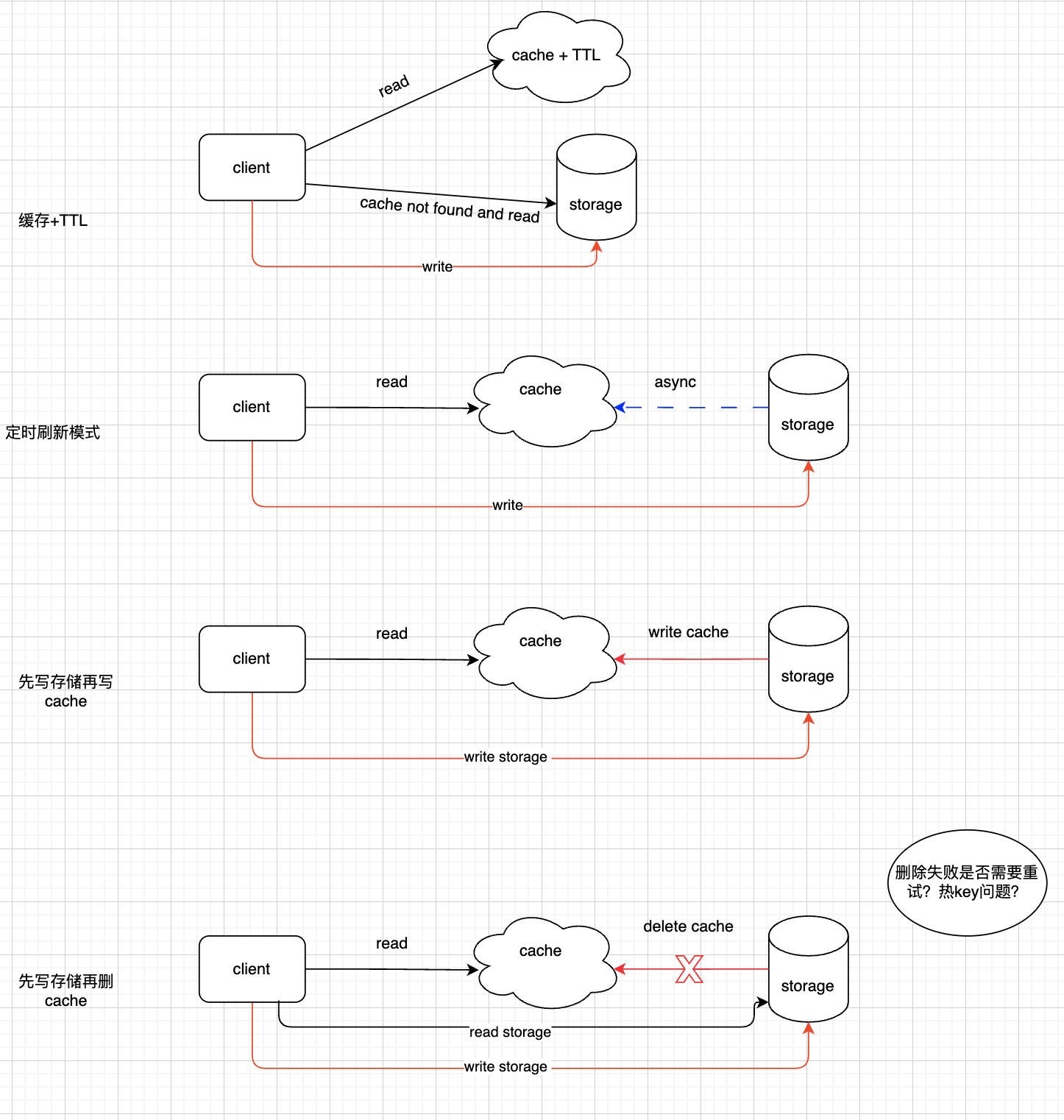
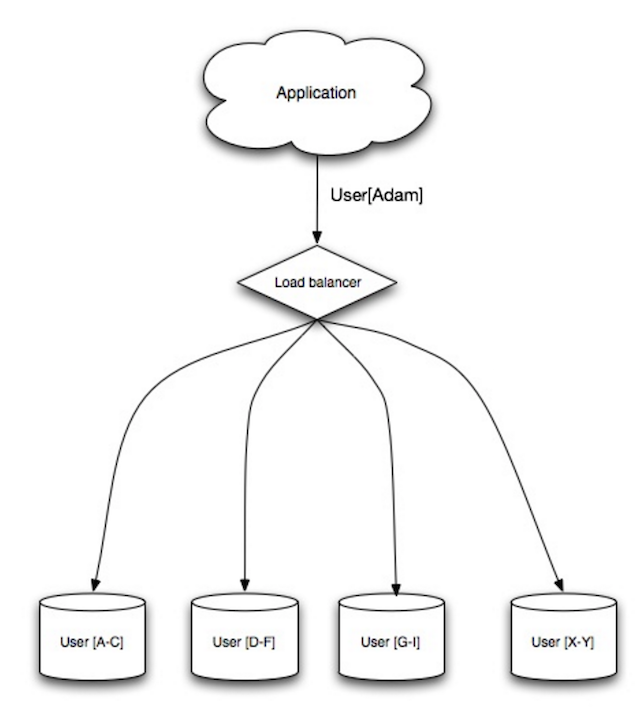
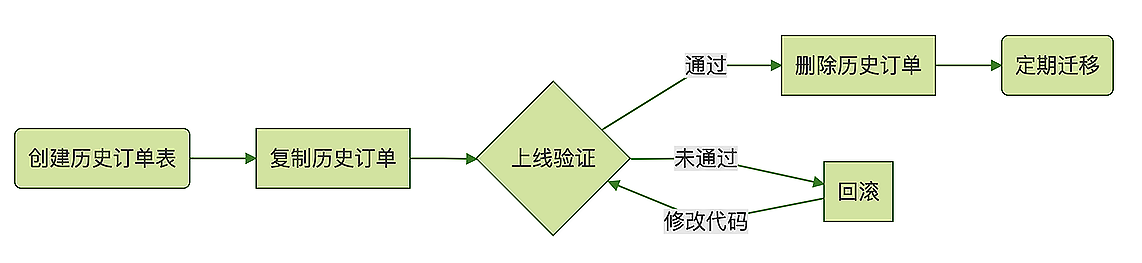
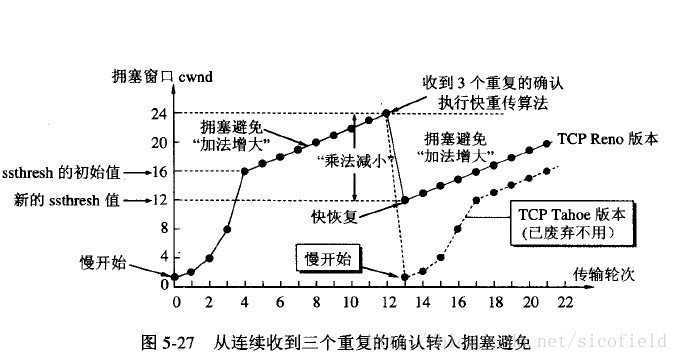
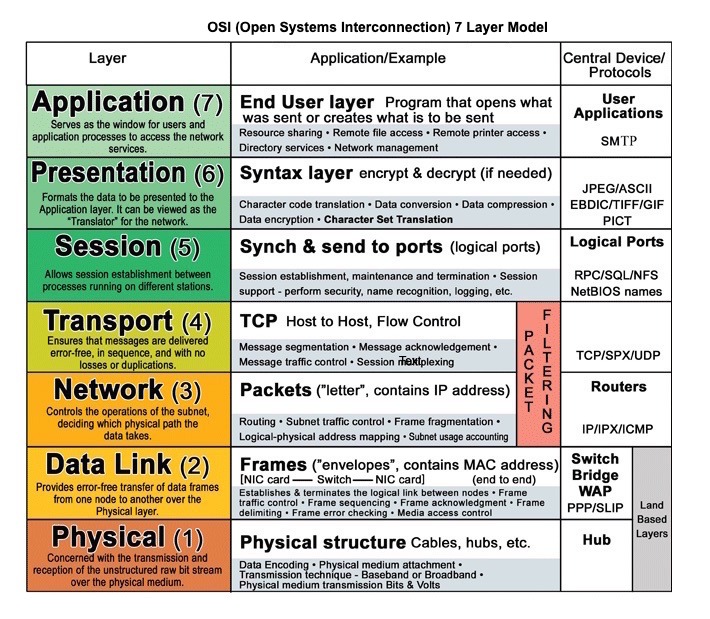

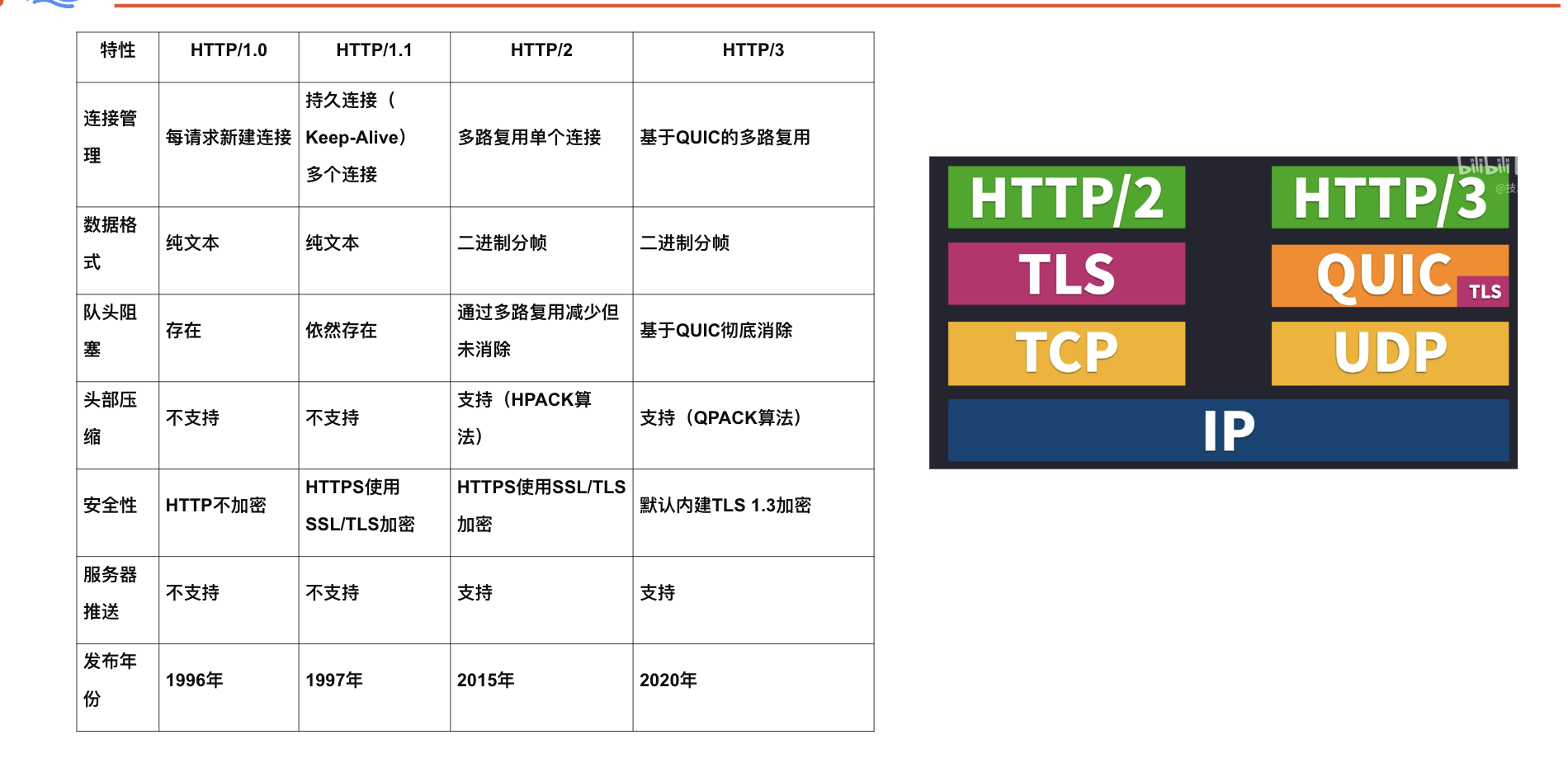
{kind=link}